Product
How to Build & Deploy an Industrial Defect Detection Model for a Lucid Vision Labs Camera

Sam Mardirosian
Solutions Engineer | 2025/03/17 | 15 min read

How to Build & Deploy an Industrial Defect Detection Model for a Lucid Vision Labs Camera
Developing an effective model training pipeline is essential for building high-performance computer vision models. A well-structured pipeline ensures that data is collected efficiently, curated intelligently, labeled accurately, and used to train a model that can generalize well to real-world scenarios. By optimizing each step of the pipeline, we can reduce the time, cost, and effort required to develop robust AI systems.
In this tutorial, we’ll walk through a complete model development and deployment pipeline, covering every step from data collection and curation to model training and deployment. We’ll demonstrate how to automate and streamline this process to improve efficiency and performance using Superb AI’s one-stop AI platform.
We'll be building a general defect detection model for real-time industrial applications. While we’ll use a standard Lucid Vision Labs camera for demonstration, this workflow can be adapted to other camera types, such as security cameras (e.g., RTSP CCTV) or webcams. Using a Lucid Vision Labs camera, we’ll capture image data, curate and label it using Superb Curate and Superb Label, train a model using Superb Model, and finally deploy it for real-time defect monitoring. This approach can be extended to any object detection use case, including security and safety, equipment monitoring, and compliance enforcement.
By the end of this tutorial, you’ll have a functional pipeline that can be adapted to different use cases, ensuring your computer vision model is trained on high-quality, well-curated data and ready for real-world deployment.
Get Started with Data Collection
When training a computer vision model, the first and most crucial step is data collection. High-quality and diverse datasets are essential for ensuring accurate and reliable model performance. The amount of data required depends on the complexity of the task—simpler use cases may need fewer images, while more challenging scenarios with numerous edge cases will require a larger and more varied dataset.
This tutorial assumes you have a Lucid Vision Labs camera for training data collection and model deployment, and that the Lucid Arena SDK is installed. The following is a script for collecting data from a Lucid Vision Labs camera. Specifically, the script captures one image every second, and uploads it to a new Superb Curate dataset. Depending on the use case, you may wish to capture training data more or less frequently. Users may want to configure a trigger based on a light sensor or rotary motor encoder to take images at irregular intervals, such as when an object on a conveyor belt is positioned under the camera.
$ pip install --upgrade superb-ai-curate numpy opencv-pythonimport os
import time
import numpy as np
import cv2
import time
import spb_curate
import arena_api.system as sys
from datetime import datetime
from spb_curate import curate
# Superb AI access key and team name
spb_curate.access_key = "your_API_access_key"
spb_curate.team_name = "your_team_name"
# Define output directory
# Directory to save captured images
SAVE_DIR = "captured_images"
os.makedirs(SAVE_DIR, exist_ok=True)
def initialize_camera():
system = sys.system
devices = system.device_infos
if not devices:
raise Exception("No Lucid camera detected.")
# Create a camera device
camera = system.create_device(devices[0])
return camera
def capture_image(camera):
camera.start_stream()
while True:
try:
buffer = camera.get_buffer(timeout=2000) # Get image buffer
last_captured_time = None
if (last_captured_time is not None
and time.time() - last_captured_time < 1):
camera.requeue_buffer(buffer)
continue
last_captured_time = time.time()
# Convert to NumPy array
item = BufferFactory.copy(buffer)
camera.requeue_buffer(buffer) # Requeue buffer for next frame
num_channels=1
buffer_bytes_per_pixel = int(len(item.data)/(item.width * item.height))
array = (ctypes.c_ubyte * num_channels * item.width * item.height).from_address(ctypes.addressof(item.pbytes))
npndarray = np.ndarray(buffer=array, dtype=np.uint8, shape=(item.height, item.width, buffer_bytes_per_pixel))
# Save image
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = os.path.join(SAVE_DIR, f"frame_{timestamp}.jpg")
cv2.imwrite(filename, npndarray)
print(f"Saved: {filename}")
yield filename
# Stop stream on keyboard interrupt (Ctrl + C)
except KeyboardInterrupt:
print("Stopping capture.")
break
# Stop stream
camera.stop_stream()
def upload_image(image_path, dataset:spb_curate.Dataset):
image = curate.Image(
key=os.path.basename(image_path),
source=curate.ImageSourceLocal(asset=image_path),
metadata={}
)
dataset.add_images(images=[image])
if __name__ == "__main__":
print("Starting image capture.")
dataset = curate.create_dataset("Lucid Camera Data")
camera = initialize_camera()
for image_path in capture_image(camera):
upload_image(image_path, dataset)
system.destroy_device(camera)
Once we’ve collected enough initial data (e.g. 5,000 frames) we can upload it to Superb Curate. Superb Curate enables you to refine and optimize your dataset before the labeling process. With its automated selection capabilities, you can identify the most valuable subset of your data for model training, improving efficiency while reducing the cost of Human-in-the-Loop (HitL) labeling. In some cases, this approach can shrink the training dataset by up to 75% while maintaining comparable model performance.
Selecting Data with Superb Curate
Once the data has been uploaded, we can access it in Superb Curate to refine and prepare it for labeling. The platform offers powerful tools for dataset exploration, allowing us to filter data by metadata, perform natural language searches on both labeled and unlabeled data, and visualize the distribution of data embeddings using the Scatter View. These features help streamline the dataset curation process and provide deeper insights into the collected data.
To make labeling more efficient, we’ll use Auto-Curate to intelligently select a subset of our data. Auto-Curate provides various options, such as automatically identifying edge cases and detecting mislabels, which can help improve dataset quality. In this case, we’ll focus on using Curate What to Label, a feature designed to select the most valuable subset of data for labeling and model training. By prioritizing the most informative data points, this approach enhances model performance while reducing the time and cost associated with manual annotation.
Embeddings, visualized here in the Superb Curate Scatter View for a smart factory manufacturing use case, will be leveraged when Auto-Curating
As mentioned above, there are a few options here to select the best subset of data for initial labeling. For some use cases, it may be useful to combine an AI Search natural language query with our Auto-Curate tools to pick out interesting edge cases for model training. A key advantage of using a multi-modal VLM (vision-language model), such as the one leveraged in Superb Curate, is that we can search using both text and image queries, and we don’t need our data to be labeled. We can also use metadata, such as time, camera, or location to further fine-tune our curation.
Using metadata in combination with similar image search to pick out specific types of images from a specific location in a smart factory use case
In some cases, defects or anomalies are extremely rare, occurring as infrequently as 1 in 1,000 or even 1 in 10,000 instances. This means that collecting enough real-world examples to train a model effectively could require capturing tens of millions of images—an approach that is often impractical and costly.
One way to mitigate this challenge is synthetic data. By leveraging Superb Model to train a synthetic image generation model, we can create examples of rare edge cases, helping to enhance model performance without the need for an extensive real-world dataset.
Adding synthetic wood defect objects to an unlabeled image with inpainting
To enhance our dataset, we can insert synthetic objects into unlabeled images with inpainting tools using pretrained models or models trained on existing data (see above). If we have labeled data, annotated images can serve as a reference to automatically generate synthetic data while preserving the original object layout (see below). This approach helps create realistic training data and improves model performance.
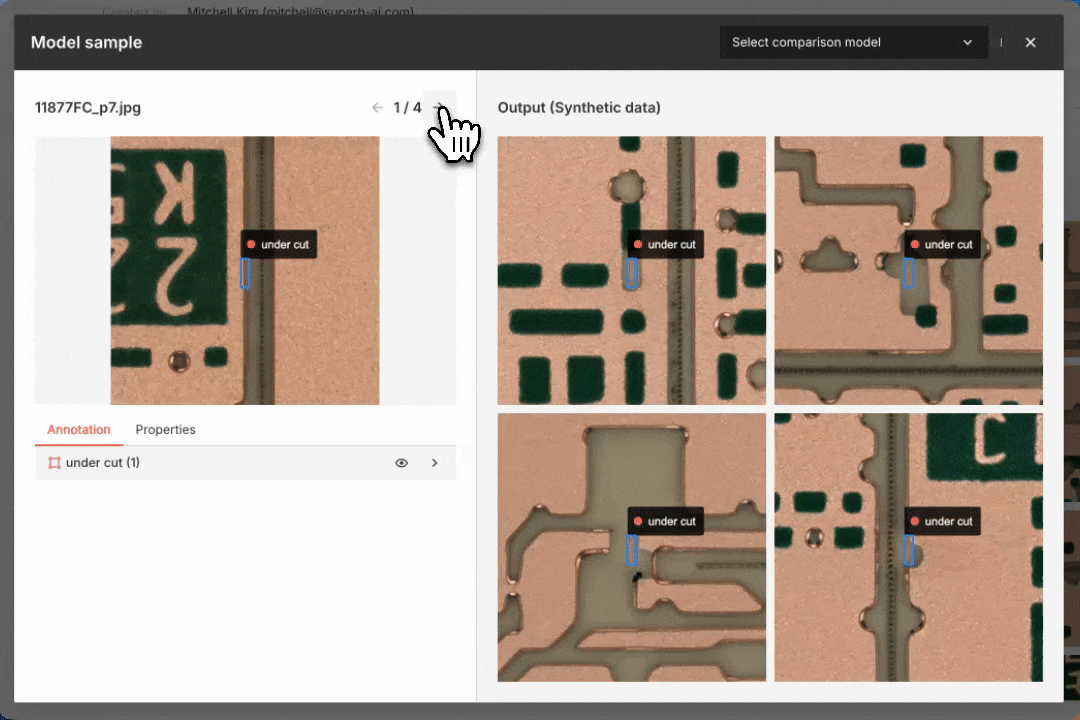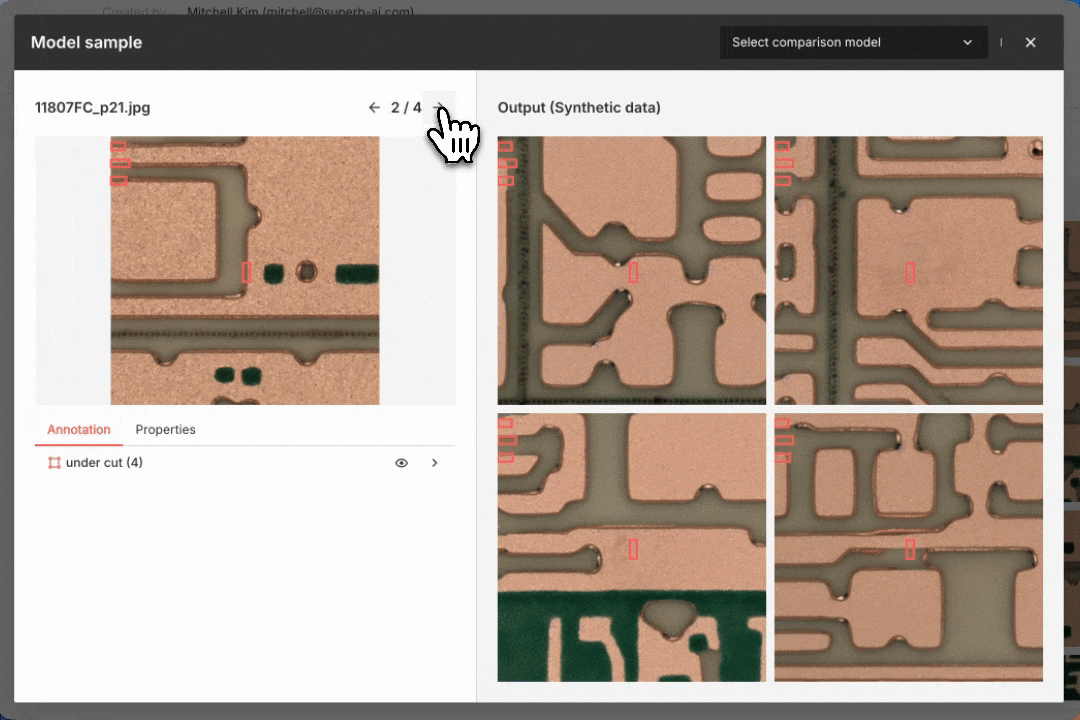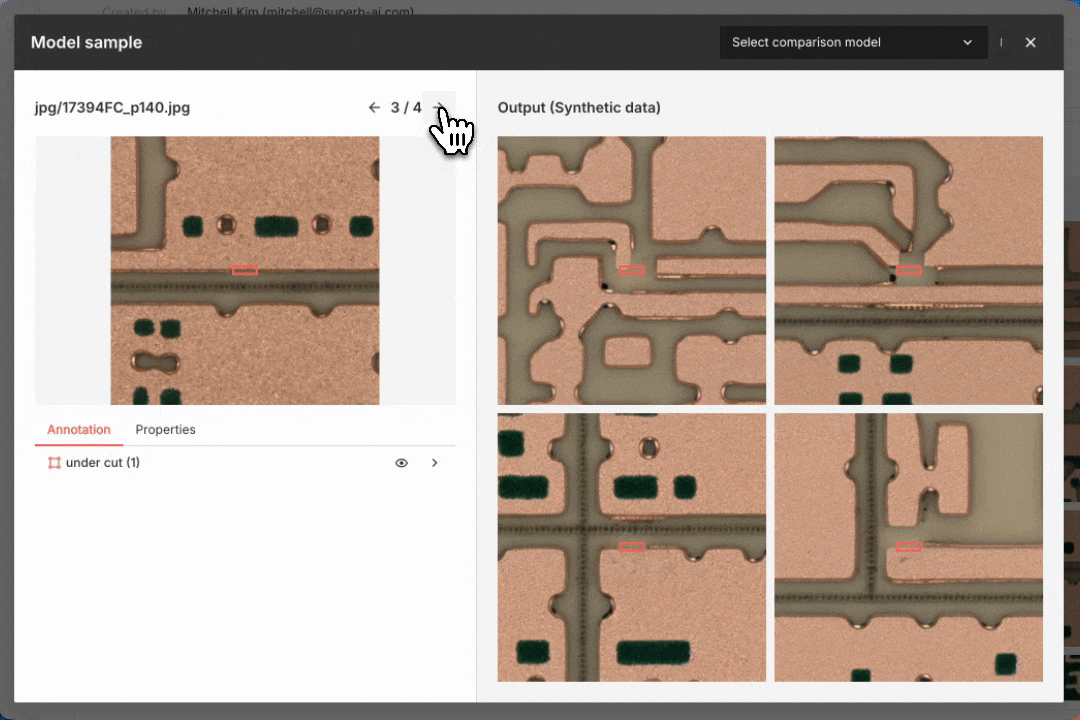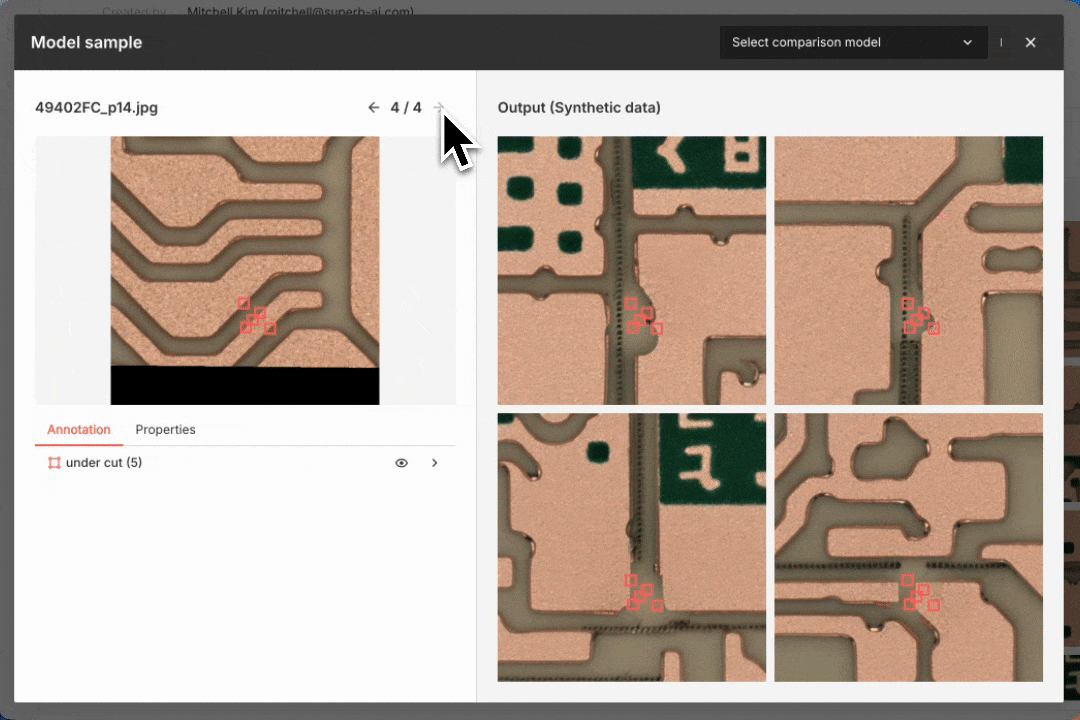
Generating synthetic defect data for a smart factory use case. The original labeled image is on the left; the synthetic data output is on the right
Once we’ve selected our initial set of images for labeling, we can send this slice to Superb Label.
Annotate Data with Superb Label
Superb Label offers a range of label and project types to suit different machine learning tasks. Using Superb Label’s advanced labeling automation tools and robust review workflow, we can quickly create our initial ground-truth dataset for model training.
Using Superb AI’s Custom Auto-Label to automatically label images in an industrial steel defect detection dataset
Superb AI provides pre-trained model options for automating initial labeling, and once a small ground truth is labeled, these models can be fine-tuned to produce a Custom Auto-Label model optimized for performance on users’ specific use cases. Once the data is labeled, we can send the annotations back to Superb Curate for further curation and model training.
Train a Model with Superb Model
Now that we have the labeled data back in Superb Curate, we can start training our model in Superb Model. Superb Model has a Model Hub of powerful foundational models and popular computer vision models you can choose from, for object detection, segmentation, and even image generation, including several object detection models like YOLOv6 and DETA, and segmentation models like DETR and Mask2Former. For this example we’ll use the DETA model as our backbone for training. A DETA (Detection Transformer) model is highly effective for defect detection due to its ability to detect small, rare, and complex defects with high accuracy. Its use of global self-attention and the lack of predefined anchors allows it to identify subtle anomalies, handle irregular defect patterns, and adapt to data-limited scenarios, making it ideal for industries with varied or scarce defect types.
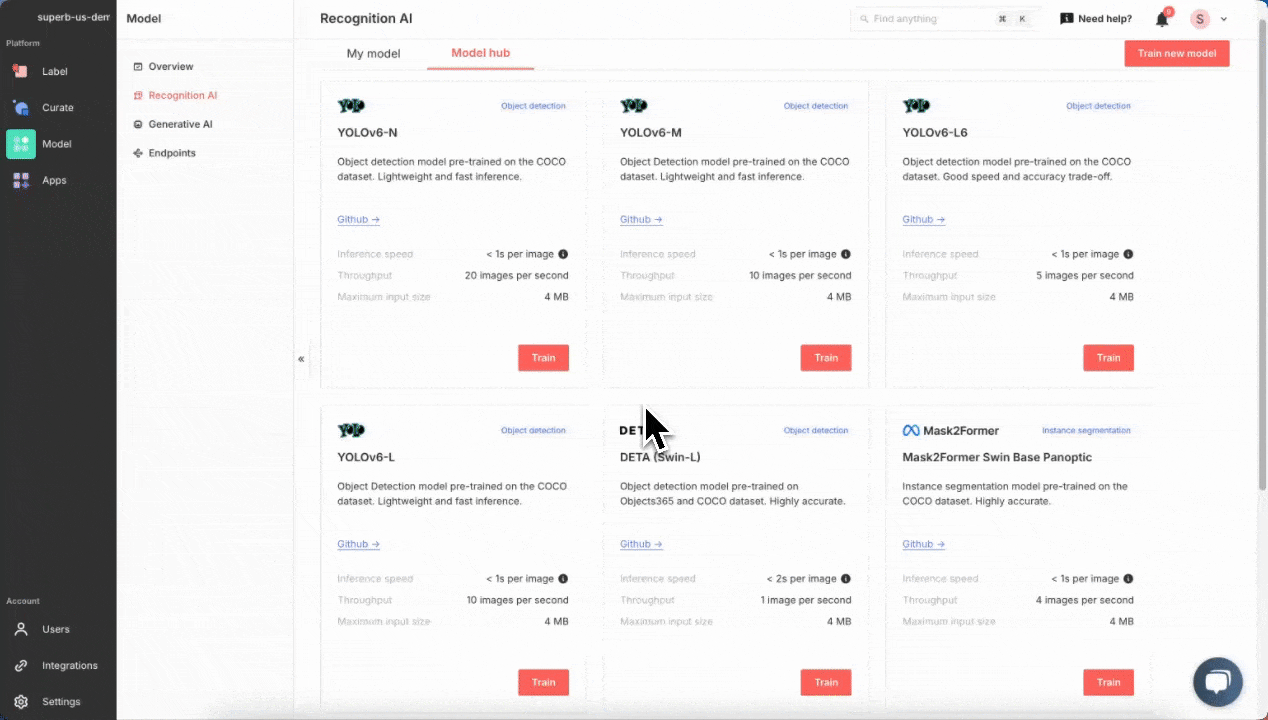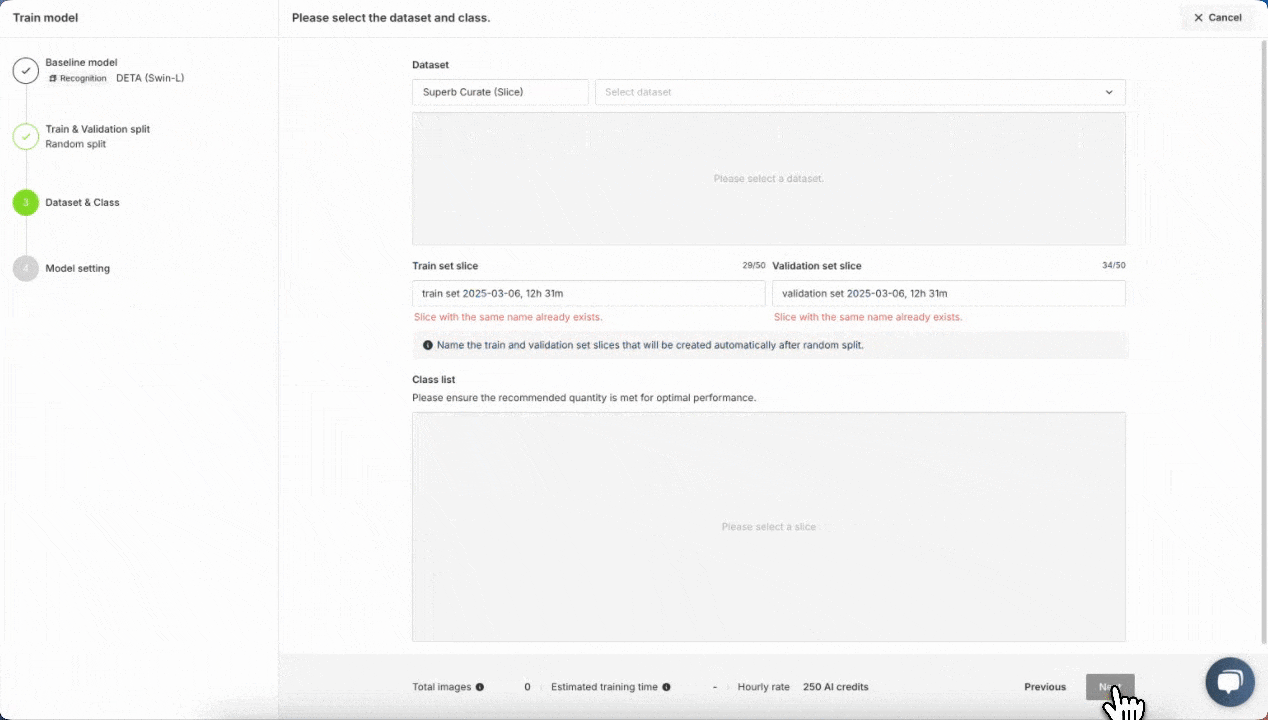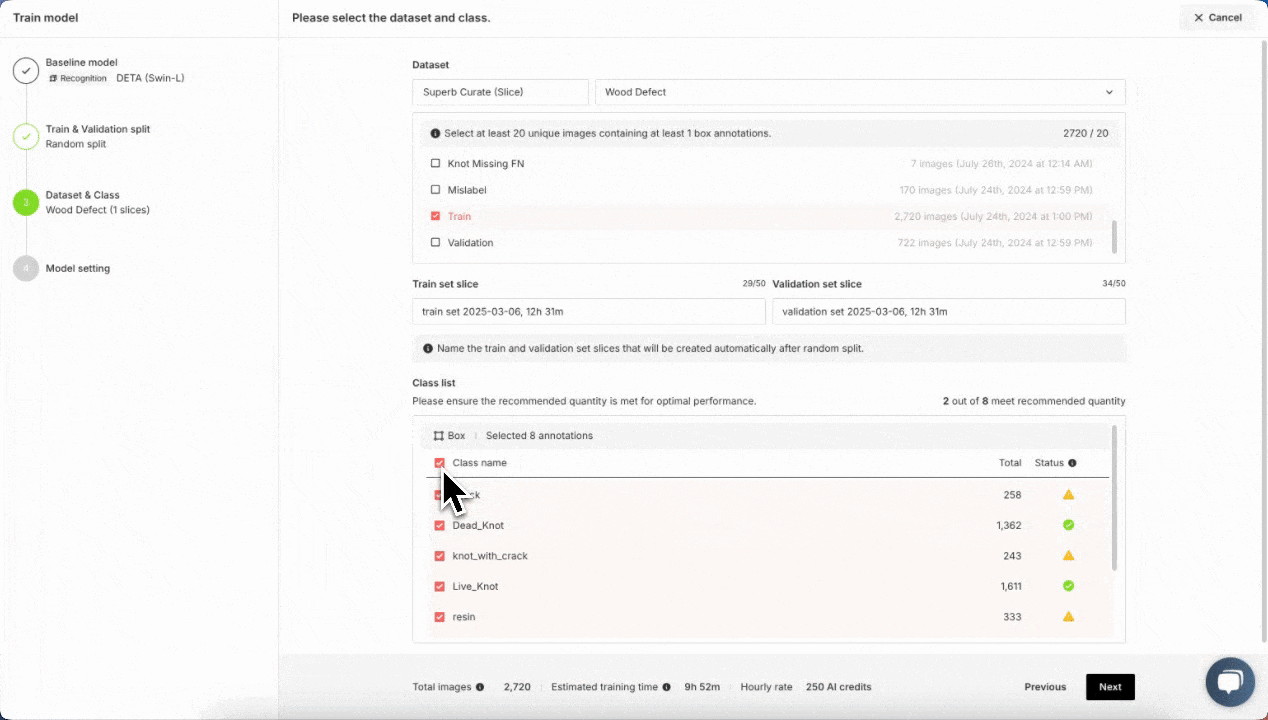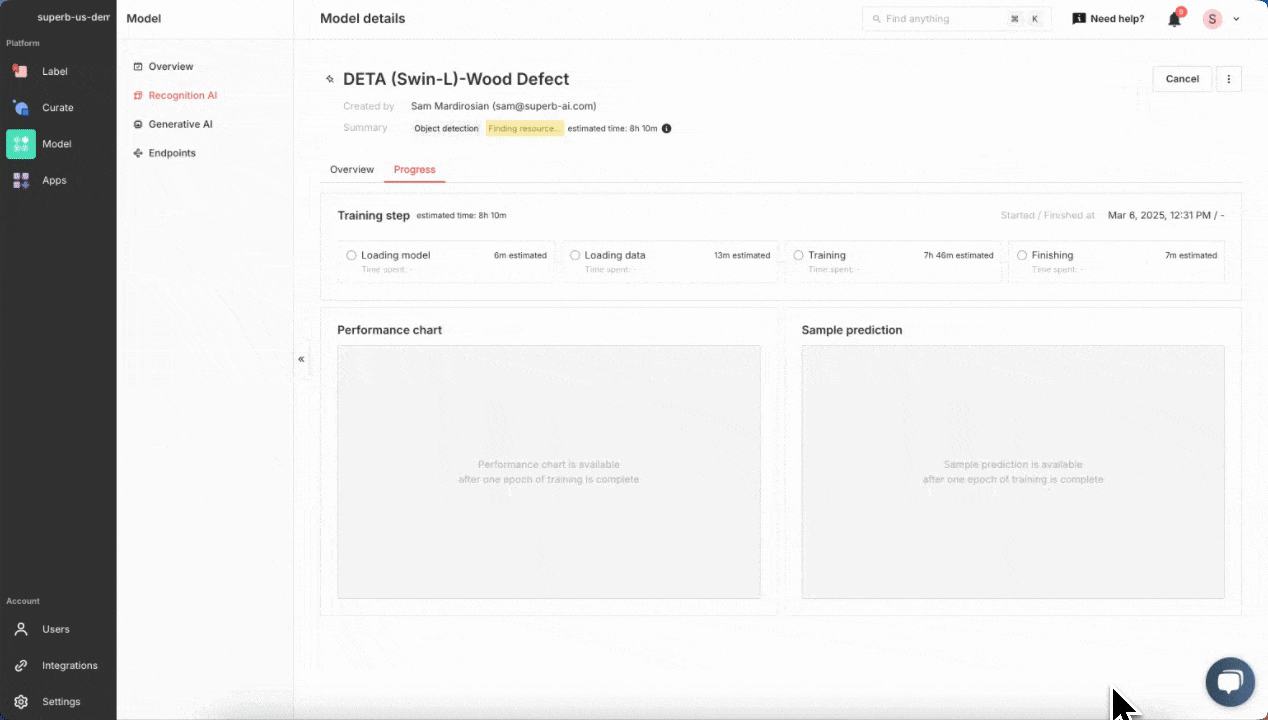
Quickly training a wood defect detection model from scratch in Superb Model. Training a model in Superb Model requires no code. Just select a model architecture and provide a labeled dataset; everything else is done automatically
In Superb Model, select the Recognition tab, and then pick “Train new model”. Select DETA as our model source, and then pick a “Random split” for training and validation sets. For a more robust training and validation set split, it may be worth considering using a manual split in conjunction with Auto-Curate’s Split Train/Validation Set option, which can produce a higher quality validation set, improve training results, and evaluate model performance more effectively. Next, we can select our Curate dataset of images, pick a name for our model and start training! We can monitor the training status of the model here, in the My models tab. Once it’s completed at least one training epoch, we can check the current model performance, and finish the training early if the model performance is sufficient for our purpose.
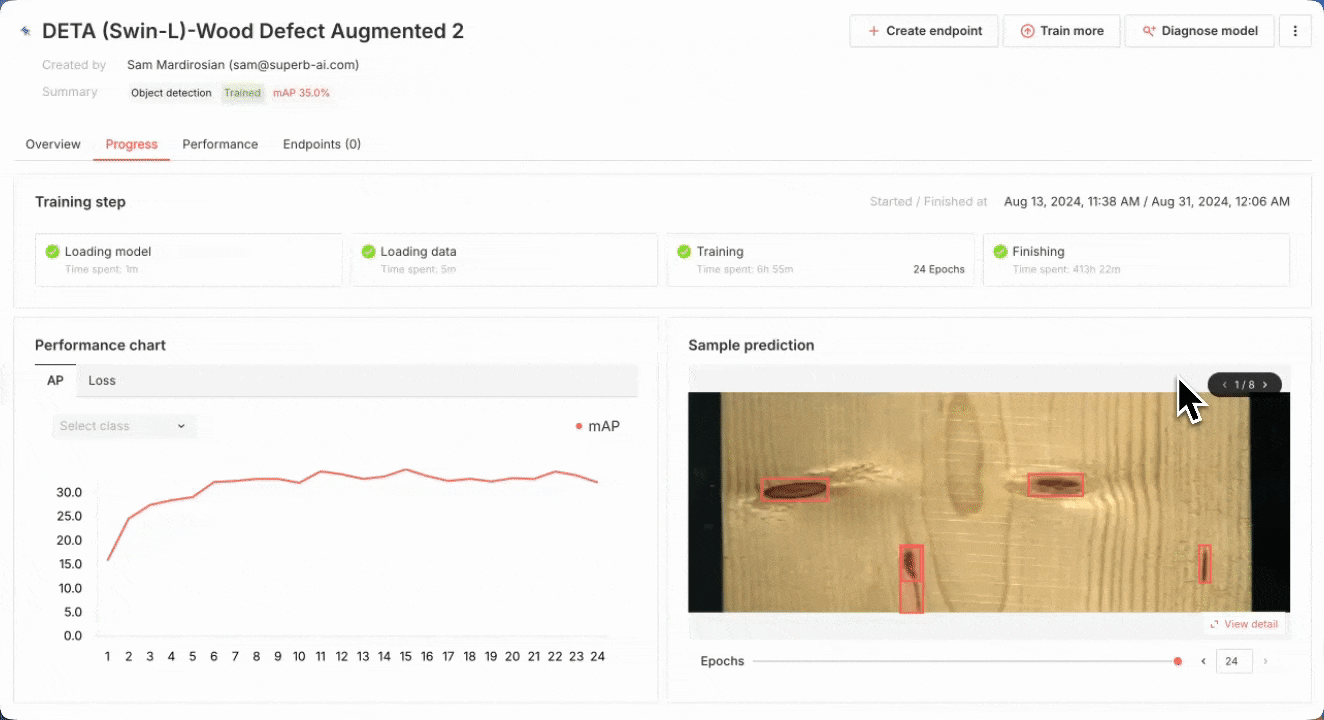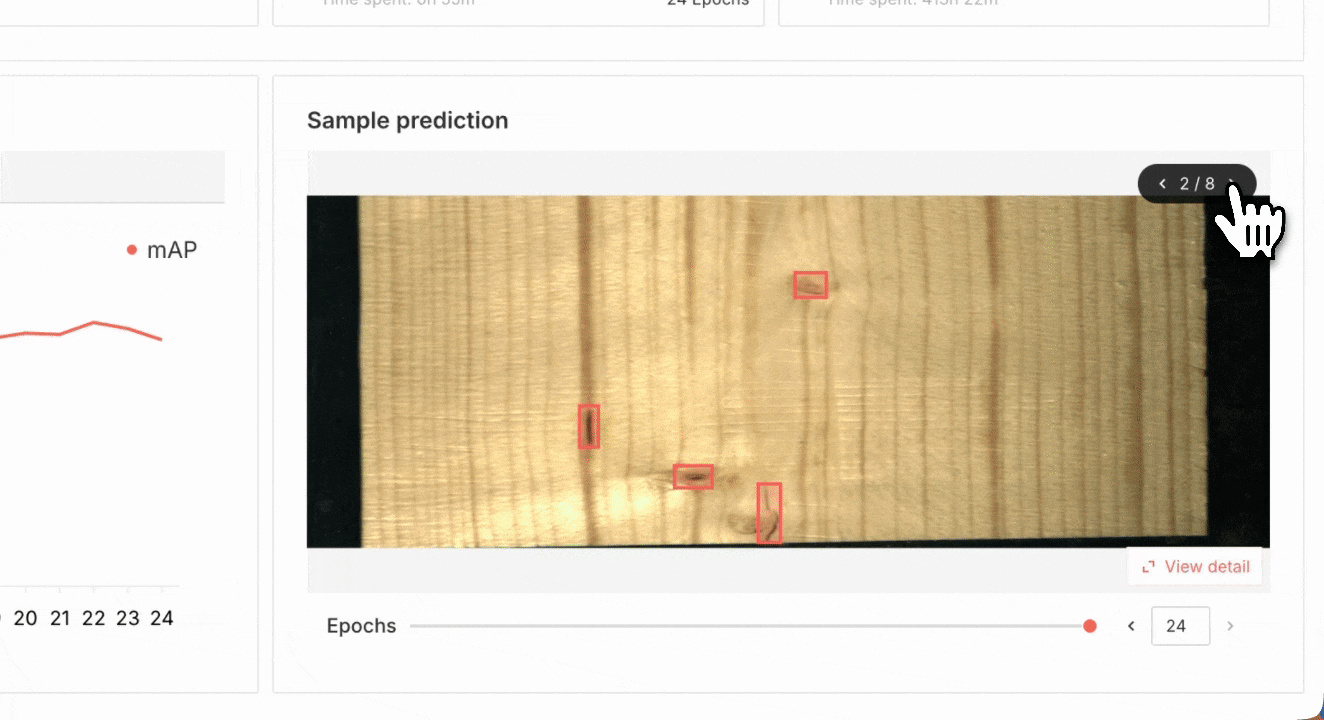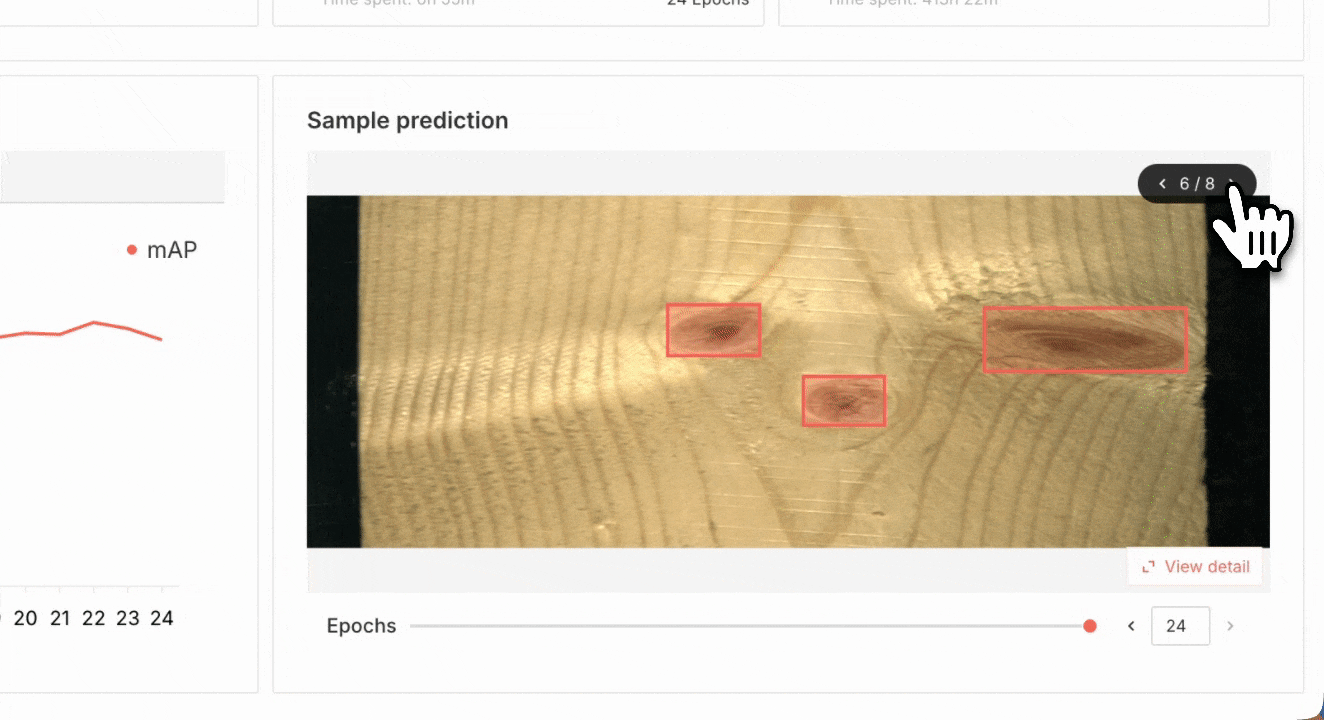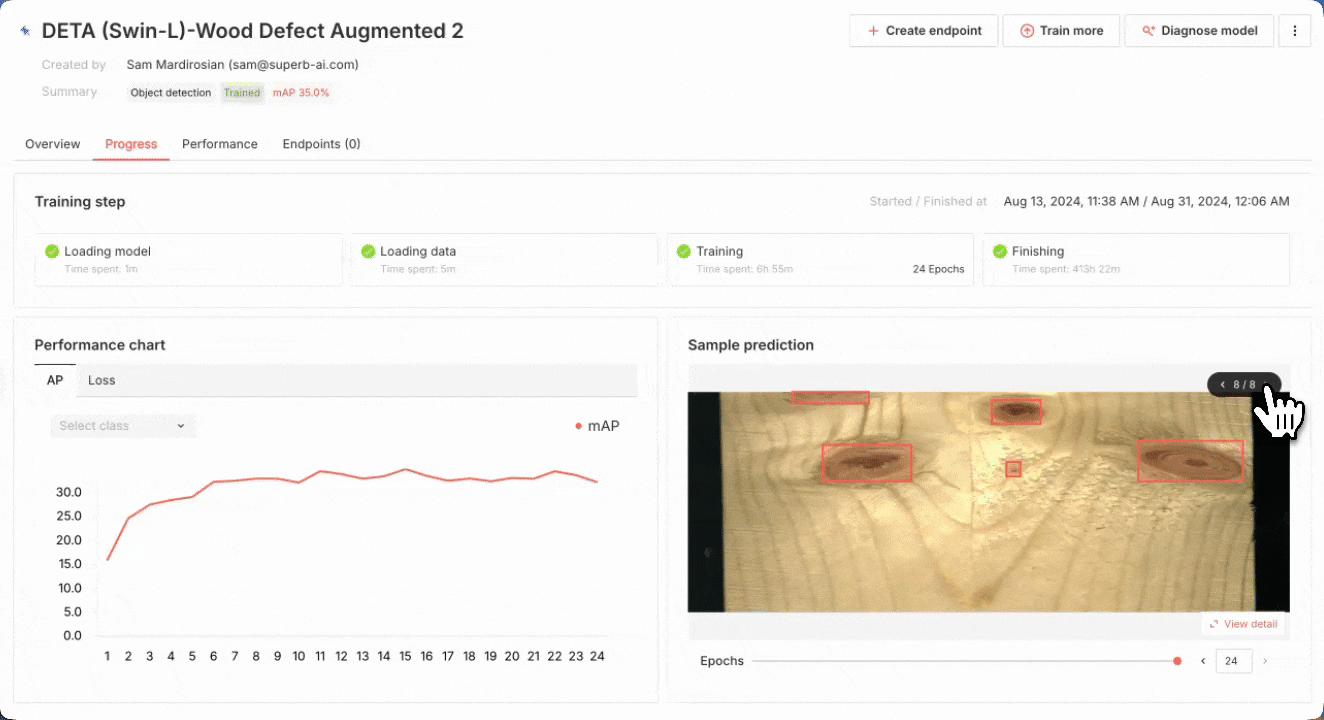
Reviewing model performance for a wood defect detection model
Once the model has finished training, we can review the training results in the My models tab. We can also deploy a new endpoint for the trained model, or use Model Diagnosis to diagnose and improve model performance.
Using Model Diagnosis to quickly review model performance and identify False Positive results with high confidence intervals in an infrastructure corrosion detection model
Deploying the Model using Superb Model Cloud API
With the model trained, the next step is deploying it to production. One way we can do this is using our cloud and an Endpoint API. In this example, we’ll create an Endpoint for the model, stream data from the Lucid Vision camera, and run inference on live production data.
First, we’ll deploy an endpoint for the model using the Create endpoint option in Superb Model. After deploying the endpoint, a unique URL is provided for running inference on captured images. This URL allows us to send images to our trained model for real-time predictions.
Creating an endpoint for a shipping label detection model
The following script captures images from a Lucid Vision Labs camera and sends them to the endpoint for inference; without any further optimization, we should be able to run inference at around 10 frames per second. Note that we can use our inference results to find new images for subsequent iterations of our model training; in this example, some commented sample code is provided to upload any images with low confidence interval defects (i.e. less than 0.5) to our Curate dataset:
import requests
from requests.auth import HTTPBasicAuth
def run_inference(image_path):
image = open(image_path, "rb").read()
response = requests.post(
url="https://your_endpoint_url",
auth=HTTPBasicAuth(TEAM_NAME, ACCESS_KEY),
headers={"Content-Type": "image/jpeg"},
data=image,
)
return response
if __name__ == "__main__":
print("Starting image capture and inference...")
dataset = curate.fetch_dataset(name="Lucid Camera Data")
camera = initialize_camera()
for image_path in capture_image(camera):
response = run_inference(image_path)
if response.status_code == 200:
print("Inference result:", response.json())
#
# Perform some action based on the inference result, such
# as triggering an alert if a defect or anomaly
# has been detected.
#
# Additionally, we could upload all images that contain
# low confidence inferences of our defect class to our
# Curate dataset for our next round of training:
#
# low_confidence_inference_classes = [
# obj["class"] for obj
# in response["objects"] if obj["score"] < 0.5
# ]
#
# if "defect_class" in low_confidence_inference_classes:
# upload_image(image_path, dataset)
#
else:
print("Error: Failed to get inference result.", response.text)
system.destroy_device(camera)
This sort of real-time inference enables continuous monitoring for defects, making it a powerful tool for quality control. By leveraging the model we’ve trained and deployed on an inference endpoint, images from our inspection cameras can be analyzed instantly to detect surface flaws, misalignments, or other defects as they appear. When integrated with alert systems, real-time detection can automatically flag defective products, notify quality assurance teams, or even halt production to prevent further issues.

Example inference for a pharmaceutical manufacturing monitoring use-case
In the example above, an object detection model is used for pharmaceutical vial defect detection. In some controlled industrial use-cases, it may be worth considering more efficient alternatives to this classic object detection pipeline. The Superb AI team is developing an anomaly detection model that requires only a small amount of unlabeled data of normal, defect-free objects for training. This lets us quickly deploy a functional model which will generate a heatmap to highlight potential defects, as demonstrated in the example below. Stay tuned for this upcoming feature release.
Superb AI Anomaly Detection
Deploying the initial model is just the beginning of building a robust and effective model pipeline. To achieve the best performance, it’s important to continuously refine and improve the model using tools like Model Diagnosis, which helps identify areas where the model is underperforming, allowing for targeted improvements. Enhancing the dataset with new real-world data, using Curate search tools and Auto-Curate to find the most useful and interesting data, and generating synthetic data with Superb Model for rare edge cases can further improve accuracy and reliability. By iterating on the model with these techniques, it becomes more adaptable to real-world scenarios, leading to stronger performance in production.
Want to learn more? Get in touch with us today!
Related Posts

Product
How to Build & Deploy a Safety & Security Monitoring AI Model for an RTSP CCTV Camera
Sam Mardirosian
Solutions Engineer | 15 min read

Product
How to Use Generative AI to Properly and Effectively Augment Datasets for Better Model Performance

Tyler McKean
Head of Customer Success | 10 min read
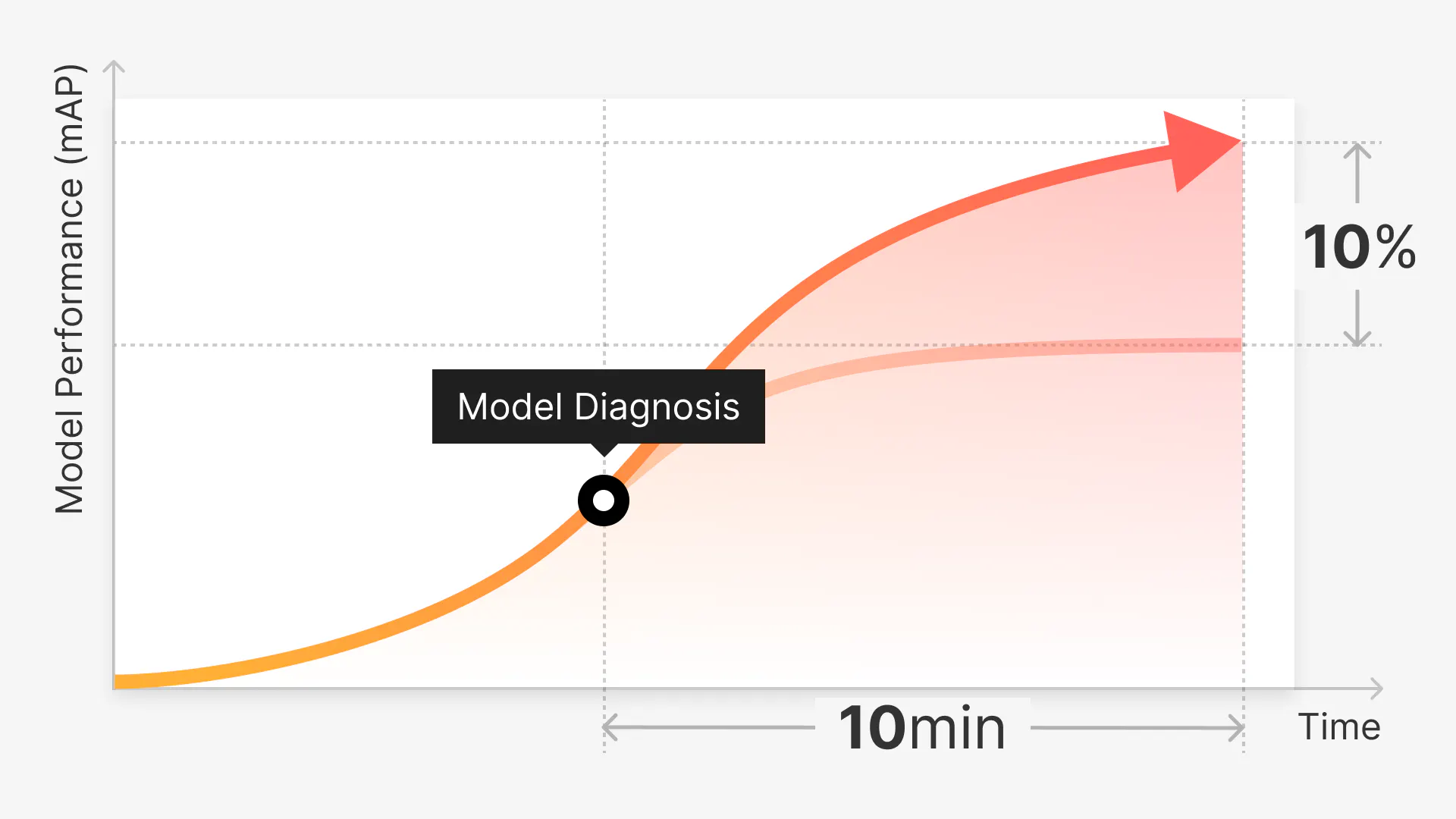
Product
A Guide to Improving Model Performance in Just 3 Hours with Superb Platform’s Model Diagnosis: Experiment on BDD 100K (mAP Improved by 10%)
Tyler McKean
Head of Customer Success | 5 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.