Product
Superb AI joins the AI Infrastructure Alliance as a founding member to help create the AI/ML Canonical Stack

2021/03/18 | 3 min read

When KH Kim, our Chief Research Officer, and I sat down last year and discussed ways to improve efficiency across the full spectrum of data labeling and data operations, we came to the conclusion that Superb AI should dedicate efforts to automation and agile operations. Also, because KH’s background focuses on advanced techniques around autoML, few-shot and transfer learning, we felt that we could apply a lot of this to our platform and leapfrog a lot of the challenges within data labeling and delivery that still exist to this day.
We initially launched an auto-labeling feature based on a pre-trained model that accurately detects up to 100+ general object classes. We then built and layered on our Uncertainty Estimation AI based on Bayesian Deep Learning to measure the uncertainty of each auto-labeled annotation to speed up active learning workflows, helping teams expedite the discovery of hard labels and manual auditing.
But something was still missing. Our Auto-Label was well received but was not able to address the large minority of our client’s use cases, especially if the images were niche, very subject matter heavy or when camera angles or lighting conditions were unique. We decided that there was another gear we had to shift into in order to provide the kind of transformation we thought this industry needed. For us to bring to market a product we knew would be game changing, we decided to invest all of our time speaking to as many ML practitioners across the industry without bias for domain, company size or operational maturity. This was all for the purpose of validating our product decision with our most valuable resource : our current and future customers.
Ultimately, we identified two main use cases that helped drive the creation of our newest product, Superb AI’s custom Auto-Label :
- Companies or teams that are in early stages of ML development, do not have any models pre-trained on niche or domain-specific datasets.
- Companies or teams well into the ML development and deployment lifecycle have sophisticated pre-trained models and are focused on further improving model accuracy. This means identifying where the model is failing and manually preparing datasets to address those edge cases.
In both scenarios, every team expressed a single point of frustration : delivering and iterating on high quality datasets was taking too long, sometimes months, and costing too much money.
The concept behind our custom Auto-Label was simple : instead of having to create massive ground truth datasets by hand, teams can now build much smaller ground truth or “golden” sets, quickly spin up and train an auto-labeling model with a few clicks and label large datasets in a short timeframe. Coupling the workflow with our proprietary Uncertain Estimation AI and management tools, teams can immediately identify hard labels, build active learning workflows for auditing and deliver datasets in a matter of days.
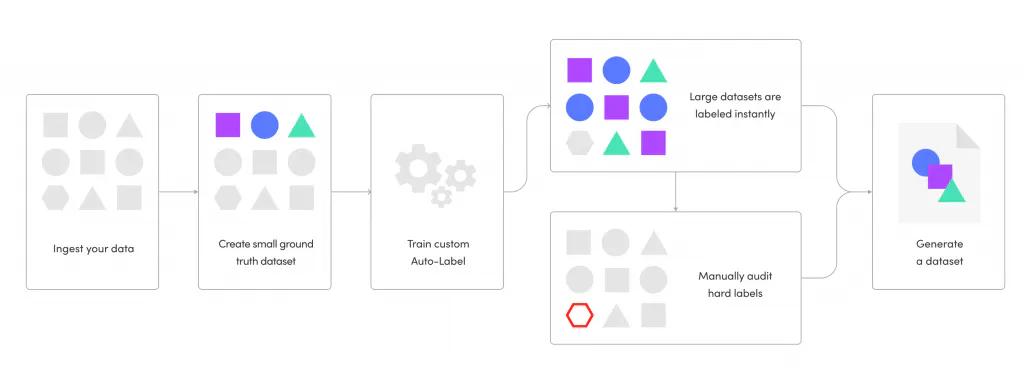
Custom Auto-labeling Process
We were able to achieve this by using a unique mixture of transfer learning, few-shot learning and autoML, allowing the model to quickly learn on small customer-proprietary datasets. And because the application of our CAL has such a broad use case, it can be used to quickly jump start any project, whether it be your initial dataset for training or labeling your edge cases for fine-tuning. This has helped drastically reduce the time it takes to prepare and deliver datasets for our customers.
Our customers have already seen immense benefits from being able to quickly spin up a model trained on their specific datasets for the purpose of rapid labeling. This has not only relieved financial burden but improving the time to delivery has been something that is becoming extremely critical, both for getting projects off the ground and helping with rapid model optimization. As we continue to fine tune and optimize our autoML products, we will continue to introduce more innovative and efficient methods for preparing and delivering training datasets.
Related Posts

Product
How to Build & Deploy an Industrial Defect Detection Model for a Lucid Vision Labs Camera

Sam Mardirosian
Solutions Engineer | 15 min read

Product
How to Build & Deploy a Safety & Security Monitoring AI Model for an RTSP CCTV Camera
Sam Mardirosian
Solutions Engineer | 15 min read

Product
How to Use Generative AI to Properly and Effectively Augment Datasets for Better Model Performance

Tyler McKean
Head of Customer Success | 10 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.