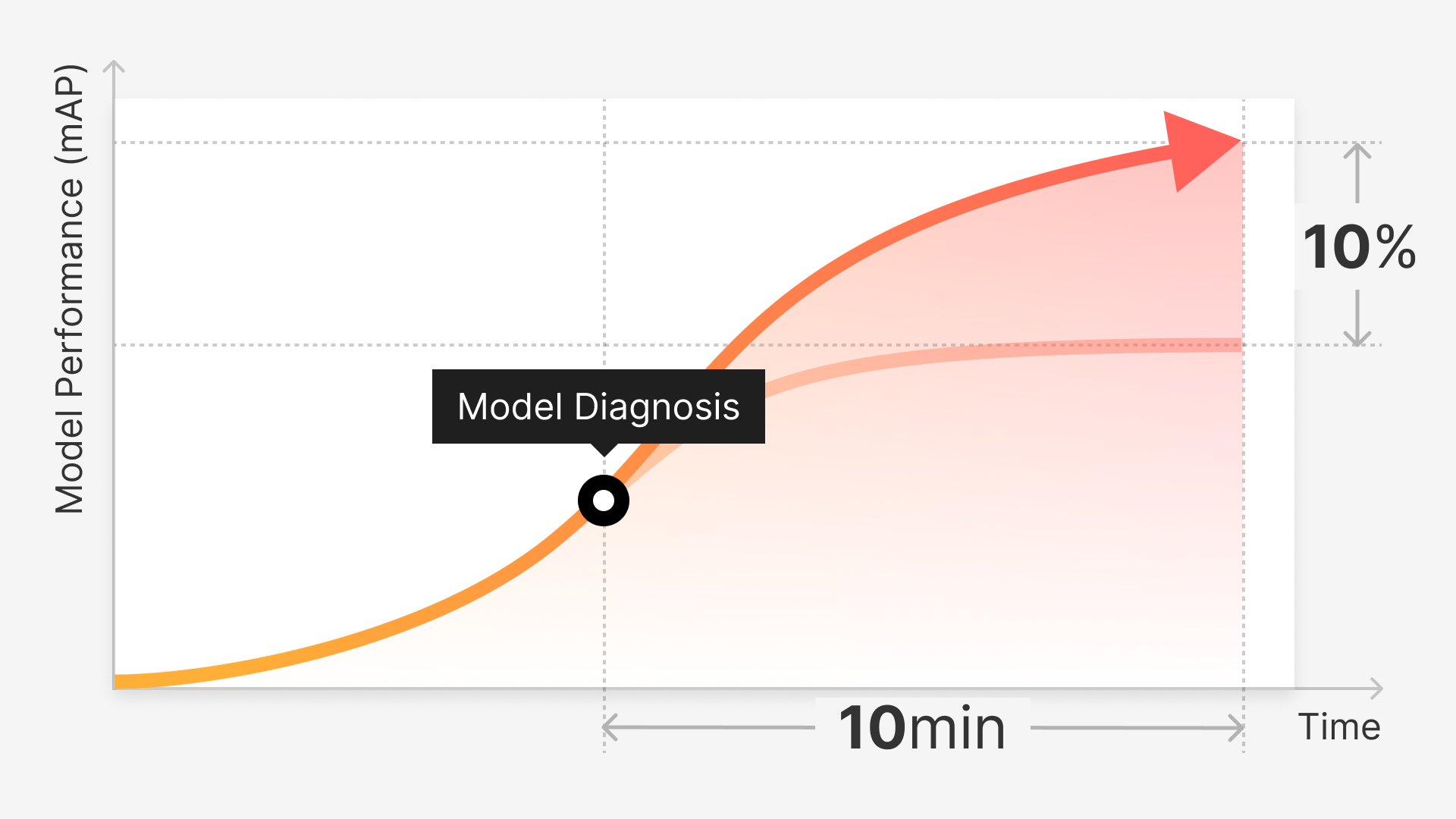
Video annotation provides a lot of value as a visual data type, but it’s also one of the most notoriously complex, with its own unique challenges to process for model training purposes and providing clear input variables through precise and clearly labeled datapoints. Read on to discover the best practice methods for simplifying video annotation efforts and getting the most value out of each single frame for your computer vision (CV) project needs.
Every data labeling team faces the essential question of what type of data to use for their specific use case. In this article, we’ll be looking back at standard techniques used for video data annotation, then at contemporary methods utilizing automation tools and platforms, before breaking down the most common issues data labeling teams face when annotating videos and best practices to address those issues head-on.
We will cover:
What is Video Data?
Past and Current Approaches to Video Annotation
Best Practice Methods for Annotating Video Data
How To Address Low Quality Video Data
Essential Tips To Ensure High Quality Video Annotations
What Makes Video the Best Data Type for Rich Context
The Nature of Video Data
Image Versus Video Annotation
When referring to either image or video annotation it’s understandable if they’re grouped together as being similar. After all, they both serve the same purpose when it comes to the broader machine learning development cycle; as both concepts are used during the same initial stage of curating data for AI applications and systems.
They also share basic best practice processes that the average labeling team follows as a standard: gathering a large amount of data for the purpose of training, identifying objects within those datasets, labeling them appropriately and precisely, and ultimately producing accurate guidelines that will enable ML models to perform correctly once deployed.
Taking a closer look at the two terms, however, reveals some variance in the specific annotation techniques they tend to utilize and favor over others. Video data for instance, has the potential to offer more realistic insights than images because they track and clarify motion in real-world environments, through the video footage itself or frames.
Image data on the other hand, doesn't have this ability; since objects are stationary and can only be labeled as such within them. For that reason, video is a standout preference for projects that would benefit from data that features moving objects that a model should recognize and respond to accordingly in an active environment.
In this article, we'll be laying out the major techniques associated with video annotation processes, how to best leverage these methods to derive meaningful insights from them, and the unique benefits it provides the end-to-end ML workflow as a distinct data annotation type.
Video Annotation Approaches
The Foundations of Video Annotation
As far as video annotation is concerned, there are two particular methods that are most widely recognized and employed: the single image method and the continuous frame method; which is also commonly called the multi-frame or streamed approach.
The single frame method is considered a more traditionalist technique, that annotators depended on before market-ready automation tools or products were available, while the continuous frame method has grown in popularity in recent years, in part, because of its integration with automated tools and annotation frameworks.
Single Image Annotation
The traditional method of video annotation, which was commonly utilized in the ML industry before the option of automating and effectively optimizing the standard practice, is referred to as the single image (or frame) method. Despite the approach not being the most efficient or considerate of resources and expense, it got the job done as you might say.
The method involves two rather predictable steps: extracting the frames from the video data, then annotating each of the frames as images, following the conventional image annotation techniques. This process was flawed and undeniably simplistic; so much so that it was to its detriment as an industry-wide standard.
For that reason perhaps, the method has gained a reputation for being outdated or overly complicating the video annotation process. Though presently labeling teams still rely on it from time to time, particularly when attention to detail is important when working on niche projects or larger-scale applications.
Continuous Frame Annotation
The continuous frame method is implemented by annotating video data as a stream of frames, prioritizing the integrity of the flow of information that is being captured and identified. This method is also usually mentioned alongside automation technology, as the information continuity and flow across frames can be better maintained that way.
However, even automations require certain techniques to properly assess each frame, like optical flow, which eases the act of identifying objects at the start of a video that vanishes and reappears later on in the footage. This leads to a noticeable difference from the single image method, when reoccurring objects may be mistaken as multiple when they should count as one.
A Look at Video Annotation Best Practices
Although video annotation is heralded for its ability and significant advantage of capturing motion over image data, it's also notoriously more difficult to process. Labeling teams not only need to identify the contents within video data, but track and synchronize the objects with consistency in mind from one frame to another - ensuring that the objects aren't mislabeled in subsequent frames.
Fortunately, there are now emerging solutions that automatize significant components of the annotation process; allowing for segments of video to be labeled accurately and with fairly minimal human intervention.
Continue reading to learn about practical solutions to simplify a video annotation process that might appear more cumbersome and complex than its individual advantages over other annotation types is worth.
The Right Tools
When annotating any video footage, regardless of the application or use case it's meant for, the first thing to keep in mind are the tools at a team's disposal to speed up the basic annotation tasks. Since the single frame method referenced earlier in this article is inspired if not duplicative of manual image annotation practices, the inefficiencies of those practices are also transferred over to the video category.
With the right annotation tools, the time-consuming routine of annotating individual frames can be entrusted to auto-labeling AI; which completes routine labeling tasks in less time and without the usual grunt work required by human labelers.
Auto-labeling functions can tap into techniques that cut down on processing time even further by simply annotating the start and end of sequences and applying interpolation, a means of automatically calculating the size and position change between keyframes.

Selecting an Object Detection Technique
There are certain object detection techniques that are common to video annotation. Some are basic and familiar, such as bounding boxes, polygons and keypoints, while one could stand out as more rare and of specialized use to the data type, like 3D cuboids.
Choosing the correct object detection technique plays an important part in the versatility of the annotation tools available to labeling teams as they address the unique content of each video and sometimes at an individual frame-level. The knowledge of customizing annotation efforts according to the project's data training requirements is crucial to process data in the most accurate way for the end product and application.
Take a look below at the breakdown of each common object detection technique and their most relevant data scenarios and content, whether it be bikers on the road properly recognized as pedestrians, or the proper shelving levels that industrial robots need to distinguish to carry out manufacturing assignments and safely navigate their surroundings.

Bounding Boxes
The most common and basic form of annotation for any data type are bounding boxes, a simple rectangular shaped box that is meant to contain an object within its frame. For video annotation purposes, a bounding box still nicely fulfills its usefulness as a generic type of annotation technique.
It's also quite versatile for this reason and easy to fall back on when labeling a variety of different objects; as long as there isn't concern that background elements of a video or image aren't interfering with the data details.
To sum it up, bounding boxes are best used as a multi-purpose detection tool, specifically any objects considered commonplace that a model will likely come across and need to recognize from a cursory and shallow extent. Such as cars, pets, human figures, and physical structures like buildings.
Polygons
In contrast to bounding boxes, who are sufficient for a wide range of objects that are simple and common, polygons were literally made for irregularly shaped ones. Typically, a polygon is close-shaped and consists of a set of line segments which are connected.
Polygons are flexible, notably more so than bounding boxes, and adaptable, enabling labelers to shape them in a complex manner and annotate more difficult or unconventional objects in video data.
Another feature of the polygon technique, which is offered through the Superb AI Suite, is the "union function." Which is designed to make annotating overlapping objects easier. Furthermore, the "subtract function" comes in handy when segmenting objects with unique features like holes.
Keypoint
The keypoint technique happens to be one that provides a boost of value for video annotations in particular. Since a primary objective of annotating video data is focused on tracking an object that is "moving" between frames. As keypoints are used to mark essential "points" within the shape of an object, they're ideal for tracking the specific content within individual objects and how they shift position.
To assist labelers track movement even more precisely in video data, keypoint skeletons are another concept that is frequently employed. For example, if a model needs to be trained to analyze the movements of a person playing a sport, a keypoint skeleton can be created; a series of interconnected "points" that profile the figure of a human according to its poses while playing the specific sport. In that way, annotations of movement can be tracked even more tightly.
Cuboids
Cuboids, as mentioned earlier in this article, are used in the context of video labeling to annotate objects in three-dimensional space. This annotation technique makes it possible for annotators to define the size, orientation, and overall position specifics of an object within frames. It's predictably best well-suited to annotating objects that are textured through dimensional levels, like buildings or furniture.

Addressing Problematic Frame Content
An added complication to video annotation is visibility. Due to the nature of video content, active and in constant mid-motion, it greatly benefits from measures to access and create the pixel-precise points for accurate annotations.
The Superb AI Suite does just that - automatically surfacing issues detected and tagged by your team in, making the attempt to pinpoint those visibility issues easier to return to and resolve. The platform also has "visibility modes" assigned to keypoint annotations to help labelers separate and apply the exact points they need: visible, invisible (but labeled), and invisible points.
Quality Checks
The essential steps to annotating video with contemporary best practices in mind, comes down to choosing the right tools and platform, uploading the video footage, labeling as necessary manually and running an auto-annotation function to expedite the process.
It's easy enough when laid out as a list, but the most important practice that applies to any annotation workflow, regardless of the type of data or how much or little of it there is, will always be a thorough QA procedure.
It doesn't make much sense to get so far as to gathering the data you need, go through the trouble of processing it, then realizing it's flawed because there wasn't a label quality review step in place, it's even more irking when the issues could have been easily prevented or promptly corrected if actually noticed at the time they occurred or soon after.
Don't be the team that suffers from data problems during model development or even in production, especially from preventable errors, which may seem insignificant early on following deployment, but more severe once a model spends some time in a real-world environment.
Don't bypass or neglect QA in your data annotation pipeline and face the dire consequences of a poorly performing application; through the Superb Suite's integrated QA functionality, it's never been easier for data labeling administrators and managers to monitor and address labeling issues as they arise.
Make requests to specific labelers or team members to correct or review issues, utilize comprehensive filters and search functions to quickly locate and review segments or groupings of labels within larger datasets, and more using our data and project management features.
Conclusion
The Best Annotation Type for Real-World Context
Why video annotation you ask? The easy and most obvious answer would be what was cited in the introduction of this article, it's simply the better choice for the sake of context. Training a model on how to perceive and respond to its environment in a live setting doesn't get more real than what hyper-realistic video data has to offer.
Suppose the main goal of annotating data is to derive as much value from it as possible, as much information as possible to ease the repetitive effort of training a model on what it can expect out in the real world. In that case, video data fulfills that criteria and more.
Maybe in the past, when ML teams were limited to single-image approaches to processing video data it could have been too burdensome to take on; regardless of how much insight it could deliver compared to other data types, but that's no longer the case.
Through auto-generated annotation technologies, the once intimidating prospect of annotating what can easily amount to thousands upon thousands of video footage frames will be a walk in the park in comparison. With a good grasp of the basics and a little help from the right tools, it will be no time before video annotations are anything but complex.