
Auto-Label: Part 1. Suite의 오토라벨 기술 들여다보기


**본 글은 Superb AI의 김계현 CRO(Chief Research Officer)가 작성한 ‘Auto-Labeling: Part 1. Introduction to Superb AI’s Auto-Labeling Tech’의 번역본입니다.
오토라벨은 데이터 라벨링의 생산성을 최대 10배까지 향상시킬 수 있는 라벨링 자동화 기술입니다. 이번 블로그 시리즈에서는 Superb AI Suite의 주요 기술인 오토라벨에 대해 소개하고, 오토라벨에 적용된 기술이 실제로 어떻게 생산성 향상에 기여할 수 있는지를 살펴보려고 합니다. 우리는 이 오토라벨 기술이 향후 인공지능 시스템을 개발하는 데 큰 변화를를 가져올 것이라고 믿고 있습니다.
Part 1은 오토라벨링 프레임워크와 대략적인 R&D 마일스톤에 대해 다룹니다. 먼저 100% 매뉴얼 라벨링 워크플로우가 어떻게 진행되는지 살펴보겠습니다.
I. 매뉴얼 데이터 라벨링
가장 일반적이고 간단한 데이터 라벨링 방법은 사람이 수동으로 하는 것입니다. 라벨러는 정해진 규칙을 따라 원본데이터(이미지 또는 비디오)를 라벨링하게 됩니다.
이미지 데이터를 라벨링할 때 가장 흔한 어노테이션 타입은 Classification Tag, 바운딩 박스, 폴리곤 세그멘테이션, 키포인트 입니다.
몇 초 이내로 생성할 수 있는 Classification tag는 가장 쉽고 빠른 어노테이션 방법인데 반해, 폴리곤 세그멘테이션은 하나를 완성하는데만 해도 몇 분이 소요됩니다. 그럼 매뉴얼 라벨링으로만 작업할 때와 오토라벨링으로 작업할 때 얼마나 큰 시간 차이가 발생할까요?
일반적인 데이터셋은 이미지를 10만개 정도 포함하며, 각 이미지에는 평균적으로 5개의 오브젝트가 있습니다. 그리고 오브젝트에 바운딩 박스를 하나 그리는데에는 10초가 소요된다고 가정해봅시다. 이 경우 매뉴얼 라벨링으로 진행할 때 약 1,500시간이 걸리며, 데이터 라벨링 비용으로만 약 1억 원을 지출하게 됩니다.
품질 관리 단계(데이터 라벨링 결과를 사람이 직접 확인하는 단계)를 추가하면 소요시간은 더 늘어나게 됩니다. 검수자가 1개의 바운딩 박스를 확인하는데 1초가 걸린다고 하면, 라벨링 비용은 10% 증가합니다. 이 때 컨센서스 기반(여러 라벨러가 같은 데이터를 라벨링하고, 그 결과를 합치거나 비교하는 방법으로 품질을 확인하는 방법)으로 품질 관리를 할 수 도 있는데요, 이렇게 하면 소요시간과 비용은 컨센서스 라벨러의 수에 비례하여 증가하게 됩니다. 3명의 라벨러가 같은 이미지를 각각 라벨링했다면, 비용을 x3 만큼 지불해야 하는 것입니다.
지금까지 말씀드린 내용을 이해하셨다면, ‘데이터 라벨링’과 품질 관리를 위한 ‘검수 및 수정’이 데이터 라벨링 시 가장 많은 비용을 지출하게 되는 두 단계라는 것을 알게 되셨을 텐데요. 때문에 오토라벨링은 라벨링과 결과 검수에 쓰이는 시간을 줄이는 것을 주된 목표로 삼아야 합니다.
다행히 인공지능과 머신러닝의 발전과 함께 오토라벨링 기술도 크게 발전했습니다. 하지만 모든 오토라벨링 기술이 똑같이 만들어지는 것은 아니며, AI를 서툴게 적용한 경우 오히려 AI가 만든 오류를 수정하는데 더 많은 시간을 써야 할수도 있습니다. 따라서, 적용된 AI 기술이 데이터 워크플로우의 어떻게 영향을 주는지 자세히 알고 있어야 합니다.
이제 슈퍼브에이아이의 오토라벨링의 정확도 및 목적과 함께, 이 기술이 인공지능 산업에서 어떤 변화를 이끌어내고 있는지 살펴보겠습니다.
II. 데이터 라벨링 자동화
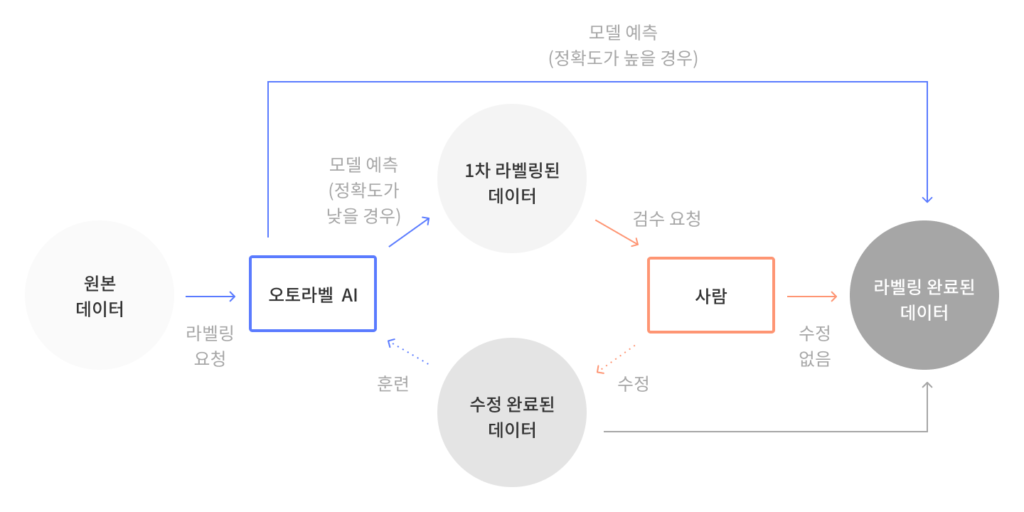
먼저 오토라벨링이 어떻게 라벨링 소요시간을 줄여주는지 알아봅시다. 먼저 데이터 라벨링 워크플로우는 다음과 같이 진행됩니다.
- 오토라벨링이 라벨링 되지 않은 원본 데이터를 자동으로 라벨링 해줍니다
- 사람이 오토라벨링 작업에 대한 검수를 진행합니다
- 오토라벨링이 데이터 라벨링을 제대로 수행한 경우, 이 결과값이 ‘라벨링이 된 학습용 데이터 집합(pool of labeled training data)에 추가됩니다.
- 오토라벨링이 작업을 올바로 수행하지 못한 경우, 수정된 결과값이 오토라벨링 인공지능을 다시 학습 시키기 위해 활용됩니다.
- 머신러닝 팀은 이 데이터셋을 다양한 모델 학습에 사용합니다.
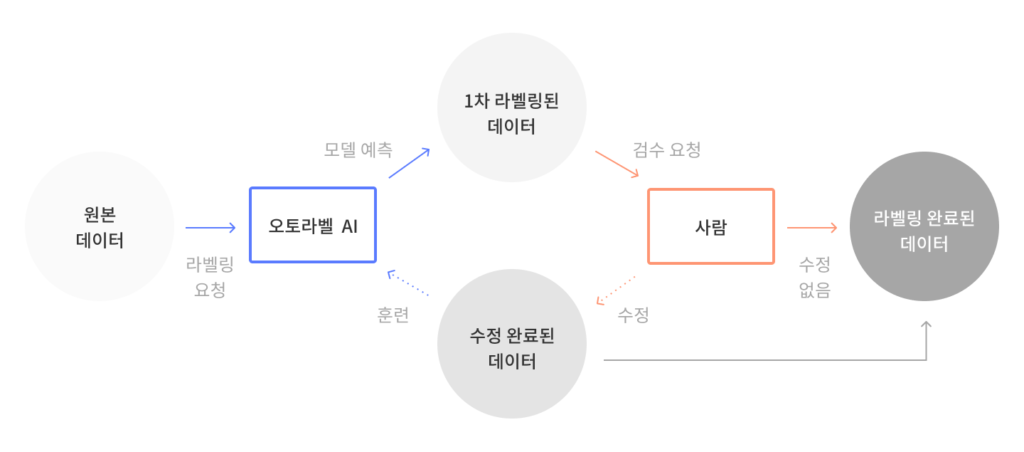
잘 훈련된 AI 모델이 활용되고 있다고 가정했을 때, 모델 예측은 당연히 정확해야하며 엣지 케이스(edge-cases)만 사람의 수정이 필요해야 합니다.
자율주행 AI와 같은 방대한 양의 데이터가 필요한 경우에도, 대부분의 일반적인 데이터들은 모델 성능을 향상시키는 데 한계가 있습니다. 모델의 성능 향상에 도움을 주는 것은 희귀한 엣지 케이스 데이터들로, 자율주행의 경우 일반적인 주행 영상이 아닌 사고 영상들이 이에 해당합니다.
따라서, 회사가 가장 정확하고 성능이 뛰어난 AI 모델을 개발하려면 단순하게 큰 데이터셋이 중요한 것이 아니라, 모델을 훈련시킬 엣지 케이스들을 많이 찾고 수집하는 것입니다. AI 모델이 이미 잘 훈련된 사소한 데이터 사례를 걸러내고, 엣지 케이스와 같은 중요한 데이터에 라벨링을 하거나 수정하는데 시간을 투자하는 것이 가장 중요합니다.
2-1) 데이터 라벨링 자동화의 효과
아래 표에서 오토라벨링을 사용해 데이터를 라벨링하는 경우 얼마나 시간을 단축시킬 수 있는지 확인할 수 있습니다.
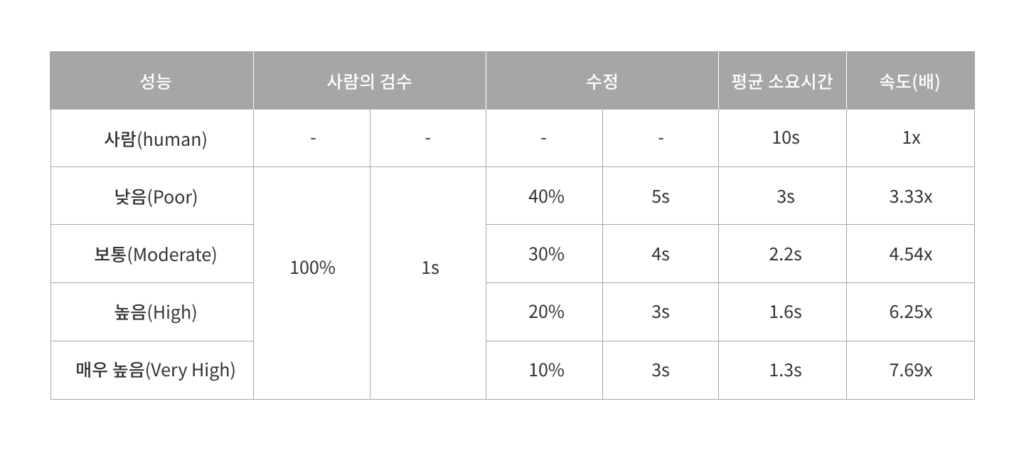
위에서 언급한 바와 같이, 일반적인 바운딩 박스 어노테이션을 라벨링하는데에는 10초, 확인하는 데는 1초가 걸립니다. 또한 오류의 종류에 따라 어노테이션을 수정하는데 약 2~10초, 평균적으로는 3~5초가 소요됩니다. 그리고 수정이 필요한 바운딩 박스의 비율에 따라 AI 모델 성능을 ‘낮음’, ‘보통’, ‘높음’ 및 ‘매우 높음’으로 나눌 수 있습니다.
실험에 따르면, 사람이 AI 모델의 작업 결과 중 40%를 수정해야 하는 ‘Poorly(불량)’ 등급의 경우에도 라벨링 속도가 3배 이상 향상되었습니다. 성능이 ‘High(높음)’인 경우에는 20%를 사람이 수정해야 하는데, 이 때에도 속도가 6배 이상 빨라졌고, 총 비용의 80% 이상을 절약할 수 있었습니다.
2-2) 오류 유형과 그에 따른 수정 방법
오토라벨링 성능이 향상될 때 라벨링을 검수하는 시간이 줄어드는 이유는 무엇일까요? 데이터 라벨링 작업 중에 발생하는 4가지의 오류 유형에서 그 이유를 찾아볼 수 있습니다.
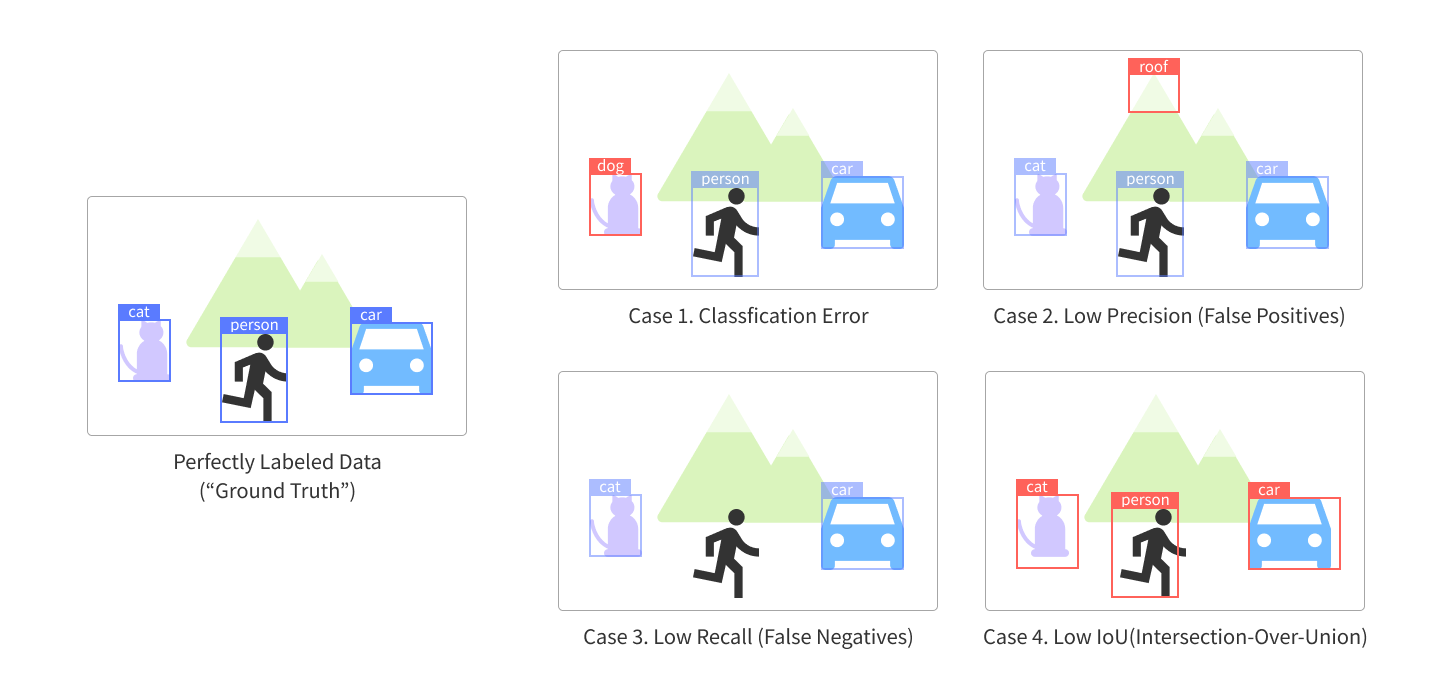
유형 1. Classification Error
Object Class를 잘못 지정한 경우입니다. 가령 Object는 고양이인데, Object class를 개로 표기하는 경우가 대표적이죠. 이 경우, Class를 살짝 수정해주면 에러를 해결할 수 있습니다. 보통 라벨 한 개를 수정할 때 2초 정도가 소요됩니다.
유형 2. Low Precision (False Positives)
오토라벨링의 정밀도(precision)가 낮아서, 라벨링하지 않아도 될 것에 라벨을 달아주는 경우가 발생할 수 있습니다. 그림 2와 같이 ‘산’에 라벨링을 할 필요가 없는데도 불구하고, 산의 윗 부분을 지붕이라고 인식해서 불필요한 라벨을 달아주는 것이죠. 이 경우 해당 라벨을 삭제하여 수정할 수 있습니다. 이 케이스의 라벨 작업을 수정하는데에는 2초가 소요됩니다.
유형 3. Low Recall (False Negatives)
재현율이 낮은 경우입니다. 오토라벨링이 Object를 발견조차 하지 못해서, 라벨링이 필요한 경우임에도 이를 놓치는 경우가 발생할 수 있습니다. 그림 3과 같이 라벨링이 되어야 하는 ‘사람’을 아예 놓쳐버린 케이스입니다. 이런 경우는 검수하는 사람이 직접 바운딩 박스를 그리고, 라벨을 달아야 하기 때문에 앞선 경우보다는 시간이 더 필요합니다. 한 개의 라벨을 수정하는데 약 10초가 소요됩니다.
유형 4. Low IoU
라벨링 결과가 Object의 모양에 딱 맞지 않게 된 경우입니다. 이 경우는 사람이 직접 위치나 형태 등을 조정해줘야 합니다. 이 경우에도 한 개의 라벨을 수정하는데 약 10초가 소요됩니다.
위에서 볼 수 있듯, 수정에 가장 많은 시간이 걸리는 오류 유형은 3번 ‘Low Recall’과 4번 ‘Low IoU’입니다. 3번의 경우 라벨러가 아예 새로운 바운딩박스를 그리는데 평균 10초가 소요되며, 4번에서 오브젝트에 맞게 바운딩 박스 좌표를 다시 조정하는데 걸리는 시간과 거의 비슷합니다. 반대로 오브젝트 클래스를 변경하거나(유형 1), 잘못된 바운딩 박스를 삭제하는데는 2초 정도 소요됩니다.
이처럼 발생하는 오류의 종류에 따라, 사람이 검수한 다음 수정에 필요한 시간도 달라집니다. 이 때문에 Superb AI는 3번, 4번 유형의 오류를 줄일 수 있도록 AI의 재현율과 IoU 측정에 관한 연구에 집중해 왔습니다. 이 결과로,
- 사람이 검수를 해야 하는 작업의 개수를 줄일 수 있고
- 검수 시간이 더 많이 필요한 유형의 에러 발생 비율을 줄여서, 검수 1건당 소요되는 시간을 줄이고 있습니다.
III. 더 고도화되는 오토라벨링
지금까지 오토라벨 AI를 사용해 데이터 라벨링을 자동화하고, 라벨링 속도를 6배 이상 향상시킬 수 있는 방법에 대해 알아보았습니다. 이 섹션에서는 오토라벨 AI 기술을 발전시키고 있는 두 가지 주요 방향에 대해 소개하려고 합니다.
3-1) 불확실성 추정(Uncertainty Estimation) 기능을 통한 검수 시간 절약
Superb AI의 오토라벨링 기술이 특별한 이유는, 단순히 라벨링 결과값만 제시하는 것이 아니라 라벨링 결과의 정확도를 함께 예측할 수 있기 때문입니다. 우리는 오토라벨 AI가 라벨링 결과에 대해 얼마나 확신하는지 측정할 수 있는 ‘불확실성 추정’ 기능을 독점적으로 개발하였습니다.
다시 말해, Superb AI Suite의 오토라벨링은 ▲ 전체 데이터에 대해 자동으로 라벨링을 수행하는 단계 ▲라벨링 작업의 난이도를 계산하여, 사람의 검수가 필요한 작업을 판단하여 사람에게 검수를 요청하는 단계, 총 두 단계로 작동합니다. 이를 통해 어노테이션이 확실하지 않은 경우에만 AI가 사람의 검수를 요청하고, 이는 결과적으로 검수에 소요되는 작업량을 줄입니다.
아래 도표를 보면, Auto-label AI로 들어간 데이터가 모델의 불확실성 추정 결과를 기반으로 ‘certain’, ‘uncertain’으로 분류됩니다. 라벨러는 ‘certain’으로 분류된 데이터는 검수하지 않고, ‘uncertain’으로 분류된 소수의 라벨을 확인하는데에 집중할 수 있습니다. 라벨러가 확인해야 하는 데이터의 수가 적어지므로, 라벨링 비용이 감소하게 됩니다.
아래 표는 불확실성 추정 기술이 데이터 라벨링 효율성에 미치는 영향을 보여줍니다.
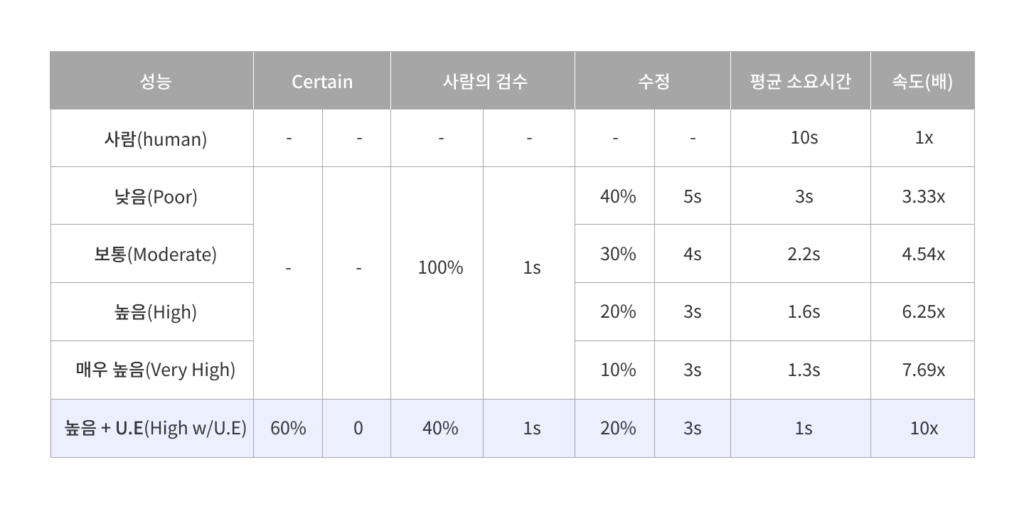
우리는 불확실성 추정 기술을 ‘높음’ 등급의 정확도로 AI 모델에 적용했습니다. 만약 불확실성 추정 기술이 포함되지 않은 단순 오토라벨 AI를 사용한다면, 라벨러들은 모든 데이터를 검수해야 합니다. 하지만 불확실성 추정 기능이 탑재되면서 오토라벨 AI가 60%의 라벨을 ‘certain’하다고 분류했고, 라벨러는 나머지 40%의 데이터만 검토해도 무방하게 되었습니다. (또한, 사람의 검수가 필요하여 ‘uncertain’으로 분류된 경우의 절반, 즉 전체의 20% 정도만 실제로 사람이 수정이 필요했고, 이는 불확실성 추정 기술이 사용되지 않는 사례와 비슷한 수준입니다) 이 경우 10배의 속도 향상을 달성할 수 있었으며, 이는 '매우 높음' 등급 오토라벨 AI의 7.69배보다 오히려 높은 속도였습니다.
이처럼, 사람의 검수를 줄이기 위해 불확실성 추정 기능을 사용하는 것은 Superb AI의 오토라벨 기술의 주요 부분입니다. 현재는 베이지안 액티브러닝(BaaL) 프레임워크를 사용해서 개발 중이며, 이에 대해서는 다음 포스팅에서도 자세히 다뤄보겠습니다.
3-2) 데이터가 적을 때 오토라벨 AI 적용하기 (a.k.a 콜드 스타트 문제 해결)
오토라벨 AI를 발전시키는 또 다른 방법은, 기존의 오토라벨 AI 모델을 적은 양의 데이터를 사용하여 새로운 작업에 적용시켜보는 것입니다.
‘사람’ 또는 ‘자동차’와 같은 오브젝트 클래스에 바운딩 박스를 그리는 일반적인 라벨링 작업 외에도, 다양한 오브젝트 클래스, 데이터 도메인 및 라벨링 작업이 있습니다. 일반적으로 새로운 오브젝트 클래스 세트, 데이터 도메인 또는 라벨링 작업에서 오토라벨 AI를 훈련하려면 라벨링된 데이터가 상당히 많이 필요하며, 그때까지는 매뉴얼 데이터 라벨링에 의존해야 합니다.
예를 들어, pre-trained 오토라벨 AI는 어느 공장에서 생산되는 제품의 특수한 부품 이미지를 처음 마주했을때, 바로 정확하게 라벨링할 수 없을 것입니다. 해당 부품 이미지 데이터를 학습한 적이 없기 때문입니다. 해당 데이터도 라벨링할 수 있도록 모델을 fine-tuning 하려면, 부품의 이미지를 많이 모아 라벨링을 하는 작업이 필요합니다. 이를 ‘콜드 스타트 문제(Cold-start problem)’이라고 합니다.
Superb AI는 이와 같은 콜드 스타트 문제를 해결하고, 유저가 매우 특수한 데이터에서도 오토라벨 AI의 이점을 누릴 수 있도록, Transfer learning과 같은 기술을 적용하고, AI 모델이 적은 수의 데이터에 대해 신속하게 fine-tuning할 수 있도록 하고 있습니다. 이에 대해서는 다음 게시물에서 다뤄보겠습니다.
IV. Coming Up Next…
이번 포스팅을 통해 우리는 오토라벨 AI라는 슈퍼브에이아이의 핵심 AI 기술과 그 목적, 그리고 이 기술을 우리가 어떻게 발전시키고 있는지에 대해 설명했습니다. 다음 시리즈에서는 우리가 개발한 특정 AI 기술, Suite와의 통합 방법, 그리고 이 기술을 통해 얻을 수 있는 이점을 소개할 예정입니다.