Insight
An Introduction to Image Classification [+ Superb AI Tutorial]

Caroline Lasorsa
Product Marketing | 2022/01/19 | 8 min read

Introduction
In the world of computer vision, accuracy is critical. If your model isn’t detecting images correctly, then its application in the real world can be rendered useless, or worse, dangerous. A computer vision model that incorrectly identifies objects can lead to disastrous consequences. Alternatively, a well-trained model can expedite workflows, solve medical mysteries, and aid in transportation. Computer vision can change the way our society functions for the better, and as we dive into its capabilities, we realize the importance of building a model that can work inside and outside of the lab.
What is Image Classification?
Building your computer vision model is a sophisticated process that involves several steps, a high-level engineering team, and hundreds to thousands of images. Your model must be trained to identify these images through a process known as image classification (or categorization as we refer to it in the Superb AI suite), which uses an advanced algorithm to assign a label or a tag to identify each individual image. Image classification works by utilizing pre-existing datasets to train your model. Through this process, your model is studying each image at the pixel level, meaning that it is analyzing this information to determine the correct label for your image. As part of the bigger picture, image classification is used to teach your computer vision model patterns and behaviors in the real world. Through careful training, your model can achieve high levels of accuracy before being used for practical applications.
Key Components of Image Classification
Image classification is one small piece of the very intricate machine learning pie. In addition to classification, other key aspects include object detection and object localization. Understanding the difference between these concepts is key in breaking down classification and its importance in machine learning.
Object Localization and Object Detection

In machine learning, there are many different layers in building a sound model. While image classification is one of the most important aspects of building an accurate dataset, object detection and object localization play an equally vital role. In data labeling, we commonly use bounding boxes to outline specific objects in an image. This process is known as object localization. This indicates the specific location of the object within an image as defined by the bounding box, whereas object classification assigns a label to the image as a whole.
For example, a photograph of a single fish underwater might be labeled “fish” as its classification. As soon as a labeler draws a bounding box around the fish, this is the process of object localization, but what if there is more than one object that needs labeling within the image or within several images? This is commonplace in data labeling and refers to object detection.
Think of image annotation as having three overarching themes, 1) image classification, 2) object localization, and 3) object detection. Differentiating between these processes gives us a better understanding of how labeling teams approach different images within a dataset. While classification and labeling a dataset accurately are key components of building your ML model, there are various methods of doing so. Carving out a strategy for classifying your dataset in the first place is key.
Supervised Learning
Image classification requires an algorithmic blueprint to follow to build out and modify datasets. Supervised learning is one of the most notable systems used in computer vision. Here, your model relies on pre-existing datasets as a reference to understand the images. Because this data has already been trained, it is easier for your model to apply what it has learned to new datasets. It sounds simple, but the process of supervised learning requires a lot of trial and error before the model can accurately predict and label the images.
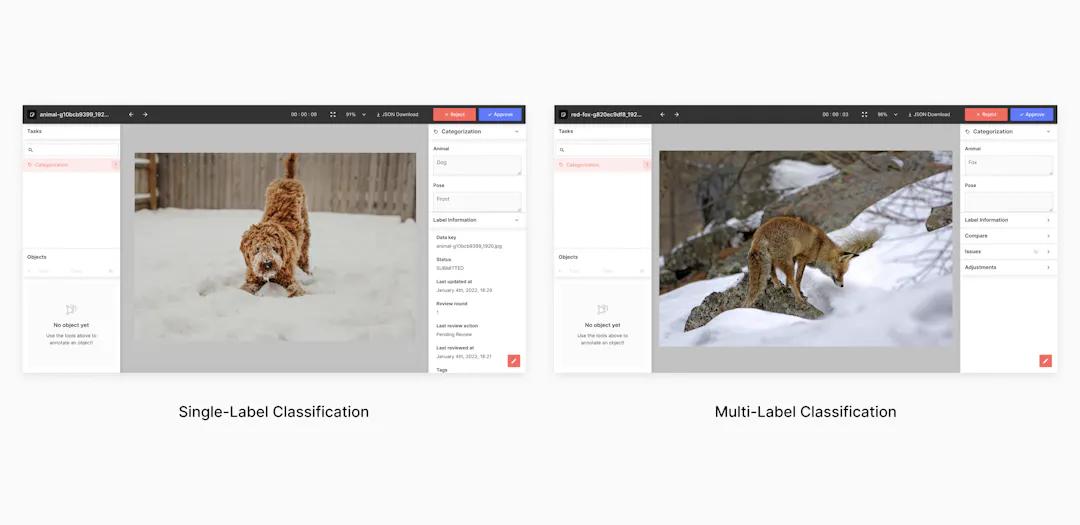
Within supervised learning are two types of classifications: single-label and multi-label. In single-label classification, there is only one annotation within the image. It is the most common type of classification and is the one you will see most frequently. Conversely, multi-label classification occurs in instances where an image cannot be grouped under one specific class. Instead, it is impossible to properly classify the image because it consists of many different objects. For example, a person with health abnormalities may be grouped under multiple classes because of the number of issues they face, outlined in a single image.
Unsupervised Learning
Where supervised learning is dependent on pre-existing datasets, unsupervised learning takes the opposite approach. In these types of algorithms, your model works to draw conclusions about raw data, forming labels derived from the patterns exhibited by your dataset. Your computer vision model must work without human assistance to classify the data, but instead of assigning classes like in supervised learning, unsupervised algorithms work to assign your images into clusters. Through clusterization, your data is assigned to different groups. From here, ML engineers must find their own ways to divide the data into separate classes through different algorithms, including BIRCH, Agglomerative Clustering, and K-Means.
Convolutional Neural Networks
In computer vision, the aim is to train your model to “see” different images and classify them in a way that emulates the human brain. In human development, we learn to recognize the images in front of us by repeated exposure and learned recognition. So too do the machine learning models created by engineers in artificial intelligence. This brings us to convolutional neural networks, or CNNs for short. In this method, deep learning has advanced its approach to act like the neural networks in our own brains and to draw conclusions with little human interference. CNNs are proven to be an extremely accurate approach to machine learning as well as a very efficient one.
Key Image Classification Metrics
If we’re looking to train our models to function similarly to the human brain, then monitoring how well each model performs is of utmost importance. For your model to pass the test and be used in a real world setting, a few things need to be considered, including accuracy, precision, recall, and F1 score.
1. Accuracy
The most basic function measurement in classification metrics is accuracy. Hare, we measure the number of correct predictions made by your model as a proportion of the total number of predictions:
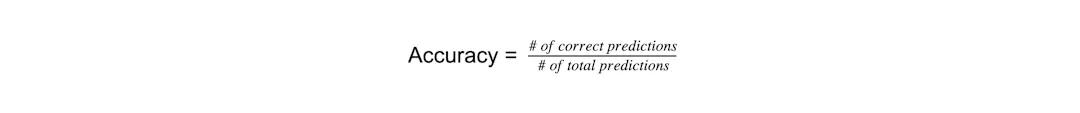
This straightforward calculation is useful in instances where the data distribution between each of the classes in your model are equal. Otherwise, much of the data will be misrepresented in the results. Why? Because it lacks specificity. Accuracy only looks at how many correct predictions your model made without taking into account the types of errors, including false positives and false negatives. Instead, it’s more beneficial to look at other metrics including precision, recall, and F1 score.
2. Precision
Aside from labeling your dataset, the biggest challenge in building your machine learning model is ensuring that it performs accurately. So it’s essential that ML engineers find key indicators to measure and test before letting their model perform real tasks outside of the lab. This brings us to our first metric worth noting: precision. In the world of machine learning, precision is the proportion of positive identifications by your model that are classified correctly. Precision is calculated in the following way”

To solve for precision, we need to look at a couple different factors: True positives, or the number of correctly predicted outcomes in a positive class, and true negatives, the number of correctly predicted positives in a negative class. In addition, we also factor in false positives, or the number in which your model incorrectly predicted that your data belongs to the positive class.
3. Recall
Next, we need to consider a measurement known as recall. Here, we’re looking for the proportion of positive identifications that were classified correctly. The equation looks like this:
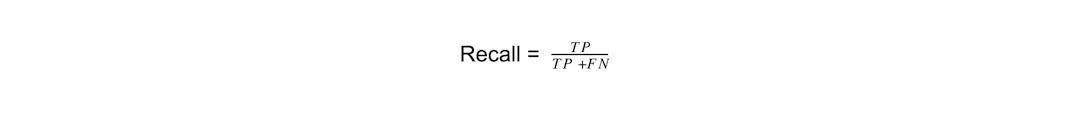
In the above equation, we’re considering the total number of true positives in relation to the sum of true positives and false negatives. Recall and precision are two calculations that always need to be considered by ML engineers when checking for accuracy. Unfortunately, however, both calculations directly affect the other, and not in a positive way. Often, adjusting your model to display better precision negatively affects recall and vice versa.
Because these two measurements tend to butt heads with how one affects the other, ML engineers often look at something known as the F1 score.
4. F1 Score: the measurement of compromise
In math, we learn early on how to compute averages to represent or tell a story about a set of data or a numeric trend. Because precision and recall each influence the other, the F1 score serves the purpose of calculating a single number to represent both values. To solve for F1, input your data into the following formula:

The F1 score provides an invaluable look at your metrics in that it assigns equal balance to both precision and recall. Your F1 score also provides you with information about your precision and recall calculations and further helps you adjust your model in the following ways:
• If your F1 score is high, then both recall and precision are high
• A low F1 score is indicative of low precision and recall
• A medium F1 score tells you that one of precision and recall is low while the other is high
Start Classifying Your Images in Minutes
Now that you’ve learned a thing or two about classification, you’re ready to navigate your own datasets. Understanding the different approaches to data labeling and classification, whether manual or automated, is the first step in building a successful model. Utilizing supervised learning to have full agency over your labels works well for some projects, while implementing unsupervised learning is better for others. Which method you decide is dependent on your project needs and the outcome you’re looking for. To see how easy it is to classify your images in the Superb AI Suite, we’ve provided a step-by-step video tutorial. Whether you plan to label your dataset manually or establish ground truth for your custom automation model, we’ve provided the tools to successfully build your model.
How to Train an Image Classification Auto-Label AI
Finally, let us walk you through the process of creating your very own automation model for image classification on the Superb AI Suite. No matter your experience level, Superb AI makes it easy to build both ground truth datasets for image classification and a custom auto-label model in just a few short steps.
To begin, you’ll need to sign up for a 14-day free trial of our Team plan to get access to custom auto-labeling. Once you’re in, here’s how simple it is to get started.
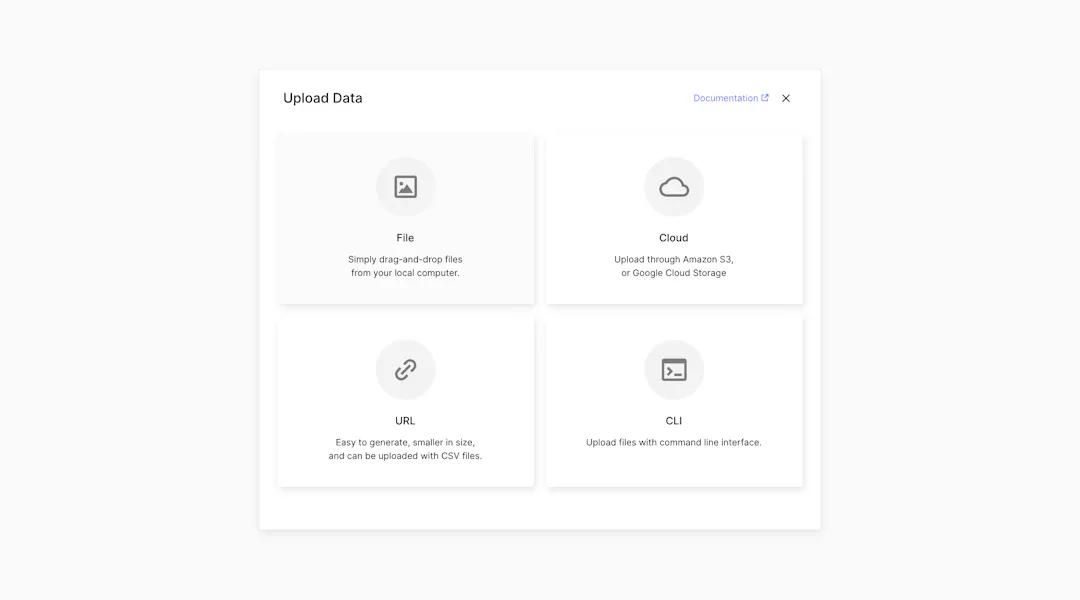
1. Upload your data.
You can either upload pre-labeled data or use Superb AI’s labeling functionality. We recommend having at least 100 labeled images before moving on to the next step.
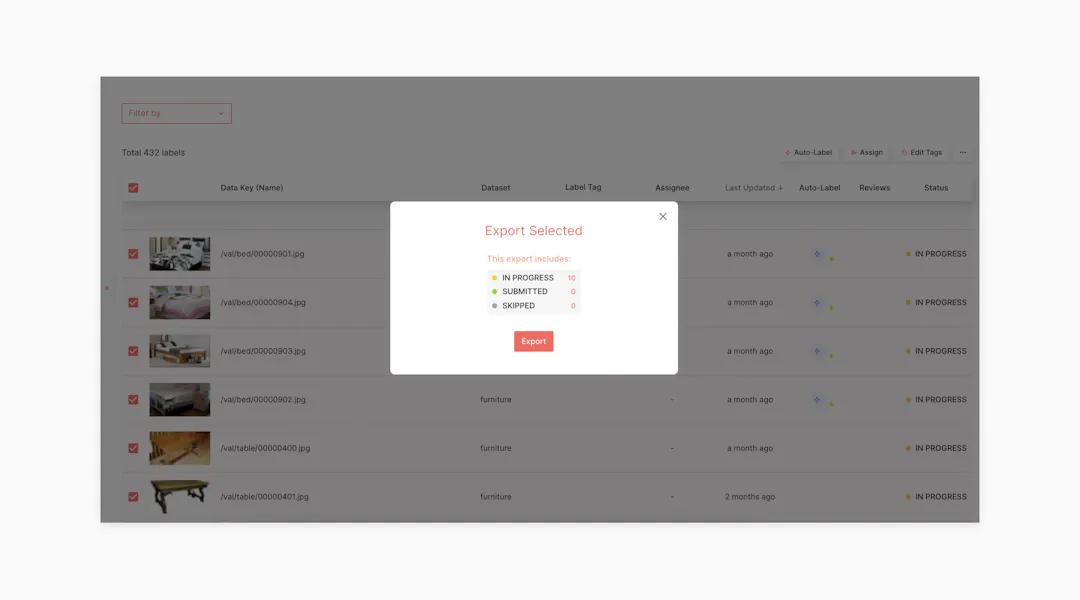
2. Export your labeled data.
To do this, navigate to the expanded menu on the left-hand side of the screen. Click “Labels” and then underneath where it says “Filter by”, select the box, which will check off all of your labels. Then, click on the “...” button on the right of your screen and select “Export.”

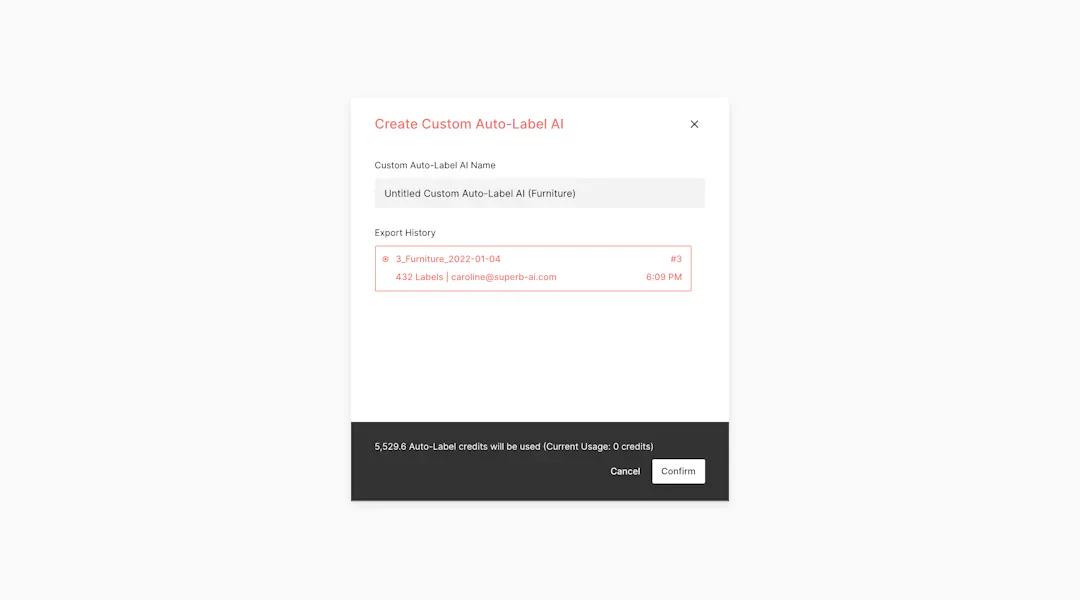
3. Create your Custom Auto-Label.
Do this by clicking on the “Label Exports” function in the Projects sidebar. Then, click on “Create a Custom Auto-Label AI.” Check the expected number of auto-label credits, and then click OK.

You can also create your CAL by selecting “Custom Auto-Label” on the project sidebar. Then, on the right-hand corner, you’ll see “+Create Custom Auto-Label AI”. Select that and then select your desired dataset from your Export History. Click “Confirm” to view the expected number of auto-label credits to be used and the amount you have left. Then click “Confirm” again. Follow this step by clicking “Apply” on the right-hand side of the card. Toggle and expand the card to see an evaluation of precision and recall scores.
4.) Once your CAL is implemented, review the results and continue this process to fix any inaccuracies. We suggest you repeat this process as many times as needed to perfect your model and achieve high-quality ground truth.
The Bottom Line
Image classification is an essential part of building your machine learning algorithm. Your model must be constructed using supervised learning and CNNs or unsupervised learning. The approach you decide to go with is highly dependent on your data, what you need to achieve, and which method is best for your workflow.
At Superb AI, we strive to make image classification a straightforward process in building your machine learning model. We combine the conveniences of automation with the expertise of your team to train highly capable models. With our Custom Auto-Label, we’ve reduced the bottleneck of labeling by hand and implemented easy-to-use technology to expedite your workflow - allowing you to classify your images faster than ever before.
Related Posts

Insight
Three Years of the Few-Shot Object Detection Challenge: Mapping the Global Vision AI Landscape

Hyun Kim
Co-Founder & CEO | 7 min read

Insight
⑪ Germany's Physical AI Moment: Siemens, BMW, and the Robot Unicorn Counteroffensive
Hyun Kim
Co-Founder & CEO | 15 min read

Insight
⑩ Big Tech Physical AI Trends (2): Tesla vs. Amazon Strategy Breakdown
Hyun Kim
Co-Founder & CEO | 10 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.