
컴퓨터 비전 데이터에 대한 모든 것


컴퓨터 비전이란 무엇인가?
컴퓨터 비전이라는 말에 이미 ‘시각'(vision)이라는 단어가 포함되어 있어서 유추할 수 있듯이, 사람의 시각과 관련한 시스템 구조를 모방하여 컴퓨터도 물체나 상황을 식별하고 해석할 수 있도록 하는 연구 분야입니다. 컴퓨터 비전에서 다루는 데이터에는 이미지와 이미지 속 텍스트를 인지하는 영역뿐만 아니라 비디오와 3D 영상도 포함됩니다. 비디오 영상은 엄밀히 말하면 이미지(프레임)들의 합이니까요.
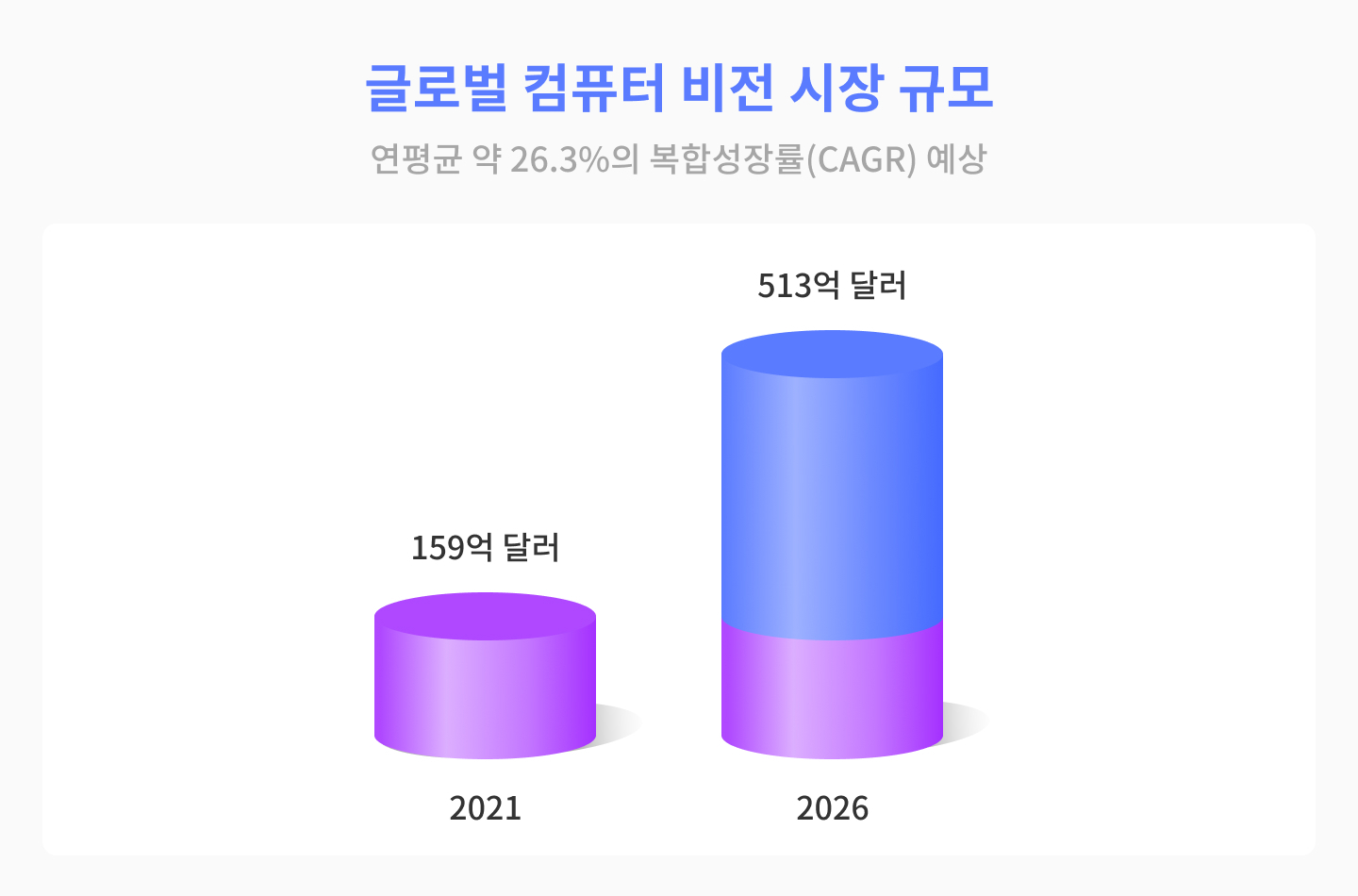
스마트폰의 시대가 오면서 이미지뿐만 아니라 영상 데이터가 폭발적으로 증가하였고 이는 컴퓨터 비전의 필요성을 증대시켰습니다. Research and Market이 발표한 자료에 의하면, 2021년 컴퓨터 비전에서의 AI 시장 규모는 159억 달러로 추정하며 2026년까지 이 시장은 513억 달러에 이를 것으로 예상했습니다. 이를 환산하면 연평균 약 26.3%의 복합성장률(CAGR)로 컴퓨터 비전 시장이 확대된다는 것을 의미합니다.
컴퓨터 비전의 기술과 활용
딥러닝과 뉴럴 네트워크의 발전은 컴퓨터 비전 분야의 발전 속도를 가속화 시키는 계기가 되었고 제한된 영역에서만 활용되던 컴퓨터 비전은 딥러닝의 심층 신경망의 비약적인 발전에 힘입어 그 활용영역을 점차 확장해나가고 있습니다. 비전 분야에 있어서 대표적인 기술은 아래와 같습니다.
- 객체 분류(Object Classification) : 이미지 속 객체를 인지하여 그 클래스를 분류해내는 기술로 컴퓨터 비전영역에서 가장 기초적인 응용 분야
- 객체 탐지 및 위치 식별 (Object Detection & Localization) : 이미지 또는 비디오 영상에서 객체를 식별해내는 기술
- 객체 분할(Object Segmentation) : 이미지 및 비디오 영상 프레임 내에서 객체를 따로 분할하여 의미 있는 부분만 분석할 수 있게 하는 기술
- 이미지 캡셔닝(Image captioning) : 이미지의 상황을 텍스트로 설명할 수 있는 기술
- 객체 추적(Object Tracking) : 비디오 영상 내의 객체의 위치 변화를 추적하는 기술로 흔히 포인트 추적(point tracking), 커널 추적(kernel tracking), 실루엣 추적 (silhouette tracking) 등의 방법을 사용
- 행동 분류(Action Classification) : 비디오 영상 내의 객체의 행동(action)을 인식하여 분류하는 기술
위에서 설명한 다양한 비전의 기술을 복합적으로 사용하여 우리의 실생활에서 다양한 비전 기술의 활용을 목격할 수 있는데요.
Brickit 앱은 이런 컴퓨터 비전 기술을 사용하여 수많은 레고 조각들을 스캔해서 재미있는 작품을 만들 수 있도록 도와줍니다. 최근 공유된 한 트윗이 무려 만 번 이상의 리트윗 기록을 남기며 화제가 되었는데요. 테크 크런치가 소개한 기사에 따르면 레고에서 공식적으로 출시한 앱은 아니고 아직은 개선할 점도 많다고 하지만, 출시 이래로 많은 사람들의 주목을 받고 있습니다. (이후 트윗이 삭제되어 아래 유투브 영상으로 대체합니다.)
Caper는 2019년 AI가 스스로 물건을 인지해서 사람들의 쇼핑경험을 돕는 AI self checkout 카트를 만들기도 했습니다. 물건을 담을 때 카트에 달린 카메라를 통해 이미지를 인식해서 정보를 저장하며 카트에 달린 카드계산기를 통해 계산대에 가지고 않고도 카트내에서 쇼핑을 끝낼 수 있는 서비스입니다.

Facebook 또한 이미지 인식 및 탐지를 통해 사용자가 찾으려는 제품을 하나의 플랫폼에서 구매할 수 있도록 돕는 AI 기술을 발표하기도 했습니다. 이렇듯 리테일 분야에서도 컴퓨터 비전의 활용이 가속화되고 있습니다.
이미지 인식 기술은 예술 분야에도 널리 퍼지고 있는데요. Apple이 인수한 Magnus라는 앱은 Shazam for art를 표방하고 있는데요. 들려주기만 하면 모든 음악을 찾아주는 Shazam 서비스처럼 카메라로 인식하면 미술작품에 대한 정보와 현재 가격까지도 알려줍니다.
컴퓨터 비전이 데이터를 다루기가 어려운 이유
과거에 비하면 컴퓨터 비전은 상당히 많이 발전하여 위에서 소개한 것처럼 실생활에서 광범위하게 사용되고 있기도 하지만, 컴퓨터 비전을 다루는 일은 여전히 어렵습니다. 대규모 인력을 과감하게 투입하여 비전으로만 자율주행의 미래를 그려가는 테슬라의 AI 디렉터인 안드레아 카파시(Andrej Karpathy)도 지난 9일 트위터에서, 4년을 매달렸지만 컴퓨터 비전을 위한 라벨링 워크플로우에 대한 명쾌한 답을 찾지 못했다고 고백하면서 컴퓨터 비전 작업의 어려움을 토로하기도 했습니다. 세계가 주목하는 컴퓨터 비전기술을 이끌어가는 안드레아가 ‘라벨링 워크플로우’ 문제를 아직도 풀지 못했다고 고백한 것은 무슨 의미일까요?
이미지나 영상 내의 객체를 라벨링 하는 것이 라벨링 작업의 전부라고 단순히 생각하기 쉽지만, 안드레아가 나열한 항목들을 보면 라벨링 워크플로우(labeling workflows)는 그보다 더 많은 작업을 수반하고 있다는 것을 알 수 있습니다. 데이터에 대한 라벨링 유형 기준 마련, 라벨링 작업 결과물에 대한 품질관리(QA) 및 피드백 수집 과정 구축, 라벨러 훈련과 퍼포먼스 측정 등을 포함하는 인력관리, 라벨링 과정 중 이슈 발생시 커뮤니케이션 비용 관리, 라벨링을 통해 구축된 데이터셋의 버전관리 등이 포함될 수 있는데요. 여기에 나열한 것은 라벨링 작업 중 예상되는 워크플로우 범위 중 일부일 뿐입니다.
여전히 이미지나 영상 데이터의 라벨링 작업은 가장 덜 중요한 것이라고 치부되고 있지만, 컴퓨터 비전 문제를 푸는 데 있어서 가장 선도적인 테슬라팀이 여전히 난항을 겪고 있는 부분이 라벨링 워크플로우라고 지적한 부분은 상용화 단계에서 컴퓨터 비전 문제를 해결하기 위해 우리가 주목해야할 부분이 사실은 데이터라고 해석할 수 있습니다.
라벨링 작업 전후에 데이터에 대한 통제권을 보장하는 제반 기능을 갖추지 않으면 라벨링 워크플로우는, 투입되는 데이터의 양이 많아질수록, 구축한 모델이 늘어날수록 여지없이 무너질 것입니다. 테슬라 조직 내에서는 이러한 작업을 외부에 맡길 수 없어서 자체팀을 구축했고 이로 인해 데이터에 대한 통제권을 내부에서 가질 수 있도록 처음부터 설계함으로써 누구보다 빠르게 비전 기술로만 상용화를 해낼 수 있었던 것이죠.
컴퓨터 비전에 있어서 이러한 데이터 문제가 특히나 어려운 이유가 무엇일까요? 두 가지로 나누어 좀 더 자세히 알아보도록 하겠습니다.
1. 사람은 이미지를 보지만 컴퓨터는 숫자를 본다
저명한 컴퓨터 비전 전문가인 UC버클리의 교수 Jitendra Malik(지텐드라 말릭)은 인공지능 전문가 Lex Fridman(렉스 프리드먼)과 진행한 인터뷰에서 사람이 이미지를 인식하는 과정이 무의식적으로 혹은 잠재 의식적으로 진행되기 때문에 흔히 컴퓨터가 비전을 처리하는 방식도 매우 쉬울 거라고 착각할 수 있다고 지적했습니다. 하지만 컴퓨터 비전의 신경과학을 들여다보면, 그 복잡성은 상상을 초월합니다. 대뇌피질의 상당 부분은 이미지 프로세싱 처리에 전념하게 되는데요. 이는 컴퓨터가 이미지를 처리하는 방식이 인간과 다르기 때문입니다. 인간이 매우 시각적이고 직관적인 방식으로 이미지를 인식하는 반면, 컴퓨터는 이미지를 그 자체로 인식하는 것이 아닌 이미지의 모든 부분을 개별 픽셀로 환산하여 숫자로 인식합니다. 이는 이미지를 인식할 때마다 처리해야 하는 데이터 양이 많다는 것을 의미하며, 컴퓨터가 복잡한 시각적 작업을 수행하도록 하는 데 필요한 계산 및 데이터 리소스 또한 방대해지는 것이죠.
2. 사람보다 더 많은 데이터를 필요로 하는 컴퓨터 비전 시스템
현재의 컴퓨터 비전 시스템이 이미지 처리에 있어서 사람과 같은 능력을 구현하려면 사람이 필요로 하는 것보다 훨씬 많은 데이터가 필요합니다. 현재 컴퓨터 비전 분야를 이끌어 가는 가장 고도화된 머신러닝 기법은 지도학습인데요. 지도학습은 ‘정답'이라고 여겨지는 피쳐를 라벨링한 데이터 기반으로 학습을 이행합니다. 최근에는 지도학습을 바탕으로 라벨링이 되지 않은 추가 인풋 데이터를 학습시키며 이러한 과정을 통해 모델의 성능을 개선해나가게 됩니다. 즉 학습에 사용된 데이터를 기반으로 모델의 성능이 결정되기 때문에, 학습에 사용된 데이터가 실제 프로덕션 레벨에서 인풋값으로 들어올 수 있는 데이터와 유사한 지가 중요한 포인트가 됩니다. 쉽게 말해서 모델이 인지하려는 모든 다양한 상황에 대해 데이터로 준비해서 학습시켜야하는 것이죠.
컴퓨터 비전을 사용하는 자율주행을 예로 들어봅시다. 자전거를 타는 사람들을 인지할 때, 컴퓨터 비전 시스템은 자전거를 타는 사람들이 어떤 행동을 하는지에 대한 사전 지식이 필요하며, 이를 바탕으로 동작해야 합니다. 하지만 실제 자전거를 타는 사람들은 제각기 다른 행동을 할 수도 있습니다. 사람의 시각시스템은 다양한 상황 속에서 이를 유연하게 인지하는 반면, 컴퓨터는 실제로 발생할 수 있는 모든 상황에 대한 데이터가 주어져야 이를 학습하여 처리합니다. 데이터를 구축하는 과정에서 얼마나 어려움이 있을지 조금은 가늠하실 수가 있을 겁니다. 실제로 이런 다양한 상황의 데이터를 모두 모아 학습 시키기는 현실적으로 쉽지 않지만, 대규모 자체 인력과 자본을 보유한 테슬라는 이러한 방식으로 자율주행 시장을 이끌고 있습니다.
컴퓨터 비전 분야에 있어서 세계적으로 저명한 학회인 CVPR 21(Conference on Computer Vision and Pattern Recognition)가 얼마 전에 열렸습니다. CVPR21에서 안드레아 카파시가 발표한 내용에 따르면, 기계가 이해하기 어려운 상황 혹은 자연스럽게 얻을 수 있는 데이터 수가 적지만 실생활에서 충분히 일어나는 상황 등을 221가지로 추려 나열한 후, 해당 케이스의 데이터를 집중적으로 확보했다고 합니다. 이렇게 흔하게 일어나지 않는 상황들을 엣지 케이스(edge case)라고 합니다. 그리고 이러한 엣지 케이스 데이터셋을 다시 테슬라의 ‘그림자 모드(shadow mode)’에서 테스트해보는 과정을 4개월 동안 7차례 반복했습니다. 그림자 모드는 말 그대로 실제 도로에서 주행하는 차에 배포하지 않은 학습 상태에 있는 모드를 의미하는데요. 현재 배포되어 있는 모드와 엣지 케이스로 학습한 그림자 모드의 성능을 비교하여 성능이 입증되면 배포를 완료하고, 새롭게 추가되는 데이터는 또다시 새롭게 생성된 그림자 모드에서 학습을 하게 되는 것이죠. 엣지 케이스를 넣어 학습을 반복하며 모델의 성능을 높이는 것은 데이터를 통해 모델의 성능을 높이는 전형적인 Data-centric(데이터 중심) 방법론입니다.

(Source: CVPR'21 Keynote by Andrej Karpathy)
따라서 비전 데이터를 다루는 문제를 풀고 있는 기업에서는 모델 성능이 일정 수준에 도달하면 이렇게 데이터를 중심으로 하는 반복사이클을 지속할 수 있는 견고한 머신러닝 데이터 플랫폼에 대한 필요성을 절감할 수 밖에 없을 것입니다.

컴퓨터 비전에서 자주 쓰이는 데이터셋
우리가 오늘날 이렇게 발전된 컴퓨터 비전의 기술들을 누리게 된 것은 데이터셋을 공개적으로 구축한 여러 오픈소스 프로젝트 덕분이라고 해도 과언이 아닙니다. 지금처럼 이미지 데이터가 충분하지 않았던 과거에 이미지나 영상 데이터의 필요성을 느끼고 데이터들을 모아 공개한 데이터셋들이 오늘날 컴퓨터 비전의 발전에 지대한 영향을 끼쳤습니다. 현재까지도 컴퓨터 비전 프로젝트에 자주 쓰이는 데이터셋을 몇 가지 소개해드리려 합니다.
- CIFAR-10
CIFAR-10 데이터셋은 머신러닝 연구에 가장 활발히 사용되는 데이터셋으로, 2009년에 제프리 힌튼 교수팀이 만들었습니다. 10개의 클래스(airplane, automobile, bird, cat, deer, dog, frog, horse, ship, truck)로 이루어진 6만 개의 이미지 데이터셋입니다.

CIFAR-10 데이터셋 예시
- Fashion MNIST
손글씨 우편번호를 빠르게 읽기 위해 우편봉투로부터 숫자를 직접 추출하여 만든 손글씨 숫자 데이터셋인 NIST를 일반화, 표준화하여 발전시킨 MNIST에 기원을 두는 데이터셋입니다. 손글씨 숫자를 패션과 관련된 이미지로 대체한 것인데요. Fashion MNIST는 10개의 카테고리로 분류되는 70,000개의 흑백 이미지로 구성된 데이터셋입니다.

Fashion MNIST 데이터셋 예시
- ImageNet
ImageNet은 1,400만 개 이상의 공개 이미지 데이터셋으로, 스탠포드 대학의 Fei-Fei Li 교수와 그녀의 공동 작업자가 컴퓨터 비전 분야에 있어 학습 데이터의 부족 문제 해결을 위해 2009년에 시작한 데이터셋입니다. 그 분류가 매우 다양해서 일상생활에서 볼 수 있는 거의 모든 종류의 이미지를 얻을 수 있습니다.

ImageNet 데이터셋 예시
- MS COCO
COCO는 Common Objects in COntext의 약자로 딥러닝 프로그램을 교육하는 데 사용되는 가장 인기 있는 오픈소스 데이터베이스 중 하나로, Object Detection, Segmentation, Keypoint Detection 등에 쓰입니다. COCO 데이터는 이미지를 설명하는 캡션도 함께 제공하여, 이미지를 설명하는 문장을 학습시켜 유사한 이미지가 주어졌을 때 설명을 자동으로 생성할 수 있도록 하는 데 큰 기여를 했습니다. COCO 데이터셋에 대한 관심도 많지만 이 데이터들을 저장하는 COCO 데이터셋의 방식인 데이터 포맷에 대한 관심도 많은데요. 이에 대해 관심있으신 분들은 이 영상을 참조해주세요.

MS COCO 데이터셋 예시
- Cityscapes
자율주행에서 사용될 수 있는 도로환경과 관련된 가장 유명한 데이터셋입니다. 50개 도시의 거리 장면에서 기록된 다양한 스테레오 비디오 시퀀스 세트를 포함하는 새로운 대규모 데이터셋으로 도시 장면에 대한 의미론적 이해에 중점을 둡니다.

Cityscapes 데이터셋 예시
- Open image
구글이 머신러닝을 위해 2016년에 공개한 이미지에 주석이 달린 데이터셋으로 약 190만개에 전문 라벨러들이 라벨링을 검수한 이미지들을 포함하고 있습니다. 데이터셋은 V1부터 계속 업데이트 되어 2020년 2월 기준으로 가장 최신 버전인 V6버전까지 공개되었습니다. 이미지 상의 객체간 관계를 보여주는 라벨링, 이미지를 설명하는 캡션과 음성 나레이션이 추가되어 이미지와 캡션 사이를 연결하는 복잡한 모델을 만드는 데 유용하게 사용되고 있습니다.
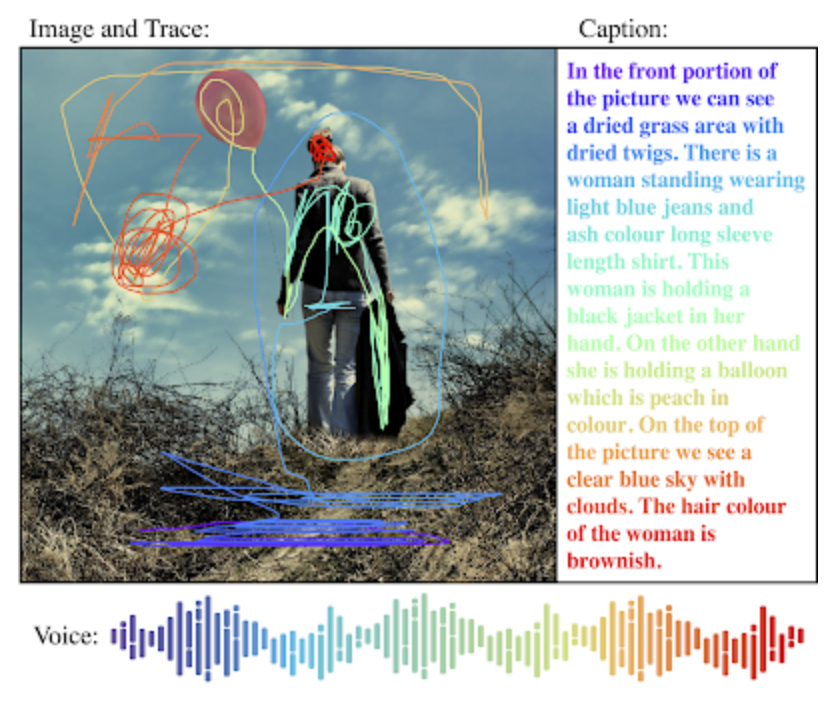
캡션과 나레이션이 추가된 Open image v6 예시 (Source : AI googleblog)
여전히 많은 기업들은 데이터 수집 단계에서부터 어려움을 겪고 있습니다. 컴퓨터 비전 데이터 영역에서의 전문성을 집중적으로 키워온 슈퍼브에이아이 또한 의미있는 데이터 구축의 중요성에 통감하며 이를 성공적으로 해낸 경험이 있는데요. 바로 2020년 1월에 공개한 한국어 글자체 데이터셋입니다. 한국어 특유의 독창성과 확장성 때문에 데이터셋 구축이 어려운 걸로 알려져 있지만 데이터 영역에서 그동안 쌓아온 노하우와 Superb AI의 Suite의 기술력으로 데이터셋을 완성할 수 있었습니다. 자세한 내용은 기계에게 한글을 가르칠 수 있을까? 를 참고 부탁드립니다.
지금까지 컴퓨터 비전에 대한 내용을 함께 살펴보았습니다. 현재의 컴퓨터 비전은 얼굴 인식 기술, 의료 이미지 분석, 자율주행차, 보안 감시 등 다양한 영역에서 활용되며 더 고도화되고 있습니다. 컴퓨터 비전 영역은 매우 빠르게 발전되고 있어서 작년에만 45,000개 이상의 논문이 발표되기도 했습니다. 하지만 비전영역은 여전히 갈 길이 멀다고 합니다.
앞서 언급했던 Jitendra Malik의 인터뷰로 다시 돌아가보겠습니다. “왜 우리는 아직도 컴퓨터 비전 문제에 대해서 과소평가하거나 얼마나 어려운지조차 제대로 인식하지 못하는 상황에 있을까요?” 라는 질문에 교수는 이렇게 대답합니다.
“저는 그 이유를 성공적인 첫 번째 단계의 오류(Fallacy of the successful first step)로 설명하려 합니다. 보통 컴퓨터 비전 문제의 해결책의 50% 정도는 1분 안에 얻을 수 있습니다. 90% 정도는 아마 하루 만에 얻어낼 수 있겠죠. 하지만 99%까지는 5년 안에, 그리고 99.9%를 풀어내는 것은 평생을 바쳐도 어려울 거라는 것이죠.”
처음에 POC(Proof Of Concept) 수준의 데이터를 가지고 모델을 학습했을 때 어느 정도까지는 성능을 뽑아내는 것에 성공할지 모릅니다. 그리고 예산을 조금씩 늘려가며 원하는 결과를 어느 정도 얻어내는 데까지 도달했을 때 많은 팀은 데이터 문제를 해결했다고 착각합니다. 하지만 비즈니스 환경에서 동일한 결과를 만들어 내는 데는 많은 과제가 숨어있습니다. POC 단계에서는 실행 가능성을 확인할 수 있을 뿐, POC수준의 워크플로우로는 실제 환경에서 맞닥뜨릴 문제를 대비하기엔 충분하지 않습니다.
모델 성능을 일정 수준 이상 달성하는 데 성공했다면, 이제 각 단계별로 컴퓨터 비전 데이터 관리가 용이한 튼튼한 파이프라인을 설계해나가는 데 관심을 기울여야 합니다. 목표가 모델을 구현하고 학습하는 데 그치는 게 아니라 프로덕션 환경에서도 지속적으로 운영하는 시스템을 만드는 것이라면요. 급변하는 AI 서비스 환경에서는 사용자 데이터가 실시간으로 쌓이며 이를 반영하기 위한 반복적 학습은 필수입니다. MLOps, DataOps를 처음부터 고려해서 설계된 체계적이고 견고한 시스템이 아니면 지텐드릭 교수가 말한 오류에 빠질 수 있는 것이죠.
Superb AI는 상용화를 위한 컴퓨터 비전 서비스 개발에 필요한 방대한 양의 데이터를 가시적이고 효율적으로 관리할 수 있도록 돕는 머신러닝 데이터 플랫폼을 만들고 있습니다. 변수가 많은 비즈니스 환경에서도 성능을 유지할 수 있는 데이터 파이프라인 구축을 준비하세요. 빨리 시작할수록 컴퓨터 비전 데이터에 대한 보다 깊은 통제와 관리 노하우가 축적될 것이며 이는 AI의 성능에 직접적인 영향을 미칠 것입니다.