Product
Putting Superb Curate to the Test on the MNIST Dataset: How Does It Work?

Hyun Kim
Co-Founder & CEO | 2023/05/05 | 2 min read
Introduction to Curate
Data is the backbone of machine learning. Machine learning models can only be effectively trained with accurate, comprehensive, and well-organized data. However, collecting and curating data is time-consuming and expensive, often requiring significant investment in time, money, and human resources.
Curate is designed to help machine learning teams streamline the data curation process, making it faster, more efficient, and more cost-effective. With Curate, teams can analyze their training dataset, search based on metadata using queries, and visualize dataset distribution using embeddings projected into two-dimensional space.
Curate offers a suite of features to help machine learning teams optimize their data curation process. With Curate, teams can label less training data and expect similar or even better model performance. They can also build a robust model by curating a validation set that matches their real environment well and easily upload large-scale data and manage it with queryable metadata. With the help of Curate and our embeddings, teams can cluster their data without developing their own embedding models.
Overall, Curate is designed for machine learning teams that need to curate, label, and prepare large datasets for computer vision applications. Its features and capabilities help teams overcome the most common data problems machine learning practitioners face, such as selection bias, class imbalance, and outlier detection. With Curate, teams can ensure that their training datasets are comprehensive, accurate, and well-balanced, leading to more effective machine-learning models and better business outcomes.
Why Manual Data Curation is Such a Pain
Data curation is an essential part of machine learning, but it can be a time-consuming and costly process. Manual curation can be prone to errors and biases and be a constant grind. This is particularly true for computer vision applications, where large datasets are required for effective training and where data quality can significantly impact the machine learning model's performance.
One of the main pain points in manual data curation is the need to select a subset of high-value data that can effectively train the machine learning model. This complex task requires careful consideration of various factors, such as data sparseness, label noise, class balance, and feature balance. Without an automated curation feature, machine learning teams must rely on manual selection processes that can be time-consuming, error-prone, and difficult to scale. In the next section, we introduce our Auto-Curate feature, which automates the data curation process for teams and provides a more efficient, accurate, and scalable solution for machine learning teams.
Introduction to Automated Curation for Computer Vision
Auto-Curate is a feature of our new Curate product that automates the data curation process for machine learning teams. It is based on the AI technology called "embedding," which allows the AI to understand and compare visual similarities between images. Embedding is a foundational technology that powers many computer vision applications, including image clustering, similarity search, and recommendation systems.
Auto-Curate considers four curation criteria to select a subset of high-value data: sparseness, label noise, class balance, and feature balance. These criteria help to ensure that the selected data is representative of the dataset and can be used to build effective machine learning models.
Sparseness refers to the rarity of data in the embedding space. Auto-Curate selects data located in rare positions on the embedding space or data that is rare in the dataset. For example, if a particular type of image only appears once in the dataset, Auto-Curate may select it as a rare data point.
Label noise refers to data likely to be mislabeled or data points located nearby in the embedding space but with different classes. Auto-Curate selects data likely to be correctly labeled and similar to other data points in the same class.
Class balance helps to address skewed class distribution and can undersample frequent classes and oversample less frequent classes. For example, suppose a dataset has a class distribution where one class appears much more frequently than other classes. In that case, Auto-Curate may select more data from the less frequent classes to balance out the distribution.
Feature balance considers the importance of metadata or attributes of each image and samples data evenly in the embedding space. For example, suppose a certain attribute is very important to the machine learning model. In that case, Auto-Curate may select more data points with that attribute to ensure it is well-represented in the dataset.
With Auto-Curate, users can easily curate a dataset of unlabeled images with even distribution and minimal data redundancy. It can also curate only images that are rare or have a high likelihood of being edge cases, or only images that are representative of the dataset and occur frequently. The Auto-Curate feature helps to reduce the manual work of curation and ensures that machine learning teams can build more effective models with accurate and well-curated datasets.
Example Results: Applying Auto-Curate to the MNIST Dataset
Introduction to the MNIST Dataset
The MNIST dataset is a classic example of a computer vision dataset used for training and testing machine learning models. It contains 70,000 images of handwritten digits from 0 to 9, each image being 28 by 28 pixels in size. Despite its small size and simple classification task, the MNIST dataset is still widely used in the industry to benchmark machine learning models.
Analyzing the Dataset Distribution Using Embeddings
One of the first steps in using Auto-Curate is to analyze the distribution of the dataset using embeddings. Embeddings are a powerful tool that allows us to understand the visual similarities between images. They encode an image as a vector in a high-dimensional space, where similar images are located near each other, and dissimilar images are located far apart.
To analyze the distribution of the MNIST dataset, we use the BEiT embedding model. We concatenate the embedding vectors for each image in the dataset and project them into a 2D space using t-SNE. This allows us to visualize the distribution of the dataset in a scatter plot, where each point represents an image, and the color indicates the digit label.
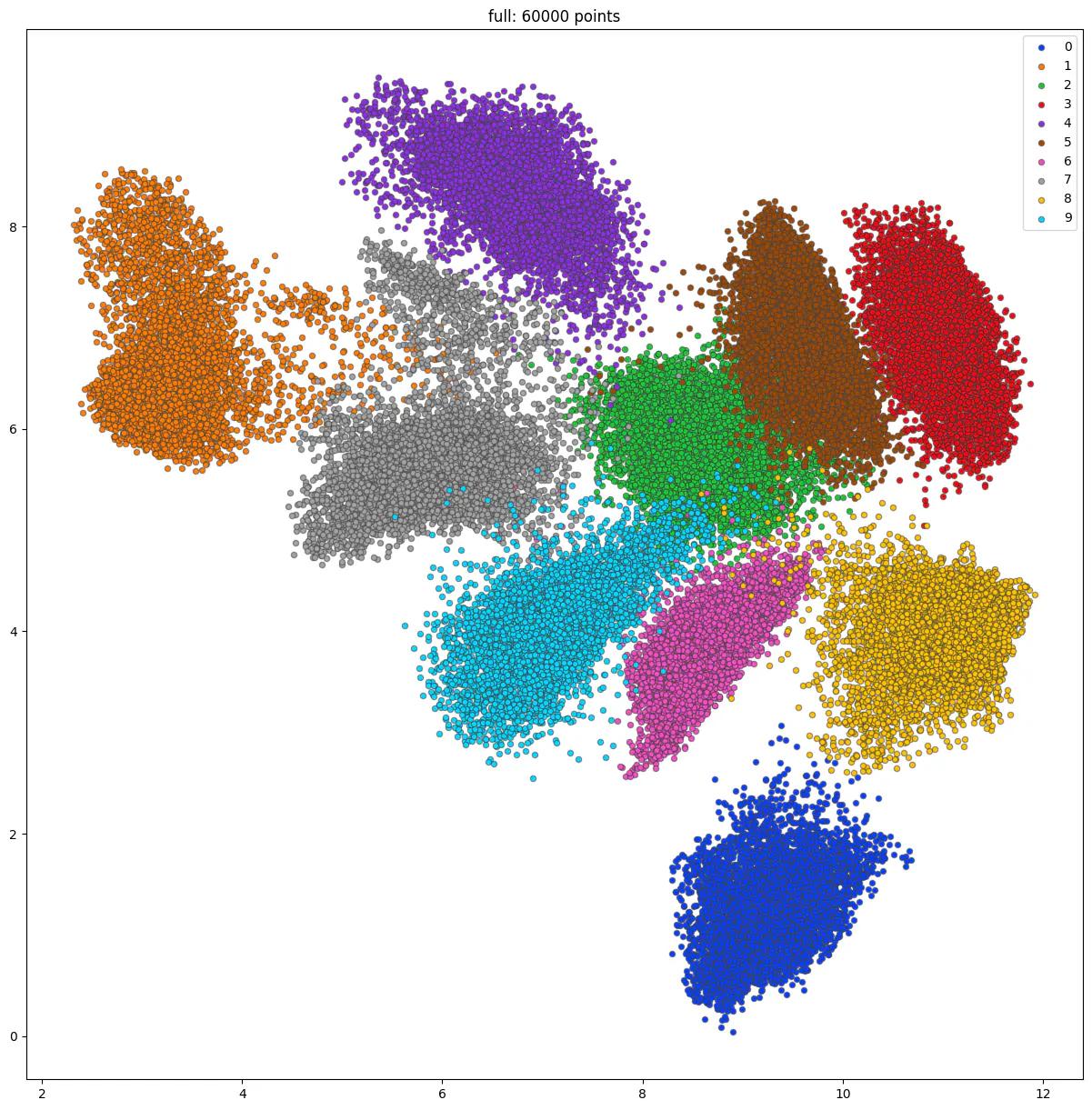
Embedding Visualization of MNIST dataset. Each point represents an image, and the color of the point represents which of the ten-digit classes each image belongs to.
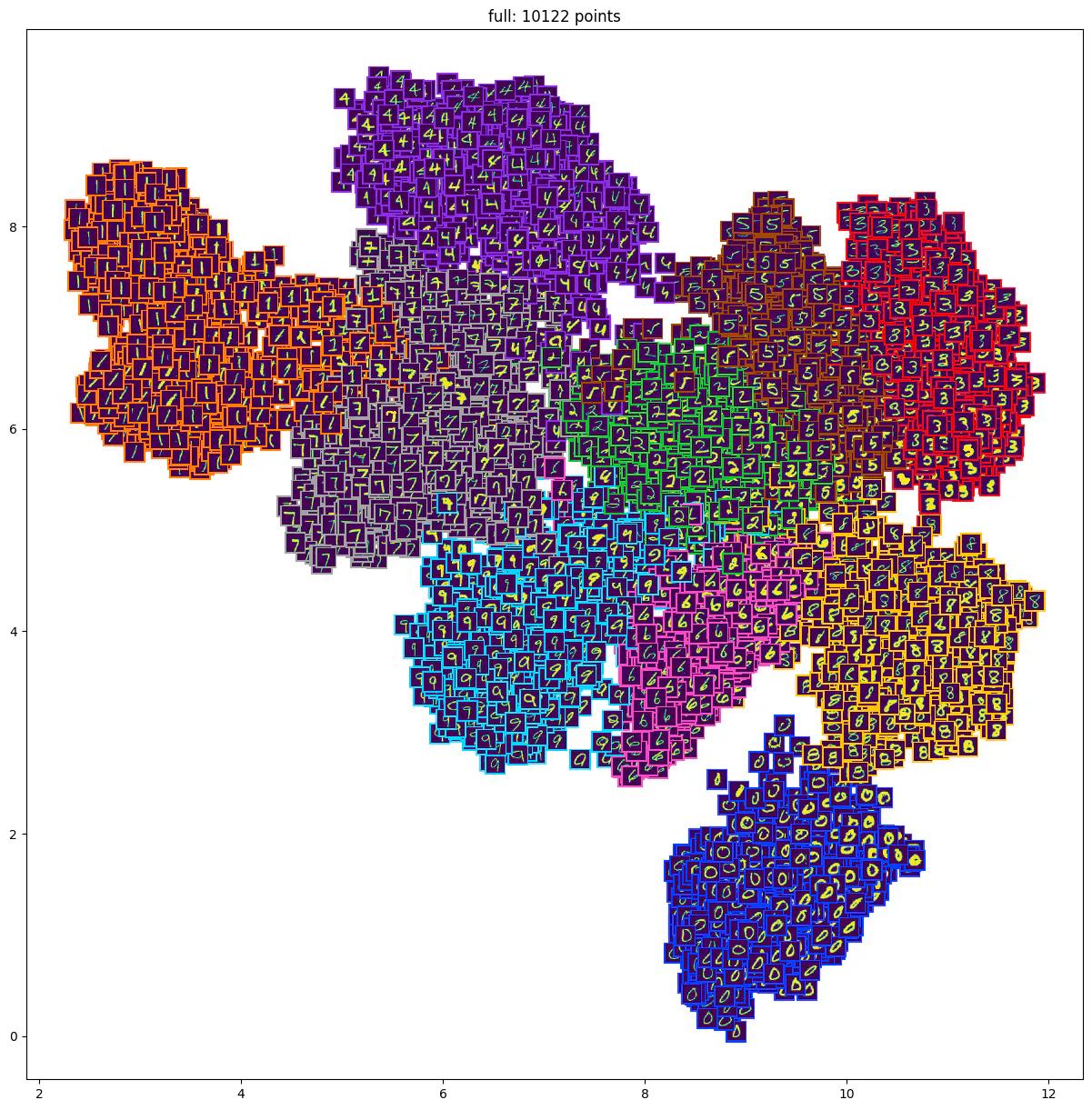
Embedding Visualization of MNIST dataset. Sampled approximately 10,000 images and visualized the image thumbnails.
When analyzing the scatter plot of the 2D embedding values of the MNIST dataset, it is immediately apparent that the images are grouped into distinct clusters based on their class labels. Images belonging to the same class tend to be located close together in the two-dimensional plane, indicating similar embedding values. This is due to the fact that image embeddings are designed to capture visual similarities between images, such as background, color, composition, and angle. As a result, visually similar images have similar embedding values and are located closer together in the two-dimensional plane.
In addition to these class-specific clusters, there are also images located in the region between two or more clusters. These images represent cases that are difficult to classify into one class, as they share visual similarities with multiple classes. These images serve as valuable data points when training machine learning models, as they represent the edge cases that are often challenging for models to predict correctly. By including these images in the training set, machine learning models can be more robustly trained to predict and detect rare corner cases well, improving accuracy and performance.
Overall, the scatter plot of the 2D embedding values of the MNIST dataset provides valuable insights into the visual similarities between images and highlights the importance of including edge cases in the training set for optimal machine learning model performance.
Selecting the Training Set with Auto-Curate
After analyzing the distribution of the dataset, we can use Auto-Curate to select a subset of high-value data for training and validation. When the Auto-Curate algorithm is initiated, our system first clusters the embeddings based on similarity and then selects images representative of each cluster. For the purpose of curating the initial training set, we believe it’s a good practice to create a well-balanced dataset in terms of both the annotated “class” and the embedding values. Also, at this initial phase, we do not suggest including too many edge cases as it may throw off the model training. Therefore, the selected training dataset is a subset that is representative of the entire dataset, making it useful for training initial machine learning models.
In the example case of MNIST below, we have Auto-Curated a subset of 1,000 images for training. The selected subset has an even distribution of digits and minimal data redundancy. This means that the selected subset contains a representative sample of all digits and avoids having too many similar images in the subset, and also avoids selecting too many rare edge-cases that may be difficult to learn.
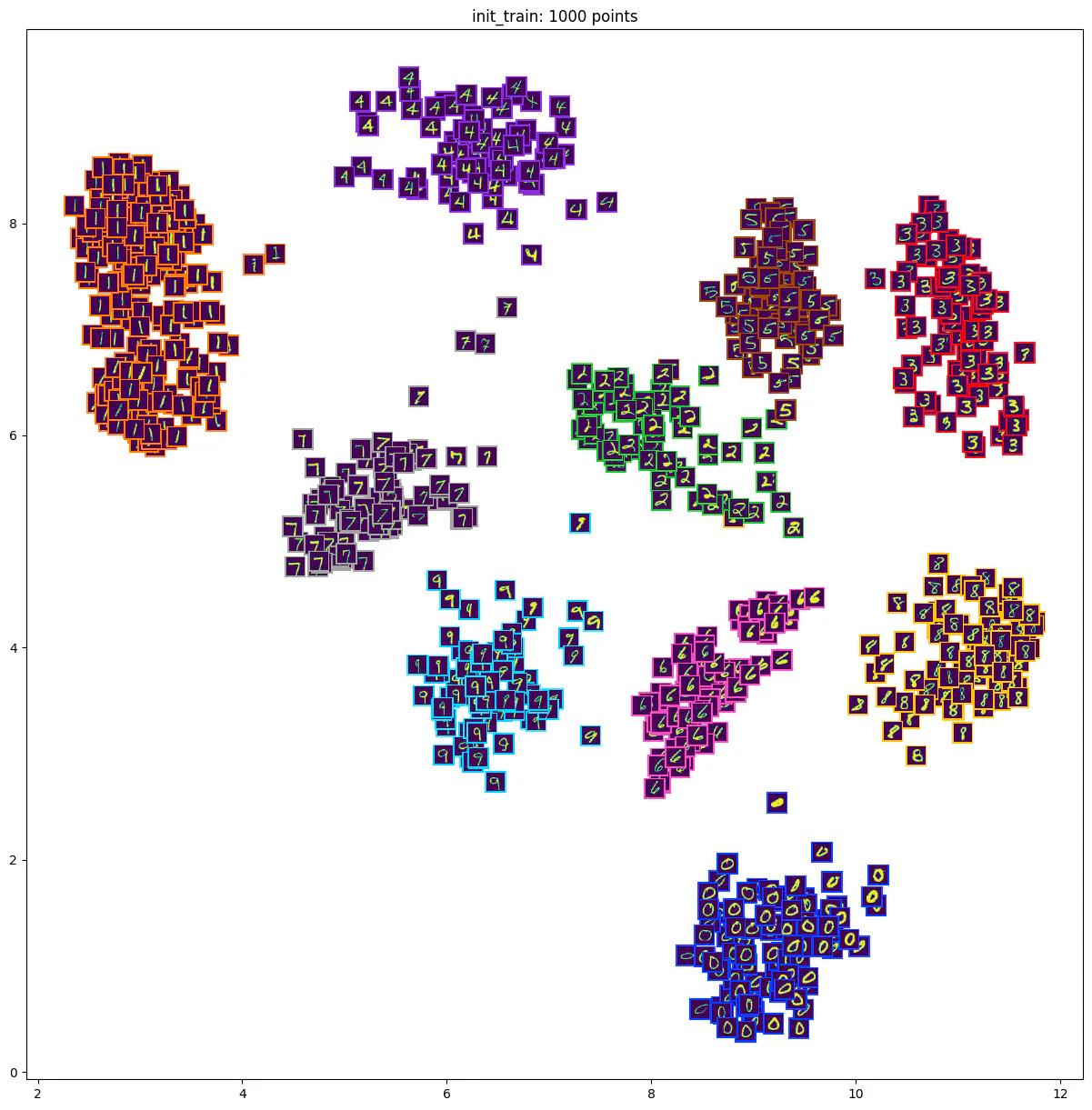
Embedding visualization of curated training set on the MNIST dataset
Selecting Edge-Case Samples with Auto-Curate
In addition to selecting a representative subset of data for training and validation, Auto-Curate can also be used to select edge-case samples that are rare in the dataset. These rare samples are the images that are difficult for the model to learn and often get incorrect output predictions, thus lowering its accuracy. By curating these samples, a user can further train a model to be more robust to edge-case scenarios, which is very important for a model to be successfully deployed in the real world.
To select edge-case samples with Auto-Curate, we configure our curation algorithm to put a higher emphasis on the “sparseness” criteria, meaning that the algorithm will select cases that are further away from other data points in the embedding space. We select images located in a rare position on the embedding space or have a high likelihood of being edge cases.

Example images of Digit 4 and Digit 7 classes that were selected. These images have a high sparsity factor and represent rare edge cases

Example images of Digit 4 and Digit 7 classes that were selected. These images have a high sparsity factor and represent rare edge cases
Including rare edge cases in the training and validation sets is crucial to ensuring a machine learning model can make accurate predictions on real-world data. This is because these edge cases are often the ones where the model has difficulty making the correct prediction due to their rarity. However, including too many edge cases can lead to overfitting, so it's important to strike a balance between including enough edge cases and not overloading the model.
To select these rare edge cases from the dataset, Curate's Auto-Curate feature uses an AI-based curation algorithm based on embeddings. The algorithm selects data points that are located sparsely in the embedding space or are rare in the dataset. These data points can be difficult for the model to learn from and are often the ones that are misclassified when a model is deployed. By including these data points in the training and validation sets, the model can learn to better predict and classify these rare cases.
It's important to note that while including rare edge cases is important, it's also crucial to include a sufficient number of examples of the more common cases in the dataset. This ensures that the model has a strong foundation on which to build its predictions. By including rare edge cases in the training and validation sets, a machine learning model can become more robust and accurate in making predictions on real-world data.
Handling Mislabeled Data with Auto-Curate
One important thing to note when using Auto-Curate is that the result of edge-case curation may sometimes include mislabeled data if the dataset is not perfectly labeled. This is because, given that the model considers all labels as ground truth or perfectly labeled, a mislabeled case, such as a digit that is mislabeled as another, is considered a "rare case" to the Auto-Curate algorithm. These mislabeled cases can be easily spotted in the scatter plot of the embedding space, as they are located far away from the cluster of their true label.
To handle mislabeled data with Auto-Curate, we can use the label noise criterion. This criterion is based on the assumption that if a data point is located near other data points with different labels, it is likely to be mislabeled. By selecting these data points, a user can easily and quickly correct the labeling errors and add them to the training set. By selecting edge-case samples for further training, users can improve the performance and robustnessof their machine learning models.

Examples of edge-case images that have a relatively high probability of being mislabeled
Upon examining the data, it is evident that some of the edge-case images that are classified as “6” or “9” are mislabeled. It may be possible for a human auditor to identify the correct label in some cases, while it may be more difficult in others. In such cases, a user may choose to re-classify the images with the correct label or remove them from the training set altogether, depending on their specific use case and data requirements. Such mislabeled cases can also be used to further train the machine learning model to be more robust and accurate in identifying such cases in the future.
Expanding the Capabilities of Your Machine Learning Models with Curate
Curate's Auto-Curate feature is just one of the many tools that our product offers to improve the accuracy and robustness of your machine learning models. With its powerful AI-based data curation features, including dataset distribution analysis, edge-case curation, and label noise correction, Curate makes it easier and more efficient for machine learning teams to curate their training datasets.
If you want to learn more about Curate and how it can help you optimize your ML models, we encourage you to contact our team!
Related Posts

Product
How to Build & Deploy an Industrial Defect Detection Model for a Lucid Vision Labs Camera

Sam Mardirosian
Solutions Engineer | 15 min read

Product
How to Build & Deploy a Safety & Security Monitoring AI Model for an RTSP CCTV Camera
Sam Mardirosian
Solutions Engineer | 15 min read

Product
How to Use Generative AI to Properly and Effectively Augment Datasets for Better Model Performance

Tyler McKean
Head of Customer Success | 10 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.