製品
大量のラベル検証:マニュアルQAとより直感的なプラットフォームインターフェースのご紹介

Superb AI Japan
2021/09/02 | 6 min read

データラベリングに最適なツールー ラベル検証機能を刷新し、外観も一新
はじめに
実際に機械学習(ML)システムを構築している方なら、高品質なラベル付き学習データがいかに重要であるかをご存じでしょう。高品質なラベル付き学習データによって、MLチームは強力なMLシステムを迅速に開発し、実運用に移した後のシステムのパフォーマンスを向上させることができます。しかし、本当に高品質なラベル付きデータを入手することは困難です。データラベリングプロセスには、データ収集とリッチ化のためのツールの使用、ラベルの品質保証、データラベラーの管理、実際のモデルにデータを渡すまでのプロセスの繰り返し、さらにモデルインファレンス後のモデルの最適化など、様々なタスクが含まれます。
特に、ラベルの精度を検証することは、ラベル全体の品質を確保するために不可欠です。
• 精度とは、ラベル付けがどれだけ真実に近いか、あるいはデータ中のラベル付けされた特徴がどれだけ実世界の条件と一致しているかを測定するものである。
• 品質とは、データセット全体におけるラベルの正確さのことである。すべてのラベラーの仕事は同じに見えますか?ラベリングはデータセット全体で一貫して正確ですか?これは、何人のラベラーが同時に作業しているかに関係なく、重要なことです。
ラベラーは一人ひとり違うので、検証は不可欠です。また、ラベラーは人間であるため、少なくとも時々ミスが発生します。このようなミスは、結果としてのモデル予測の精度と価値を急速に低下させる可能性があります。しかし、ラベルの検証は必要ではありますが、その場しのぎで行うと時間がかかります(一部の管理者は、ラベルの検証に時間の50%も費やしていると報告しています)。したがって、明確で合理的なレビューワークフローを導入することが非常に重要です。
このような課題を解決するために、ラベル検証のワークフローを合理化する強力な新機能群であるマニュアル品質保証(QA)機能を発表することになりました。また、広範な調査とお客様との会話に基づいて、プラットフォームのUIに施されたいくつかの大きな改良を発表できることを嬉しく思います。視覚的な変更に加え、プラットフォーム内のナビゲーションをより迅速かつ容易にし、データのアップロードプロセスをより明確にすることで、混乱やエラーを低減しています。
マニュアル品質保証(QA)機能のご紹介
今回のマニュアル品質保証では、指定された専門家やチームのメンバーが、(1)完成(送信)したラベルを手動でレビュー、検証、およびフィルタリングし、(2)既存のプロジェクト概要タブや新しいフィルタを通じて検証作業の進捗を追跡できる機能を提供します。これらの作業をさらに詳しく説明しましょう。
**提出されたラベルの承認と却下:**これまでは、提出されたラベルを承認するか却下するかの判断は、純粋に主観的なものでした。マニュアルQAは、定義された承認プロセスを追加することによってラベルの品質を検証し、エラーやミスの可視性を高めるため、将来のモデル品質問題のリスクを軽減することができます。
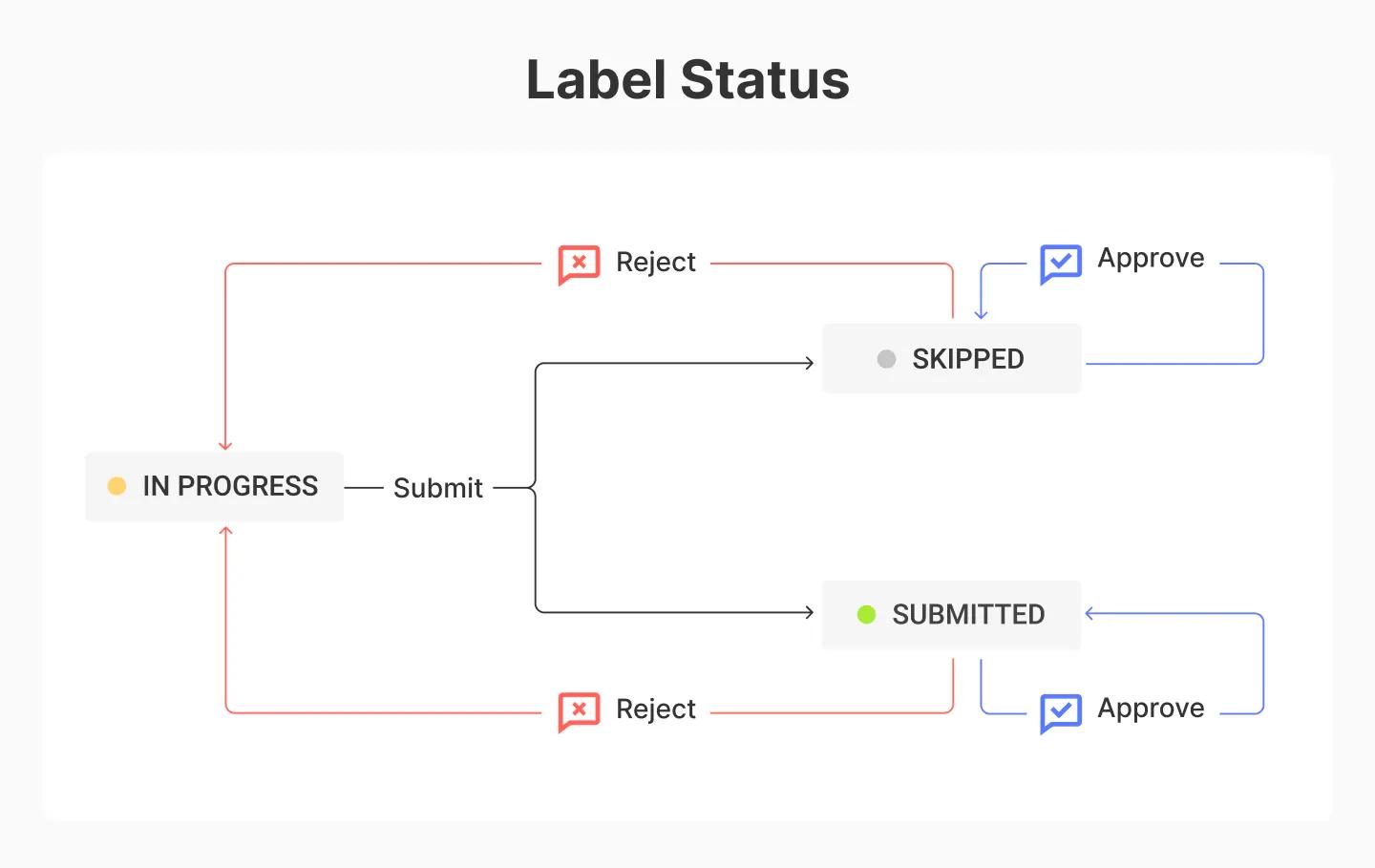
承認プロセスはシンプルですが、一貫して使用することで非常に効果的です。ラベルが注釈アプリから送信またはスキップされたとき、またはラベルリストビューのオプションリストからステータスを手動で変更したとき、レビューする人(通常はマネージャーまたは他のチームリーダー)がラベルをレビューし、送信を承認または却下します。承認された場合、そのラベルは使用可能な状態になります。却下された場合、ラベルのステータスは自動的に進行中に戻され、課題スレッドが作成されます。ラベルは、元のラベル作成者や他のチームメンバーによって再作成され、レビューのために再度提出されます。ラベルは、合格するか、要求された精度を満たすまでこのサイクルを繰り返します。
却下されたラベルの問題スレッドを作成する: ラベルが却下されたとき、レビュアーが同時に問題を診断し、ラベリングチームに適切なアクションを伝えるのは難しいことです。このような問題を包括的に表示し、レビュアーが簡単に確認でき、ラベラーに必要な修正をすばやく簡単に警告できるようなインターフェースがあれば、はるかにシンプルになります。
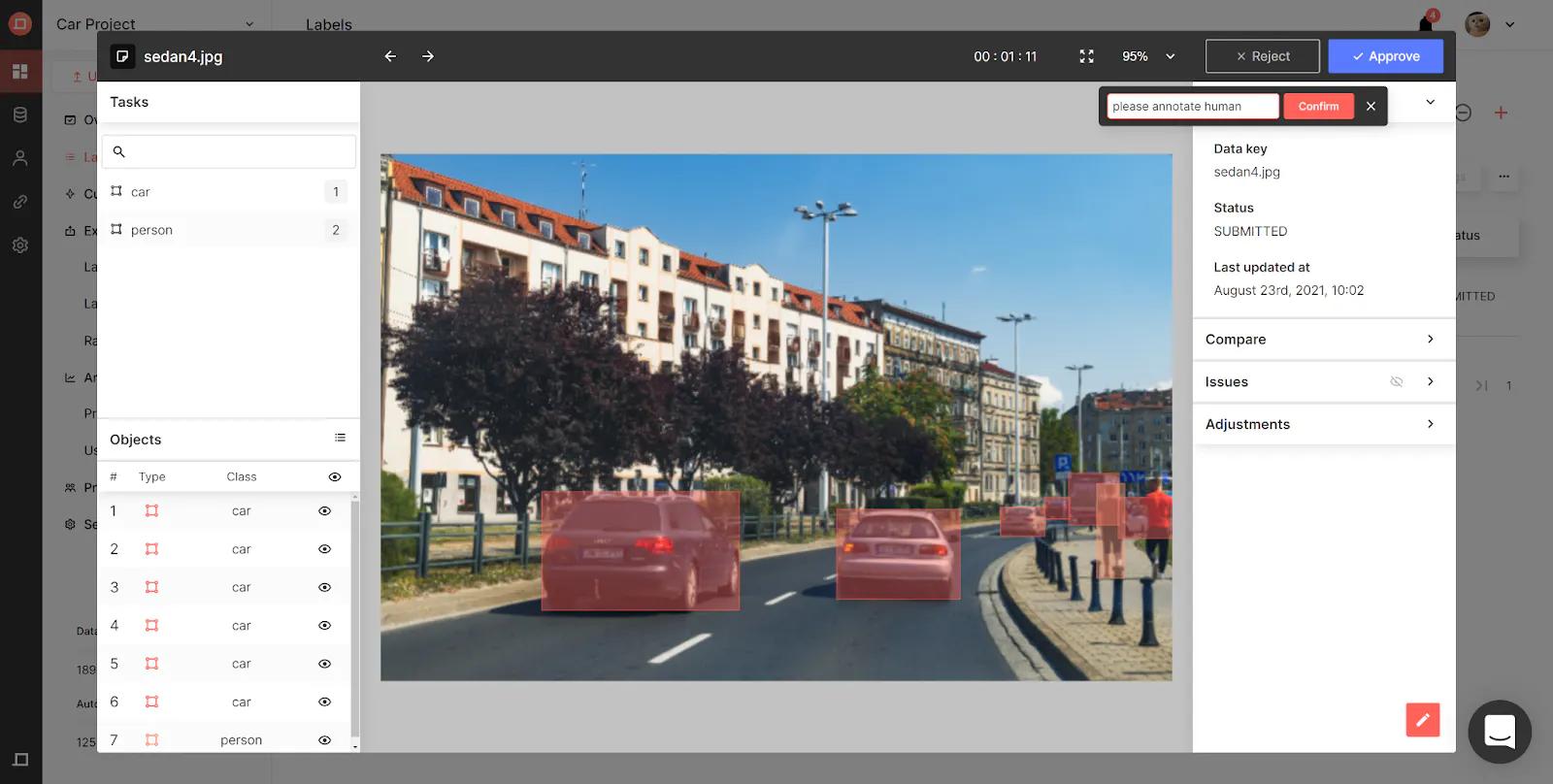
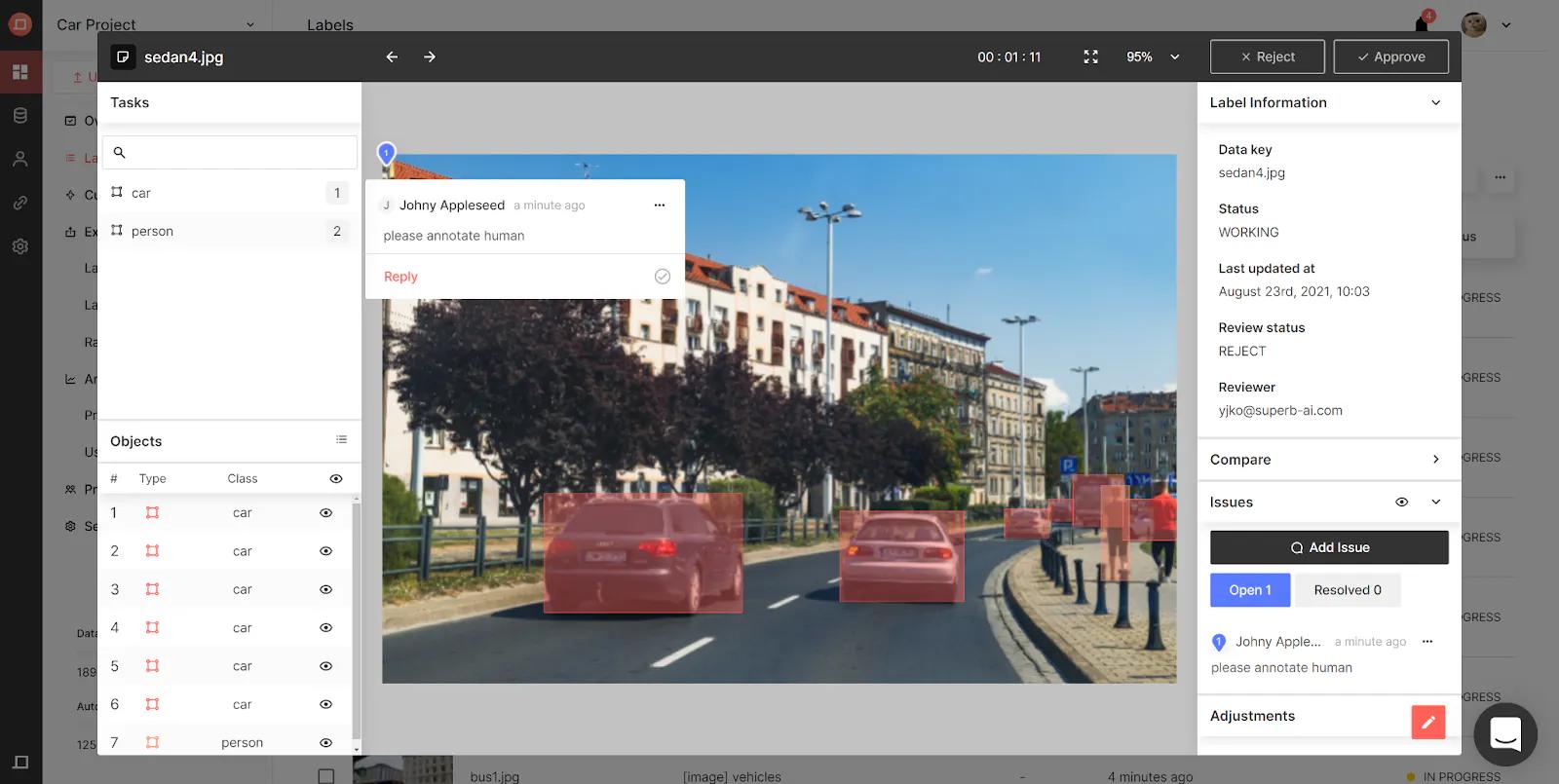
マニュアルQAでは、ラベルを却下する際にレビュアーに問題の詳細を入力させることで、このプロセスを合理化し、表面化した問題が記録されないことが無いようにします。また、課題タブにレビュアーと課題が表示されるため、担当のラベラーに手直しの必要性とその理由を迅速に伝え、却下されたラベルの再提出にかかる時間を短縮することができます。
問題スレッドは、マニュアルQA関連で、または個別に使用できる素晴らしい機能です。1つのラベル内で複数の問題スレッドを開き、解決し、再び開くことができるため、画像を承認申請用に再提出する前に完了する必要がある各修正を追跡し、整理することが容易になります。
レビュー済みラベルをレビューまたはレビュアーでフィルタリングする: 高品質のトレーニングデータセットを構築するためには、適切なラベルが手元にあることが重要です。これまでのお客様との会話から、多くのお客様が保存するラベルを完全にコントロールすることを望んでいることがわかりました。
マニュアルQAでは、レビューやレビュアーによるフィルタリングを追加することで、より効果的にデータをスライスし、プロジェクト管理を行うことができます。この機能は、弊社の他のフィルターや検索機能と組み合わせて使用すると、複数のフィルターを重ねて特定のデータやラベルのセットに焦点を当てることができるため、非常に効果的です。
たとえば、ラベラーのJohnが提出し、マネージャーのTerryがレビューした承認済みのラベルをすべてフィルターにかけ、簡単な抜き取りチェックを行うことができます。また、過去1カ月間にレビュー担当者Bryanが提出した、オブジェクト・クラス「ゾウ」のラベルをすべて却下し、データセット内の「ゾウ」に関する最も一般的な問題をすばやくレビューして理解することができます。例えば、画質が問題であれば、ゾウのデータをもっと探す必要があることを警告することができます。
**プロジェクトの概要タブでレビューの進捗を確認する:**データラベリングチームのプロジェクトマネージャーにとって、どのラベラーがどのタスクを行うかを正確に把握することは、それだけで大変な作業となります。また、ラベリング担当者にとっても、他のラベリング担当者の担当業務を把握し、互いに干渉し合わないようにすることは、同様に難しいことです。
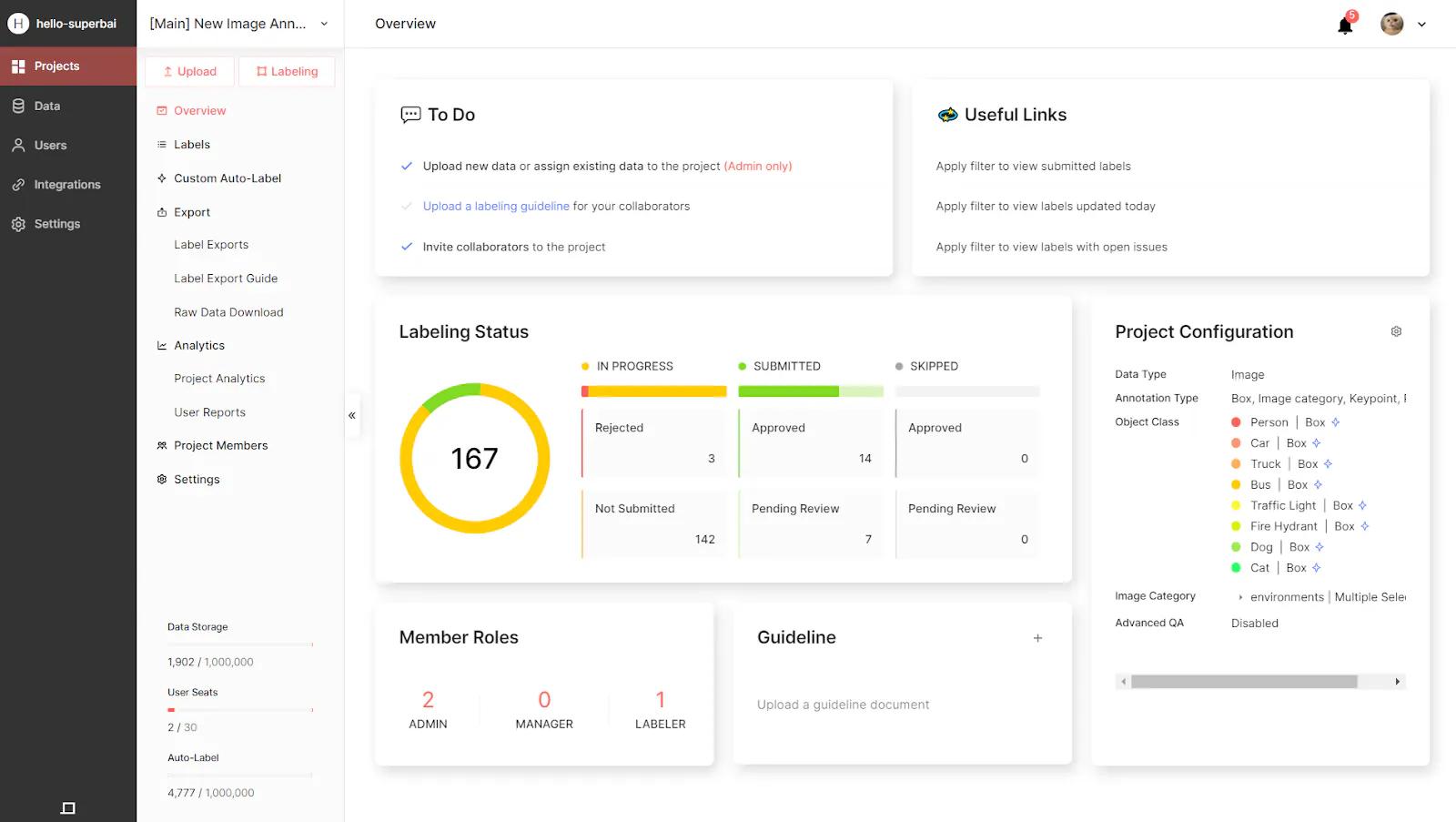
マニュアルQAでは、レビューアクションを含むProject Overviewタブにより、QA作業全体の可視性を高めています。レビューチャートは、以下で構成されています。Rejected(ラベルが却下され、まだ再提出していない)、Pending Review(ラベルが却下され、ラベラーが再提出している)、Approved(ラベルが承認された)、Not Reviewed(ラベルは提出されたがまだレビューされていない)です。
マニュアルレビューによる理想的なワークフロー
このマニュアルQAリリースは、Suiteの3つのユーザーロールの既存のワークフローにシームレスにフィットします。ラベラー、レビュアー、データプロジェクトマネージャ (PM)です。これらの3つの役割は、プラットフォーム内のAdmin/Owner/Managerおよびラベラー権限で確認することができます。
1. ラベルは、最初にラベラー(レビュアーまたはラベラー自身)に割り当てられます。ラベルのステータスは「進行中」です。
2. ラベラーはそのラベルを提出するか、そのラベルをスキップします(そのデータポイントにラベルを貼るのが難しい場合、または画像が[破損している]場合)。ラベルのステータスは「提出」または「スキップ」のどちらかです。
3. レビュアーがラベルをレビューします。ここで、Manual QAの出番です。前のセクションで説明したManual QAの機能を使用して、Reviewerはそのラベルを承認または拒否することができます。
4. ラベルが承認された場合、レビュアーはレビューアクションを承認に更新します。その後、データPMがプロジェクトの進捗を確認することができます。
5. 一方、ラベルが却下された場合、レビュアーはレビューアクションを却下に更新します。そして、レビュアーは課題スレッドを作成し、ラベラーに新しいラベルを提出するように依頼します。
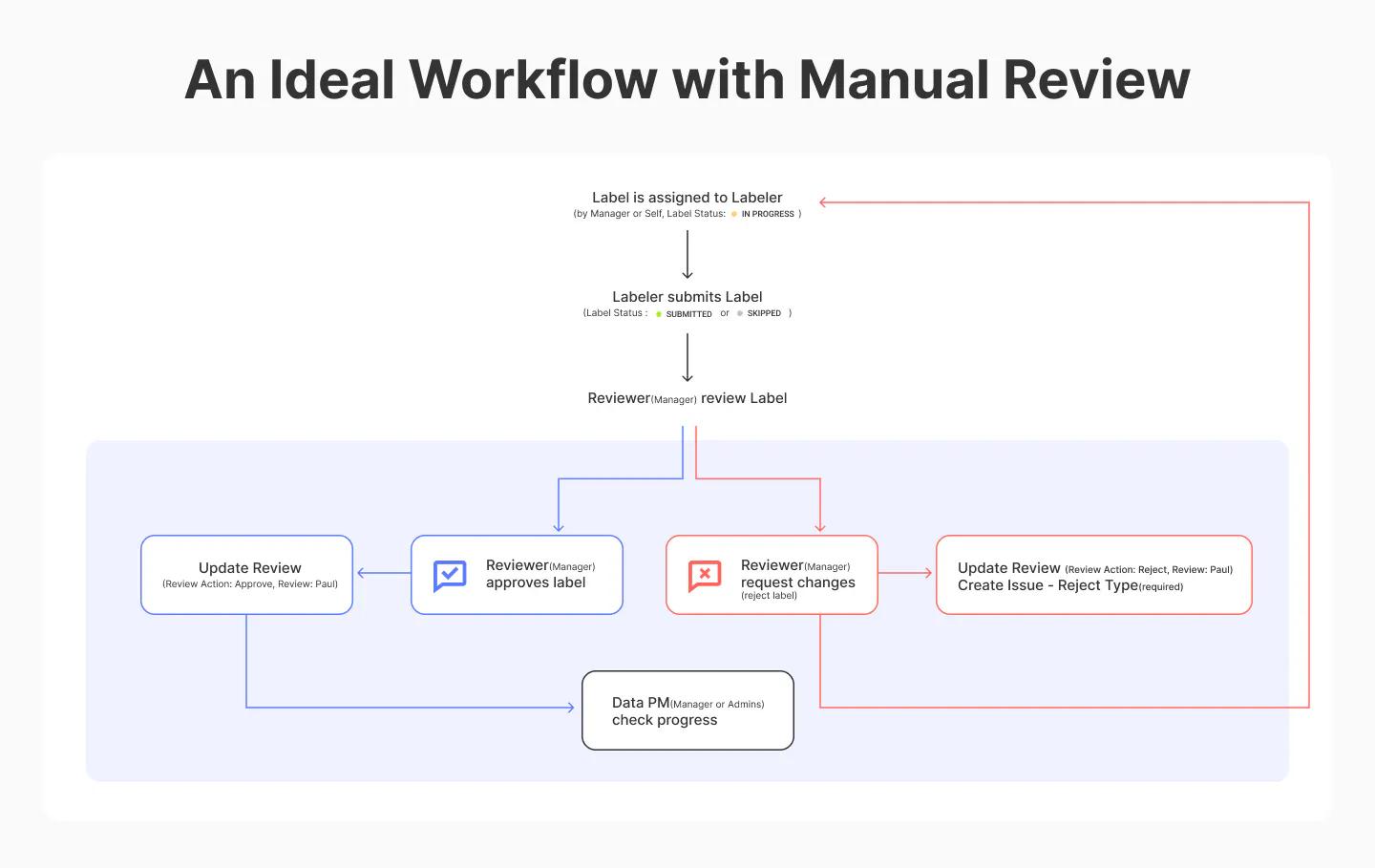
このワークフローは、ラベル付けされたデータの正確性をクロスチェックするための明確なプロセスを提供し、長期的にラベル付けされたデータの一貫性を向上させることができます。さらに、ラベラー、レビュアー、データプロジェクトマネージャーの各レベルでレビューや再作業が必要な作業を把握することで、プロジェクトと時間の管理も強化されます。
より直感的になったプラットフォームインターフェース
この数年間、私たちは多くの時間とリソースを費やして、素晴らしいテクノロジーの要素を作り上げ、出荷してきましたが、それらはやがて一体となって、さらに素晴らしいものになることでしょう。そのためには、プラットフォームの価値と機能を最大限に発揮できるよう、エレガントでシンプル、かつ目的にかなったプラットフォーム・インターフェースを構築する必要があります。そこで、従来のインターフェイスを全面的に見直すことにしました。新しいインターフェースは、効率性を重視した、よりアクセスしやすいミッションコントロールパネルで、必要なワークフローのステップにワンクリックでアクセスでき、より直感的な意思決定や、複雑な海外のシステムを学ぶことなく迅速にプロジェクトを立ち上げ、データセットを提供するチームに必要な効率性を提供します。
まとめ
私たちのお客様は、データ管理ワークフローを合理化し、拡張するためのより多くの方法を求めています。そのため、私たちは初心に戻り、Suite製品をより良くするための方法を模索し始めました。新しいマニュアル QAは、より多くのデータをより速くラベル付けし、ML研究のための高品質なトレーニングデータセットの構築をスケールアップするのに役立つと確信しています。





Superb AIについて
Superb AIは、エンタープライズ向けのAIトレーニングデータプラットフォームであり、ML(機械学習)チームが組織内でトレーニングデータをより効果的に管理・提供できるよう、データ管理の新しいアプローチを提案しています。2018年に発表されたSuperb AI Suiteは、自動化、コラボレーション、プラグアンドプレイモジュールのユニークな組み合わせを提供し、多くのチームが高品質なトレーニングデータセットを準備する時間を大幅に短縮する手助けをしています。この変革を体験したい方は、今すぐ無料でご登録ください。