インサイト
データラベリングの自動化について

Caroline Lasorsa
Product Marketing | 2022/04/06 | 7 min read
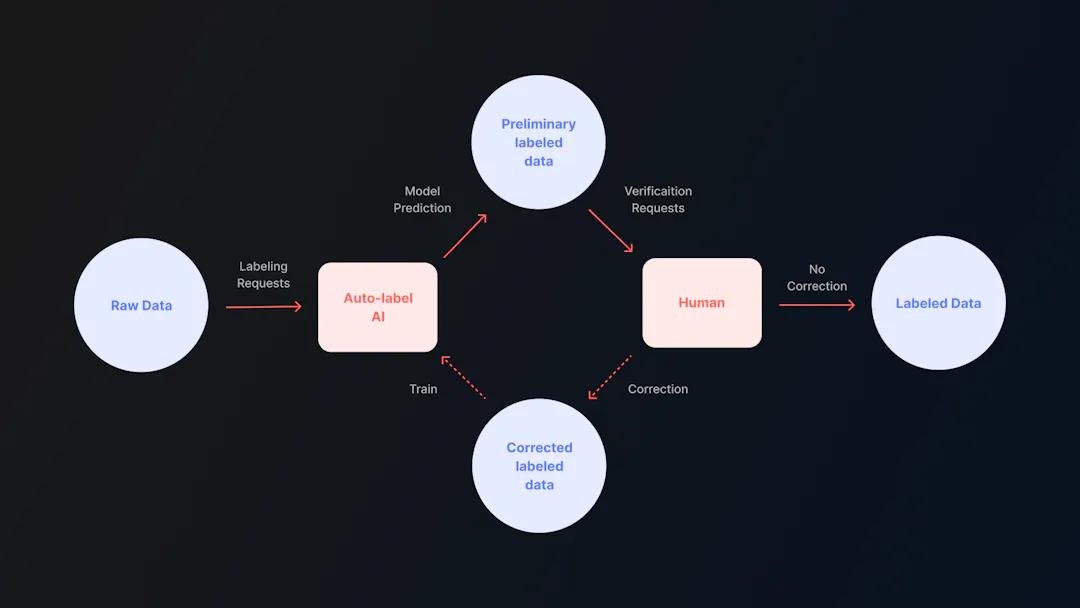
人工知能は、過去10年の間に、日常的にアプリケーションにおける進歩が見られるようになりました。しかし、そこに至るまでには膨大な量のデータが必要であり、そのデータを管理し、実行に移すには多くの労力を必要とします。機械学習専門家は、機械学習モデルをより早く実世界のアプリケーションに実装するために、自動化されたデータラベリングに注目しています。成功するモデルには何千ものデータラベルが必要なことは、機械学習専門家なら誰でも知っています。これを手作業で行うことは、何千時間もの作業、効率化の方法、プロセスの各工程の統括管理を意味します。作業従事者にとっては、データラベリングの自動化は必然となります。
自動化のメリット
機械学習パイプラインにおけるデータラベリングは、大きなボトルネックと速度低下があることで有名です。各画像の重要なオブジェクトに個別にアノテーションを付けるには、大規模なチームが必要であり、時には詳細で時間のかかる大変な作業になることがあります。ラベリング担当者のチームを率いるには、各人がすべての画像について同じ統一されたパターンに従うようにすることが必要です。さらに、社内でラベラーを雇うのは非常にコストがかかるし、外注すると連絡ミスやミスが発生します。このように、手作業によるデータラベリングは非常に面倒な作業です。また、各ステップを通じて、データアノテーションは品質保証の専門家が監督し、間違いを修正しなければなりません。
機械学習プロジェクトに自動化を加えることで、上記のような問題の多くを解決することができます。どんなプロジェクトでも、人間が関与しないものはありませんが、その必要性を最小限に抑えることで、コストを削減し、エラーを最小限に抑え、アウトソーシングの必要性を排除し、エンドツーエンドのオペレーションをより速くすることができます。ワークフローに自動化を導入することで、人工知能の登場以来、機械学習専門家を悩ませてきたボトルネックに対応することができます**。**
自動化を行うタイミング
自動化は、ある種のプロジェクトでは、他のプロジェクトよりも最も理にかなっています。何千ものデータ画像に依存するモデルをトレーニングする場合、自動化しないとほとんど不可能です。人間のみ作業ではスピードダウンとエラーの元なので、プロジェクトが詳細であればあるほど、自動化は有用であります。また、ある種のラベリングプロジェクトは、自動化と相性が良く、この手法を導入することで、より効果的になります。
頻繁な更新を必要とするモデル
機械学習では、実アプリケーションに適用してこそ、そのモデルの良さが発揮されます。多くの場合、これは周囲の環境の変化に適応し、より新しい技術革新を考慮することを意味します。このことを念頭に置いて、機械学習の専門家は、正確な結果を出し続けるために、モデルを更新し続ける必要があります。自動運転車は、継続的な更新が必要なアプリケーションの典型的な例です。車のモデルは変わり、道路標識は更新され、全体的な環境が同じであることはほとんどありません。モデルの更新を怠ると、危険なエラーにつながったり、モデル崩壊と呼ばれる概念で事故につながる可能性があります。
逆に、頻繁にモデルを修正しても、モデルの性能がほとんど向上しない例もあります。モデルに多くのデータを追加すると、より多くのQA(品質保証)と監視、そして追加のトレーニングが必要になります。時には、それに見合うだけの価値がないこともあります。一方、モデルが時間とともに劣化する場合、再トレーニングのスケジュールを微調整することで、パフォーマンスを最適な状態に維持することができます。もし、頻繁に再トレーニングを行うのであれば、自動ラベリングは不可欠です。
さらに、自動ラベリングは、エッジケースを識別し、信頼度を計算するようにプログラムすることができます。モデルが自動的に画像をラベリングする場合、確信度の低いものを特定することで、QA(品質保証)プロセスの時間を大幅に短縮することができます。例えば、Superb AIの不確実性推定ツールは、まさにこれを実現します。エラーが発生しやすいエッジケースを特定し、フラグを立てて人間が検査できるようにするのです。これにより、人間の関与を完全に排除することなく、必要な人間の関与の量を減らすことができます。
自動化におけるラベリングの種類
自動化されたラベリングは、もしあなたのプロジェクトタイプで利用可能なものであれば、最良の選択肢のように感じるかもしれません。それは正しい選択であると思われます。プログラムによるアプローチと相性の良いアノテーション技術は数多く存在しますが、ここではそのいくつかをご紹介します。
画像分類について
多くの取り組みで最も手間がかからないラベリングは、画像の分類です。アノテーターは、データを説明するためにさまざまなタグから選択できるようにプロジェクトをセットアップします。分類自体は、ドロップダウンリストからラベルを選択するだけで、マウスを使ってオブジェクトを描いたり、アウトライン化したりすることはありません。分類は、他のアノテーションプロジェクトのアドオンとして使用することもできますし、単独で使用することもできます。モデルのグランドトゥルースを作成した後、分類されていないデータのオブジェクトを識別するための自動化を追加することができます。

バウンディングボックスの使用
バウンディングボックスもシンプルなアノテーションタイプですが、多くのアプリケーションで非常に有効であることに変わりはありません。ここでは、アノテーターは、ラベル付けされるオブジェクトの周りにボックス形状が形成されるまで、マウスをクリックし、ドラッグするだけです。アノテーターは、ラベル付けされたオブジェクトのすべての側面を含むように注意し、余分なスペースを入れないようにする必要があります。この2つのルールに従うだけで、グラウンドトゥルースデータセットの作成は簡単になります。

画像のセグメンテーションは、多くのデータラベリング・プロジェクトにおいて、必要ですが、複雑なアプローチとなります。ローカライズと分類を組み合わせたセグメンテーションは、特定のオブジェクトの正確なアウトラインを作成することを目的としています。セグメンテーションには、さまざまなアプローチがあります。例えば、キーポイントは、オブジェクトの主要な点を結んで、骨格となるアウトラインを形成します。一方、ポリゴンアノテーションは、画像全体の輪郭を描くものです。ポリラインは、横断歩道など対象物の直線的な輪郭をトレースし、セマンティックセグメンテーションは、それぞれの対象物の形状をトレースしてクラス分けを行います。さらに、インスタンス分割は、同じ対象物であっても、異なる人物を1つのグループとしてではなく、異なるタイプとして区別するものです。これらのラベリング手法はそれぞれ多くの時間を必要とします。つまり、より高速な方法を見つけることが、モデルを迅速かつ効率的に市場に投入するために最も重要なことなのです。
動画ラベリング
多くのコンピュータビジョンのアプリケーションでは、映像が主要な構成要素となっています。例えば、監視カメラでは、窃盗などの不審な行動を特定することができるようになりました。窃盗がどのようなものかを理解するためには、十分に訓練されたコンピュータ・ビジョン・アルゴリズムが必要です。しかし、問題は、ビデオ映像には、より詳細な情報が含まれていることです。動画は静止画像よりも詳細な情報を含んでいるため、ラベリングに手間がかかるのです。各ファイルを個々のフレームで分解するのは面倒ですし、適用可能なフレームを切り分けるには、膨大な時間がかかります。そのため、グランドトゥルースを確立し、特定の物体や人物を素早くラベリングできるようにトレーニングすることが、助けになります。
手動ラベリングを実施するタイミング
自動化は、モデル構築のプロセスを合理化し、全体的な時間を短縮するため、多くのシナリオやチームにとって理想的な方法です。しかし、プログラムによる実装が効率的でないケースもいくつかあります。
グランドトゥルースデータセットの構築
データラベリングの最初の部分は、モデルを学習するための小さなデータのサブセットをアノテーションすることです。この部分は、最初のデータが正しくアノテーションされていることを確認するために、ループ内の人間の介入に完全に依存しています。その理由は、自動化には事前に学習されたデータセットが必要であるためです。多くの場合、外部のデータは役に立ちますが、すべてのユースケースに完璧に対応できるわけではありません。外部のデータセットをモデルに実装することは、丸い穴に四角い釘をはめ込むようなものなので、自社のデータで作業し、人間が最初の作業を行う方が良いのです。
さらに、グランドトゥルースデータセットを構築することは、この段階での各エラーを修正し、次の段階のラベリングに展開することも意味します。モデルを構築する際には、各画像に目を通し、ラベリングの境界がしっかりとしているか、ラベルが正しくつけられているかを確認する必要があります。もし最初の段階で自動化に任せてしまうと、モデルは重要なラベルを見逃してしまい、効果のない不正確なモデルになってしまいます。
さらに、機密情報を扱うには、それなりの障害もあります。医療、金融、セキュリティなどの規制産業では、少なくとも初期段階で人間が監視しなければ、より大きなリスクを抱えることになります。例えば、ある種の癌を検出するモデルのトレーニングは、グランドトゥルースを構築する初期段階において、医療専門家に任せるのが最善です。財務の場合、特に多くの資産を持つ口座では、モデルに欠陥があると悲惨なことになりかねません。同じことが政府モデルにも当てはまります。このようなモデルには慎重な監視がなければ、損害を被る可能性はより大きくなります。
エッジケースへの対応
データセットやモデルの中には、他よりも複雑なものがあります。つまり、自動化されたモデルでは、ラベルの一部を見逃す可能性が高いのです。モデルのほとんどがエッジケースである場合、人間の介入が必要になる可能性が高くなります。より多くの監視を必要とするモデルを自動化することは非常に非効率的であり、その利便性を打ち消してしまいます。また、信頼度の低い画像のQA(品質保証)に人を使うことで、モデルの初期予測より優先されるケースもあります。エッジケースを扱うには、機械では代替できないしらみつぶしの細かい作業が必要な場合が多いのです。
自動ラベリングはあなたのプロジェクトにふさわしいアプローチか?
簡単に言えば、「おそらく」です。自動化は、ラベリングプロセスを加速させ、機械学習の実践者がプロジェクトを迅速に進めるのに役立つことが証明されています。頻繁に更新されるアプリケーションでは、手作業によるアノテーションを省くことで、より簡単に管理することができます。医療分野などでは、医師が手作業でラベリングを行うことで、異常な増殖や病気を特定し、適切にラベリングできる唯一の資格者である医師や開業医の貴重な時間を奪ってしまうこともあります。手作業は、グランドトゥルースデータセットを構築するときと、QAプロセスにおいてのみ必要なことです。この原理は、他のシナリオにも当てはまります。エンジニアのような貴重なリソースをもって、手作業のラベリングプロセスを監督することは、意味がありません。
まとめ
ラベリングを行う際にどのようなアプローチを取るべきかは、プロジェクトやどの段階にいるかによって全く異なります。グランドトゥルースを確立するのであれば、自動化は最初は簡単ですが、最終的には役に立たない結果になります。その近道を選択しても、結局は時間の節約にはならず、不正確なモデルを生み出すだけです。一方、複雑なセグメンテーションの作業は、手動で行うと頭痛の種になるだけで、バウンディングボックスのような複雑ではないプロジェクトでは、簡単に解決できるのです。自動化は、機械学習プロジェクトの迅速化と更新の鍵となります。
Superb AIでは、機械学習やコンピュータビジョンのプロジェクトに自動化を実現することを専門としています。 今後も提供機能を拡張していく中で、データラベリングプロセスを人間らしくすると同時に、シームレスで自動化するための統合された機能の組み合わせをお使いいただけます。ご興味いただけましたら、今すぐ我々にご連絡ください。自動化にむけての一歩をふみだしましょう。





Superb AIについて
Superb AIは、エンタープライズ向けのAIトレーニングデータプラットフォームであり、ML(機械学習)チームが組織内でトレーニングデータをより効果的に管理・提供できるよう、データ管理の新しいアプローチを提案しています。2018年に発表されたSuperb AI Suiteは、自動化、コラボレーション、プラグアンドプレイモジュールのユニークな組み合わせを提供し、多くのチームが高品質なトレーニングデータセットを準備する時間を大幅に短縮する手助けをしています。この変革を体験したい方は、今すぐ無料でご登録ください。