
Superb AI와 WhyLabs가 만나다 : 데이터 라벨링과 데이터 모니터링을 한 번에


배경 : 이 포스팅은 WhyLabs와 Superb AI이 함께 파트너십을 맺고 작성한 블로그 게시물입니다. 저희는 DataOps 파이프라인 구축의 어려움을 소개하는 동시에 Superb AI의 데이터 라벨링 기능과 WhyLabs의 데이터 모니터링 기능을 통해 이를 어떻게 해결해 나갈 수 있는지 보여드릴 예정입니다.
참고 : 이 포스팅에서 언급하는 데이터는 컴퓨터 비전에 한정되어 작성되었으므로 이미지 혹은 비디오를 의미합니다.
들어가며
데이터 품질은 고성능 머신 러닝 모델의 핵심입니다. 학습할 고품질 데이터가 없으면 모델은 데이터가 압축하여 반영하는 리얼월드의 실제 프로세스를 나타낼 수 없습니다. 그리고 일단 모델에 제공할 고품질 데이터가 없으면 모델의 예측이 크게 부정확해질 것입니다. 그렇기 때문에 WhyLabs와 Superb AI는 데이터 과학자와 머신러닝 엔지니어가 고품질 데이터를 생성하고 데이터 품질을 모니터링 할 수 있는 도구를 개발하는 데 집중하고 있습니다.
이번 블로그 게시물에서는 WhyLabs와 Superb AI의 기술이 AI 실무자에게 어떻게 상호보완적으로 가치를 전달하는지 그 과정을 보여드릴 예정입니다. 각 플랫폼에 대한 간략한 설명 후 각각의 플랫폼의 워크플로우 예제를 소개하겠습니다.
Superb AI Suite 플랫폼
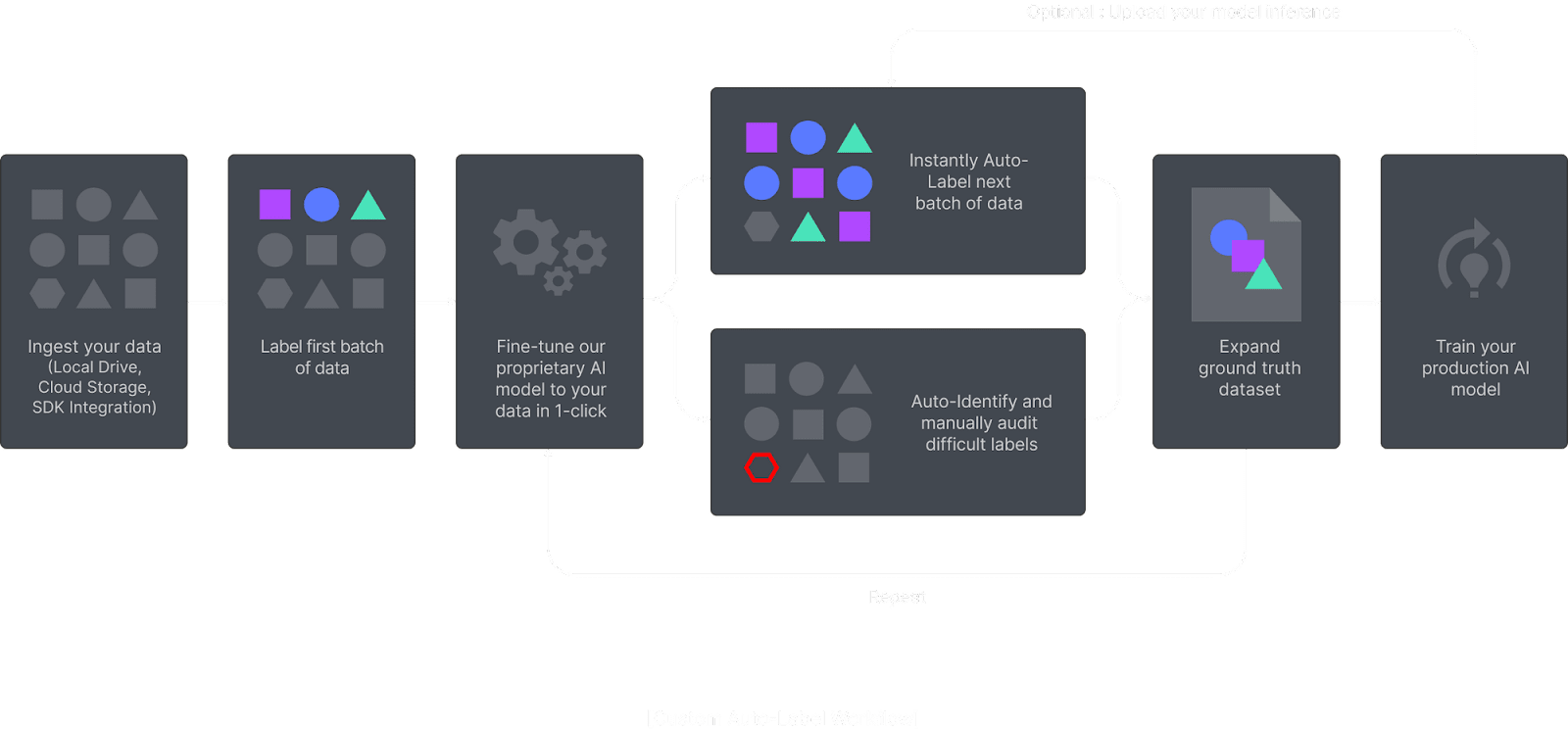
Superb AI는 ML 팀이 고품질 학습용 데이터셋을 제공하는 데 걸리는 시간을 획기적으로 줄일 수 있는 혁신적인 방법을 제안합니다. 대부분의 데이터 준비 워크플로우를 라벨러에 의존하는 대신, 이제 Superb AI의 Suite를 통해 시간과 비용을 절약할 수 있는 파이프라인을 구현할 수 있습니다.
데이터 작업은 Superb AI의 커스텀 오토 라벨링(CAL)기술을 중심으로 이루어집니다. 커스텀 오토 라벨링 기술은 전이 학습, 퓨샷러닝 및 autoML의 고유한 조합을 사용하는데 이는 모델이 작은 양의 고객의 고유 데이터셋으로도 높은 수준의 효율성을 빠르게 달성할 수 있도록 해줍니다. 컨셉은 매우 간단합니다. 방대한 양의 정답 데이터셋을 일일이 생성하는 대신, 팀은 이제 훨씬 더 적은 정답 데이터(ground truth 혹은 golden set)를 구축하는 것이죠. 그리고 이 데이터셋을 가지고 오토 라벨링 모델을 통해 몇 번의 클릭만으로 짧은 시간 내에 대규모 데이터셋을 만들 수 있습니다. 전매 특허의 딥러닝 모델의 불확실성을 추정하는 기법(Uncertainty Estimation AI)과 엔터프라이즈 레벨의 검수 도구를 워크플로우와 연결함으로써, 팀은 대규모 데이터셋을 라벨링하면서 까다로운 라벨은 바로 가려내고 검수를 위한 액티브러닝 워크플로우를 구축할 수 있습니다. 이런 방식으로 여러분의 팀은 데이터셋을 단 며칠만에 완성할 수 있습니다.
AI 관찰가능성 확보가 가능한 WhyLabs 플랫폼
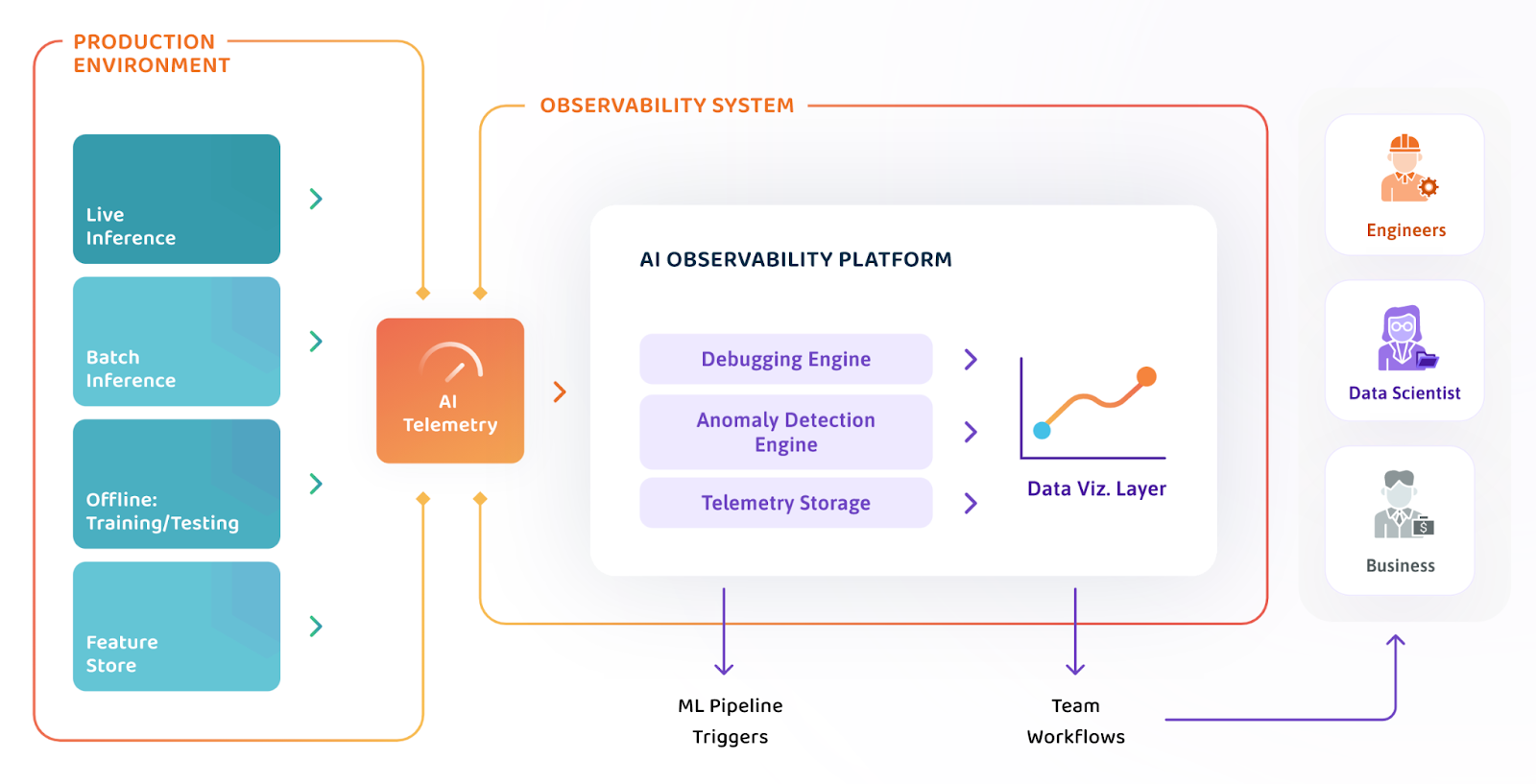
WhyLabs는 ML 배포를 모니터링하고 관찰하는 데 누락된 퍼즐 조각을 제공합니다. WhyLabs AI Observability Platform을 통해 모델 및 데이터 품질을 보장하는 것이 그 어느 때보다 쉬워졌습니다. 데이터 과학팀은 이 플랫폼을 사용하여 데이터 파이프라인 및 AI 애플리케이션을 모니터링하여 데이터 품질 문제, 데이터 편향 및 개념 드리프트를 가시화 할 수 있습니다. WhyLabs의 이상 징후 감지 및 특수 목적의 시각화를 통해 팀은 비용이 많이 드는 모델 장애를 예방하여 수동적인 트러블 슈팅이 필요하지 않도록 해줍니다. 이는 정형 또는 비정형 데이터, 규모에 상관없이 모든 플랫폼에서 작동합니다.
WhyLabs는 데이터 및 ML 모델을 모니터링하는 고유한 접근 방식입니다. 오픈소스 데이터 로깅 표준인 whylogs에 의존하여 데이터 프로파일, 데이터셋의 통계 요약을 생성합니다. 이러한 프로파일은 분석 및 알림 경고를 받을 수 있는 WhyLabs 플랫폼으로 전송됩니다.
자동화된 라벨링과 모니터링을 통한 안정화된 데이터 운영
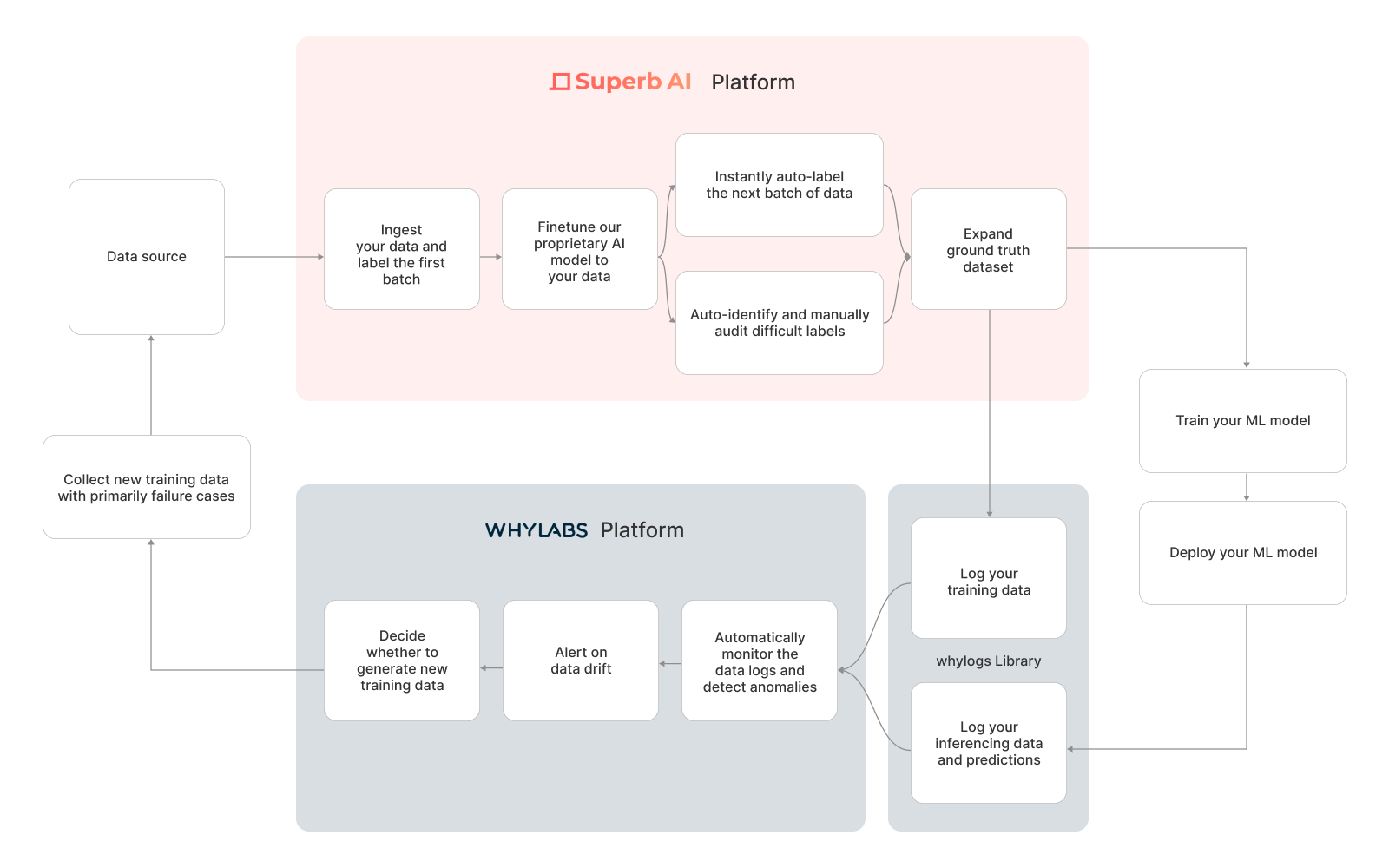
WhyLabs의 대표적인 사용 사례는 컴퓨터 비전 모델의 모니터링일 것입니다. 모델을 모니터링하려면 모델을 학습시킨 이미지로부터 베이스라인 프로파일을 생성해야 합니다. 그런 다음 모델이 프로덕션으로 배포가 되면 추론에 사용되는 이미지에 더 많은 프로파일이 생성됩니다. 이러한 프로덕션 프로파일을 기존에 생성한 베이스라인 프로파일과 서로 비교하면서 데이터 과학자는 데이터 드리프트가 발생해 성능이 저하되기 시작하는 시점을 파악할 수 있습니다.
사용자가 Training-serving skew(학습에 사용한 데이터와 서빙시 사용한 데이터가 다른 것을 의미) 또는 데이터 드리프트를 경험하는 경우 모델 성능 저하가 반드시 따를 수 있습니다. 또한 모델에 문제가 있는 경우에는, 비즈니스 잠재 수익이 손실될 수 있죠. 이 모델 성능 저하 이슈를 해결하기 위해 사용자는 Superb AI의 Suite로 돌아와 새로운 데이터셋을 자동으로 라벨링하고 그 데이터를 기반으로 모델을 재학습 시킬 수 있습니다.
마치며
이 글을 통해 WhyLabs과 Superb AI는 고품질 데이터 구축과 검수를 위해 완벽히 결합하여 상호보완적으로 작동하는 것을 확인할 수 있으셨을 겁니다.
WhyLabs을 사용해보고 싶으시다면 이 곳에서 무료 community edition을, Superb AI의 Suite를 사용해보고 싶으시다면 데모요청을 하거나 무료 체험을 신청해서 Suite를 경험해보세요.