インサイト
機械学習アプリケーションを構築するためのデータラベリングアプローチの手引き

Caroline Lasorsa
Product Marketing | 2022/01/05 | 9 min read

はじめに
コンピュータビジョンや機械学習において、データのラベリングはワークフロー全体の中で重要な役割を担っています。参考までに、データラベリングとは、生の画像、ビデオ、オーディオファイルを識別し、機械学習モデル用に個別にデータへ注釈を付けるプロセスのことで、機械学習モデルはそのデータを使って現実世界に適用できる予測を行います。例えば、自動運転車用に正しくラベル付けされたデータセットは、モデルが一時停止の標識と歩行者を区別するのに役立ちますが、ラベル付けを誤ると、重大な結果をもたらす可能性があります。
機械学習モデルが最高の結果を出すためには、データセットに高いレベルの詳細情報が含まれ、ファイルが正確にラベル付けされている必要があります。機械学習モデルを構築する際、企業は手動または自動化されたアプローチを選択することができます。配膳サービス、外科手術、倉庫ロボットなどのシナリオで人工知能がより一般的に使用されるようになるにつれて、正確なコンピュータビジョンモデルがますます重要になっています。
機械学習モデルを構築する際に、どのようなアプローチを取るべきかを決定する上で、主要な検討事項の1つが人間の関与、別名HITL(Human in the Loop)です。現在のところ、機械学習モデルは完全に自律的に動作することはほとんど不可能であり、正確なモデルを構築するためには、ある程度の人間の監視が必要です。しかし、どの程度人間が関与するかは、そのプロジェクトが目指すアプローチと最終目標によって異なります。
データラベリングの手法は1つだけでは「正しい」「正しくない」とは言えませんが、手動および自動のそれぞれに明確なメリットとデメリットがあるため、深く分け入る前に、ユースケースとプロジェクトの文脈で慎重に評価する必要があります。この記事では、データラベリングの最も一般的な方法を、手動ラベリングと自動ラベリングの2つに大きく分類して検討し、それぞれに固有の利点と制限を探ります。
手動データラベリング
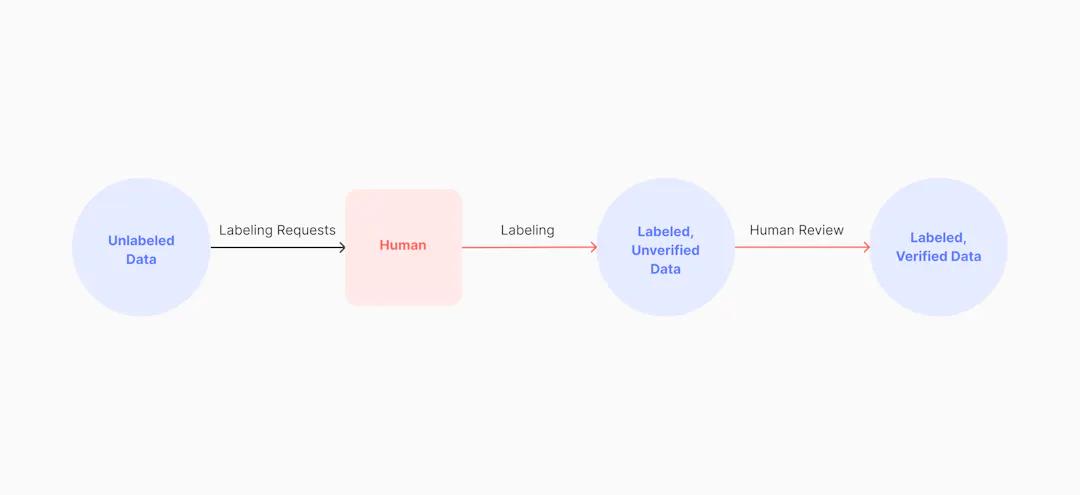
Diagram of the manual data labeling process
おそらく最も面倒なアプローチは、手動によるデータラベリングでしょう。手動ラベリングは、その名の通り、データセットを構築する際に最も高いレベルでの人間の介入を必要とします。このアプローチでは、機械学習モデルの学習データセットを構築するために、人間が各画像やビデオ内のオブジェクトに手動で注釈を付けます。時間とコストはかかりますが、手動によるデータラベリングは、ある種のプロジェクトには利点があります。
画像に多くのデータが含まれ、矛盾や注意点がある場合、訓練を受けた専門家による手動ラベリングが最適なアプローチとなります。例えば、癌患者の腫瘍を識別するために開発されたコンピュータビジョンモデルは、医学的な訓練を受けた放射線科医によって手作業でラベリングされるべきでしょう。この経験則には、斬新な自動化手法とカスタムラベリングAIを含む1つの例外がありますが、それについては最後のほうで説明します。機械学習モデルのトレーニングでは、以下のようなアプローチを取ることができます。
1 - 自社運用
データサイエンティストやエンジニア、機械学習エンジニア、そしてインターンなど、あらゆる人が効果的なトレーニングデータセットを作成するために必要な何千もの画像にラベル付けするための簡単なユースケースを利用することができます。専門家の意見が必要な場合は、自社のチームを活用することが有利になります。Teslaのようなテクノロジー企業大手は、データセットを構築するために自社のチームを利用することがよくあります
自社運用の良い点:
社内のオペレーションチームが、データのラベリングプロセスの最初から最後までを監督することができます。慎重なアノテーションが必要なデータセットを構築する場合、社内チームがその専門知識を活用して、より正確なデータセットを作成することができます。社内でデータセットを構築すると、そのデータセットを熟知し、各ユースケースを理解しているエキスパートに任せることができるという利点があります。多くの場合、データセットは刻々と変化する実世界のシナリオに合わせて常に更新される必要があります。データを社内で管理することは、データセットを迅速かつ容易に更新するための確実な方法です。自動運転車の例では、走行中の車両は常に変化しているため、データセット内の画像も頻繁に更新し、データのドリフトやその他の関連する問題を回避する必要があります。また、データを社内で管理することで、機密情報をソースに近いところで管理することができ、漏洩や侵害のリスクを低減することができます。
制限、限界など:
データセットを社内で管理することで、アウトソーシングが引き起こす可能性のある不都合を抑えることができますが、社内の貴重なリソースが投入されることにもなります。機械学習モデルを構築する上で最も時間がかかるのは、データのラベリングです。社内のデータサイエンティストや機械学習エンジニアが何十万枚もの画像にラベル付けをすると、本来ならもっと優先度の高い急務なことに使えるはずの貴重な時間が削られてしまうのです。もちろん、非常に高価であることは言うまでもありません。エンジニアはハイテク企業で最も高給取りの従業員の一人であり、データのラベリングプロセスはコストがかかり、中小企業にとっては法外なものであるでしょう。限られたリソースしか持たない小規模な新興企業にとって、自社でデータラベリングを行うことは不可能なのです。
データラベリングを手動で行う場合、社内のリソースを利用することだけが唯一の選択肢ではありません。中には、ハイブリッドやクラウドソースのアプローチを選択する企業もあります。これらの方法のいずれを選択するかは、ビジネスのニーズに完全に依存し、他の方法よりも1つの方法を選択する多くの理由があります。
2 - クラウドソーシング
クラウドソーシングの場合、Amazon Mechanical Turkなどのプログラムを通じて、フリーランサーを使ってデータのラベリングプロセスを完了させます。ラベリングは、多数のラベラーによって小規模に行われるため、個人および会社全体の作業負荷が軽減されます。自社で運用するリソースがない企業にとっては、良い選択肢となりえます。
利点について:
クラウドソーシングには利点もあれば限界もあります。企業がクラウドソーシングでデータラベリングを行う主な魅力の1つは、コストです。安価なフリーランサーを利用することは、機械学数エンジニアに頼るよりもはるかに経済的負担が小さくて済みます。また、少人数の従業員でデータセットを構築するよりも、はるかに短時間で済みます。クラウドソーシングによるデータラベリングは、機械学習モデルの構築を効率的に行いたい中小企業にとって魅力的な方法ですが、欠点もあります。
欠点について:
クラウドソーシングに頼れば、大量のデータに迅速かつ安価にラベルを付けることができますが、その精度が常に懸念となります。何百、何千ものソースから集められたデータセットにアノテーションを施す場合、その方法はフリーランサーによって大きく異なるため、データセットに矛盾が生じることは避けられません。例えば、自動車とトラックを正確にラベル付けしようとした場合、ある人はSUVをトラックと見なし、別の人は自動車と見なすかもしれません。ラベルに一貫性がないと、データセットの全体的な精度と性能に影響を及ぼしかねません。また、他者に依存することは、ワークフローの管理や品質保証のチェックを困難にします。
3 - アウトソーシング
第三の選択肢として、データラベリングのアウトソーシングも一般的です。この場合、データのラベリングを手作業で行うために、外部のチームが雇われる事になります。彼らはQAスペシャリストからトレーニングを受け、ラベリングに全力を注ぎます。
良い面:
アウトソーシングは、時間とコストを節約したい企業にとって一般的な手法です。データセット構築の支援を外部チームに依頼すれば、社内の機械学習エンジニアを使うよりもはるかに安く済むからです。外注チームの利用は、大量のデータを短期間で完成させなければならないプロジェクトに有利です。継続的な更新を必要としない一時的なプロジェクトには、アウトソーシングが最適です。
悪い面:
外注のデータラベリングは海外のチームに送られることが多いので、機械学習エンジニアがワークフローをコントロールするのは限界があります。一元化されたチームがプロジェクトに専念するため、一般的に少ない人数で作業することになり、クラウドソーシングよりも遅くなります。とはいえ、クラウドソーシングよりもアウトソーシングの方がより正確なデータセットが得られる傾向があり、このルートを選択する際にその点が考慮されることが多いようです。
自動データラベリング
手動によるデータラベリングとは別に、自動ラベリングもさまざまなタイプのプロジェクトの選択肢であり、多くの企業でより現実的な選択肢となっています。自動ラベリングには様々な形態がありますが、一般的にはAIシステムがRawデータにラベリングするか、アノテーションUI自体にAIを実装して手動プロセスをスピードアップします(バウンディングボックスをセグメンテーションに変換するような)。いずれの場合も、訓練を受けた専門家がデータの正確さと品質を確認するために使用されます。
正しくラベリングされたデータは、システムを通じて供給され、一種のデータパイプラインが形成されます。非常に複雑なプロジェクトやAIの性能を検証するためには人間の手が必要なことが多いため、データのラベリングを完全に自動化することはできませんが、いくつかのツールや手法によってプロセスを大幅に合理化し、スピードアップさせることができます。
1 - モデルアシストラベリング
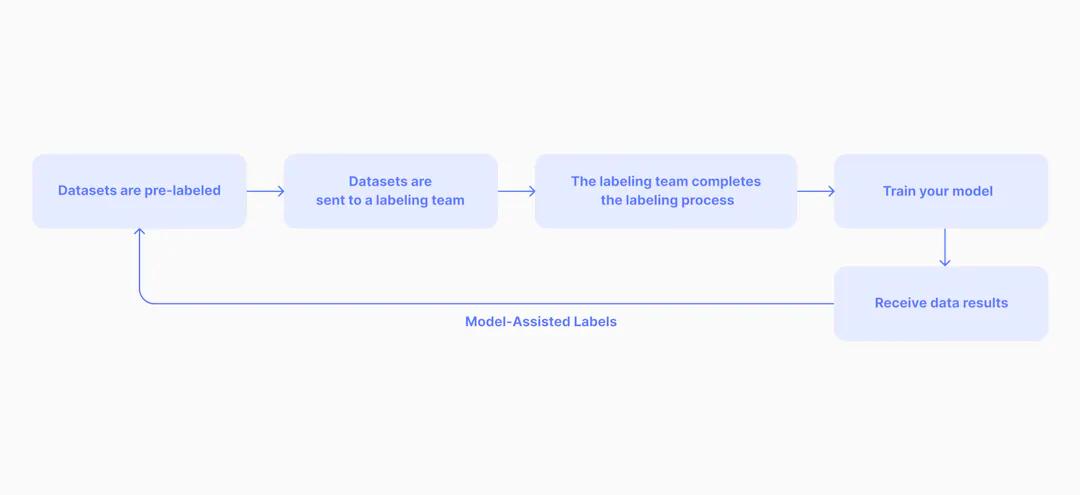
Diagram of model-assisted data labeling tools
モデルアシストラベリングでは、一般的に少量の初期データセットにラベリングを行い、ラベリングのみを目的としたAIシステムを並行して学習させ、この情報をもとにラベリングされていないデータのアノテーションを予測します。あるいは、ラベリングループの中で既存のモデルを使用して予測を行います。その後、人間が事前にラベリングされたデータを監査し、データセットに影響を与える可能性のあるエラーを修正する必要があります(修正したラベルをモデルにフィードバックしながら)。ソリューションによっては、このプロセスをUI内で完了できるものもありますが、事前にラベリングされたデータのアップロードのみをサポートするものもあります(つまり、モデルは既存のテクノロジースタックを使用して予測を行い、お客様はそれらの事前ラベリングをソリューションにアップロードします)。
良い点:
コンピュータビジョンモデルのトレーニングデータセットを構築するためにこの方法を使用すると、理論的には、多くのラベルを迅速に取得するための非常に効果的な方法となります - プレラベルの承認は一般的に手動アノテーションよりも速いためです。さらに、この方法は、主に既存の生産モデルを扱う場合に、モデルの弱点を早期に示す指標となり、プロセスの早い段階で修正する機会を与えてくれます。また、手動ラベリングの大きなボトルネックであった、クラウドソーシングやアウトソーシングによるラベリングを監督するプロジェクトマネージャーの必要性を削減することができます。
欠点:
一方、モデルアシストレベリングには欠点もあります。手作業によるラベリングよりもはるかに自動化されているとはいえ、ラベリングプロセスを監督するHITL要素が必要なのです。その理由は、どのモデルも完璧ではないからです。特定のエラーを解読する人間がいなければ、自動化されたモデルは、人間が簡単に回避できるミスにつながる可能性があります。そのため、自動ラベリングの前または初期段階で、モデルとデータセットの両方が可能な限り正確であることが最も重要なのです。それぞれのエラーを修正するために時間とリソースを使うことはコストがかかりますが、機械学習アルゴリズムを自動化する完璧な方法がない限り避けられないことなのです。多くの実践者が、プレラベルのエラー修正に、単に最初から手動でラベル付けするよりも多くの時間を費やしてしまうことが多いと、報告を受けております。
2 - AIアシストラベリング
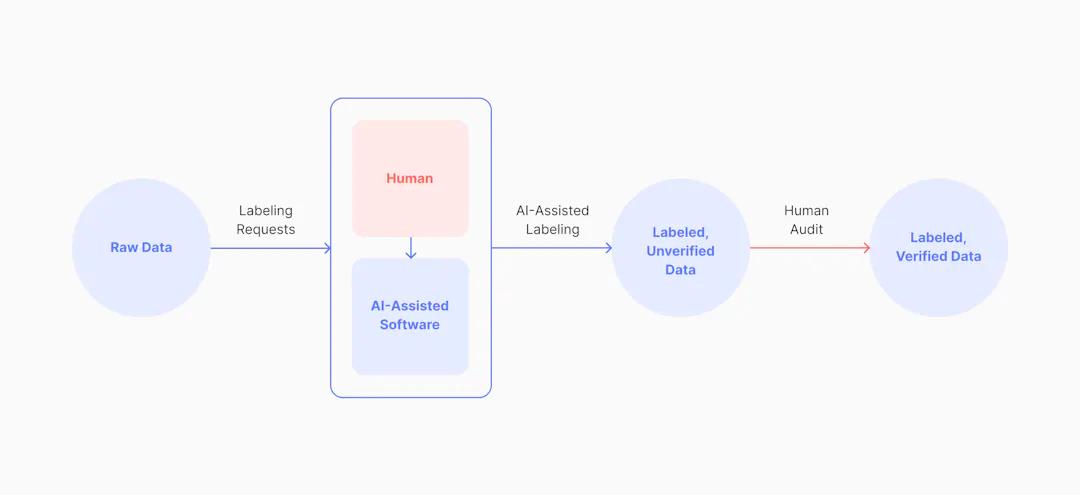
Diagram of AI-assisted automatic data labeling powered by computer vision tools
データラベリングの自動化として、AIによるアノテーションシステムを導入する企業もあります。これは、少ない点数から輪郭を描いたり、過去の経験から予測するなど、ラベラーによる手作業をAIが支援するものです。
利点について:
AIによるラベリングは、人間の監視下にあるデータセットの構築プロセスをスピードアップし、純粋に手作業によるラベリングと比較して、より多くのラベルを短時間で完成させることができることを意味します。例えば、医療分野では、患者さんの病気を特定するためのモデルをより迅速に構築するために、AIによるアノテーションを利用することがあります。十分なラベルが作成された後、AIソフトウェアは、特定の画像やビデオフレーム内のどのオブジェクトにアノテーションを付けるべきかを判断するのに役立ちます。
欠点について:
AIによるラベリングを利用すれば、チームはデータにアノテーションを施し、手作業よりも迅速かつ効率的にモデルを構築することができます。しかし、一般的にはまだ、それぞれのデータに対して相応の人間の関与が必要であり、QAチームやその他の監査グループによるラベルの事後レビューが必要です。
3 - オートラベリングおよびカスタムオートラベリング
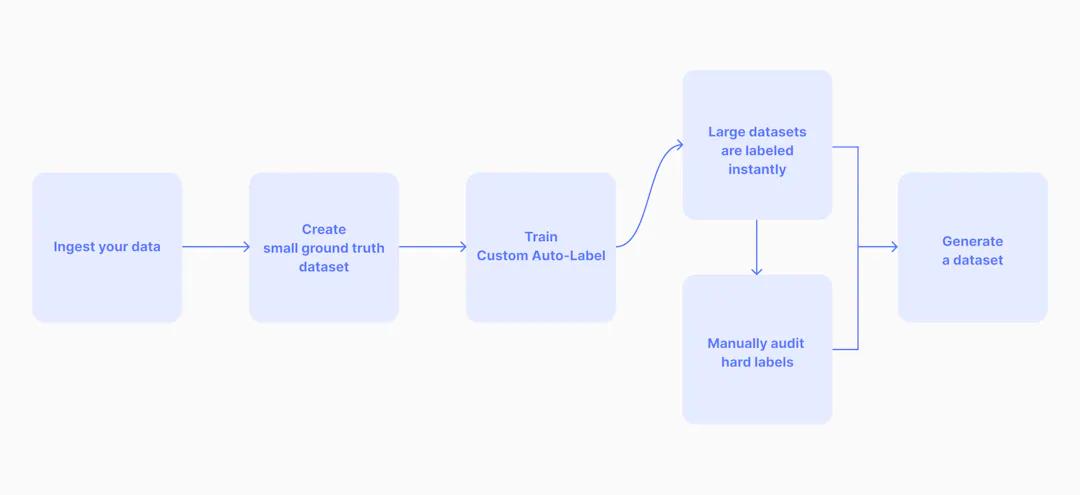
人工知能の世界では、データのラベリングが最も手間のかかる作業であるため、多くの企業が自動化によってそのボトルネックを軽減する方法を模索しています。Superb AIは、ラベリングは難しく、面倒なものでなければならないという概念を覆したいと考えています。Superb AIのノーコード・プラットフォームでは、一般的なオブジェクトのオートラベリングシステムやカスタムオートラベリングシステムを使って、わずか数百枚のラベル付き画像やビデオフレームでグランドトゥルースを達成する能力を提供します。
コモンオブジェクトオートラベル
Superb AIは、お客様自身のラベル付け済みデータを使ってモデルを構築する(カスタムオートラベル)か、弊社のものを使う(コモンオブジェクトオートラベル)かの選択をお客様に提供しています。後者の場合、Superb AIのオートラベルAIは、オープンソースの事前学習済みデータセットを大量に利用し、転移学習と呼ばれるプロセスを通じてモデルにラベル付けを行います。これらのデータセットは、お客様のプロジェクトに類似したモデルやタスクから派生し、当社の共通オブジェクト自動ラベルAIを使用してラベルアノテーションを自動的に生成します。お客様は、既存のデータセットに基づいてラベルを実装し、全体のプロセスをスピードアップしてQAプロセスを合理化することが可能です。
カスタムオートラベル
カスタムオートラベルは、モデルを構築する際に、転移学習以外の柔軟性を提供します。Superb AIは、少数点学習により、お客様のデータセットから少量のラベル付きデータ(オブジェクトクラスあたり約2,000のアノテーション、ただし、もっと少ない場合もある)を使用してモデルを学習します。モデル学習に必要なデータ量は、他のAIと比較して大幅に少なく、データセットのラベル付けにかかる時間、工数、コストを大幅に削減できます。CAL(カスタムオートラベル)は、機械学習分野の新しい企業や、ニッチなプロジェクトに取り組んでいる企業にとって、素晴らしいツールです。また、CALの作成は1時間以内と短時間で完了します。作成が完了すると、不確定性推定AIがデータセットを監査し、誤ったラベル付けを示す可能性のある不確定性の領域を指摘することが可能です。AIが不確かなラベルだけを表示することで、データセットの監査に必要な時間を大幅に短縮することができます。初回の監査後、MLエンジニアはモデル内の矛盾を修正し、再度監査にかけることで、より高い精度を維持することができます。これは、機械学習モデルが高い精度を達成するまで何度も繰り返されます。
現在の技術状況では、機械学習モデルを最初から最後まで自動化することは不可能ですが、いくつかの進歩により、人間の関与を軽減することは可能になっています。Superb AIのカスタムオートラベルは、多くの機械学習エンジニアの障害となっているボトルネックに取り組んでいます。
まとめ
機械学習モデルは、人工知能に不可欠な要素であり、技術の進歩に伴い、より一般的になってきています。データにラベル付けするための正しい手法を見つけることは、構築するプロジェクトの種類、利用できるリソース、達成しようとする目標に大きく依存します。それぞれのアプローチには、機械学習エンジニアが考慮しなければならない利点と欠点があります。
データラベルの自動化への道は明確ではなく、ある程度の人間の監視が必要であることはまだ避けられません。しかし、Superb AI Suiteを使えば、時間とコストを削減する方法があります。弊社のカスタムオートラベルテクノロジーを活用し、より早く、より少ないリソースでグランドトゥルースを達成することで、貴社のAIプロジェクトの時間とコストの両方を節約することができます。Superb AIのオートラベル機能の詳細については、こちらをご覧ください。





Superb AIについて
Superb AIは、エンタープライズ向けのAIトレーニングデータプラットフォームであり、ML(機械学習)チームが組織内でトレーニングデータをより効果的に管理・提供できるよう、データ管理の新しいアプローチを提案しています。2018年に発表されたSuperb AI Suiteは、自動化、コラボレーション、プラグアンドプレイモジュールのユニークな組み合わせを提供し、多くのチームが高品質なトレーニングデータセットを準備する時間を大幅に短縮する手助けをしています。この変革を体験したい方は、今すぐ無料でご登録ください。