Product
The Ultimate Guide to Using Superb AI's Custom Auto-Label

2021/10/20 | 8 min read

Quality Ground Truth and Proper Training Iteration For Speed And Accuracy
Superb AI's Custom Auto-Label is a powerful tool that can drastically decrease the time it takes to build and iterate on datasets. With such intelligent automation, manually preparing large datasets will become a thing of the past.
However, as simple as it is to build a Custom Auto-Label tuned to any specific use case, this guide will help provide pointers around building optimized ground truth datasets and a recommended workflow to ensure efficiency.
Labeling Paradigms
Data labeling is an integral part of every machine learning (ML) project. Given the data-hungry nature of existing supervised learning models that are dominating the current market, a systematic approach to building high-quality labeled datasets is fundamental for the development and deployment of ML models. Typical approaches fall into two categories when building a training dataset for ML models: manual and automatic.
Manual labeling techniques are intuitive and straightforward to implement. They can incorporate human domain knowledge (subject matter expertise) to attach labels to specific datasets. They work well in scenarios that require a high level of reasoning to infer a label (medical notes, legal documents, etc.). However, they are expensive and time-consuming to scale as the number of your ML models increases. This is because the labeling cost is linearly proportional to the number of images. As ML teams transition from the proof-of-concept phase to the production phase, the accuracy requirement for model performance increases, thereby requiring an exponentially higher number of data (and labels).
Automatic labeling programmatically streamlines the creation of labeled training datasets. As a result, they are cost- and time-efficient to implement. They work well in scenarios that do not require complex labeling instructions. However, they often miss edge cases that are essential to improve your model performance. For example, given an image of a soccer game, while automatic labeling techniques can easily label individual players and objects, they might miss a coordinated goal celebration from a group of players. This is precisely the type of rich annotation that manual labeling techniques can capture.
Read the initial blog post on our Auto-Label framework to get a more in-depth explanation of the key differences between manual and automatic labeling.
A Primer on Custom Auto-Label
Our Custom Auto-Label (CAL) product combines the best of both manual and automatic labeling techniques. As the name suggests, the CAL leverages (1) subject matter expertise from manual labeling and (2) advanced ML techniques to distill such expertise into an automated solution.
The primary ML techniques that power our CAL product are transfer learning, few-shot learning, Bayesian deep learning, and self-supervised learning.
1 - Transfer Learning and Few-Shot Learning
Transfer learning enables ML practitioners to deal with labeling challenges by leveraging the already existing pre-trained model that was trained on labeled data of some related task or domain. Few-shot learning is another solution to automatic labeling. Unlike traditional supervised learning, few-shot learning attempts to train a model using a small number of labeled data.
Our CAL uses a combination of transfer learning and few-shot learning to quickly adapt and tailor our proprietary models to your data in your specific application domain.
2 - Bayesian Deep Learning
Bayesian deep learning incorporates a Bayesian approach to designing neural networks - to quantify uncertainty in the model predictions. By accounting for such epistemic uncertainty, ML practitioners can develop models with improved calibration, reliable predictive distributions, and improved accuracy.
By combining two uncertainty estimation methods (Monte Carlo and Uncertainty Distribution Modeling), our CAL not only labels your data automatically but also picks out the “hard examples” that are the most valuable for model training, thereby enabling active learning workflow. Consequently, CAL users can focus on reviewing and editing these hard examples instead of manually labeling the entire dataset. Check out our whitepaper for the theoretical details behind this novel capability.
3 - Self-supervised learning
Self-supervised learning empowers ML practitioners to exploit the labels that come with the data for free. Because producing a dataset with clean labels is expensive, we can creatively exploit the properties of the unlabeled data to set up a self-supervised task and get supervision from the data itself. The self-supervised task guides us to a supervised loss function to learn intermediate representations from the data. These representations carry good semantic/structural meanings and provide benefits to a variety of practical downstream tasks.
Our CAL utilizes self-supervised learning to pre-train our models on popular application scenarios for computer vision. Suppose you work with niche datasets in highly specialized domains (microscopic imagery, computer graphics, etc.). In that case, you can select from our list of pre-trained models that have been self-supervised on each of these application scenarios, which might work well for your domain.
Given such powerful capabilities mentioned above, you only need to build a small ground-truth dataset. Our CAL product will take care of the remaining data preparation tasks (no matter how complex or niche your domain might be).
Best Practices To Prepare Your Ground-Truth Datasets
1 - The Base Guideline
At the minimum, you should have 2,000 annotations per object class. Approximately 80% of the annotations are used to train the CAL model, and 20% are used to tune model hyper-parameters and estimate model performance. For example, assume that you first manually label a dataset with 5 classes and 2 annotations per class on each image. When you use 1000 images for model training (which is equivalent to 2000 annotations per class), 400 annotations per class will be used for hyper-parameter tuning and model performance estimation.
If you do not train the CAL model with enough annotations, two problems hinder CAL from functioning correctly. First, the small training data size will make your model underfit, resulting in a lousy performance. Second, the hyper-parameter tuning and performance estimation steps won’t be sufficient (you can’t set a class score threshold, you can’t determine whether to make annotations or not, etc.), thereby leading to either too many false positives or false negatives. These two problems get bigger if your dataset has highly imbalanced classes.
2 - Defining Object Classes
It is imperative to define your object classes correctly. Here are four pointers that we recommend you sticking with:
(If all conditions are the same) The less the number of object classes is, the better the model performs: From the ML model’s point of view, it is difficult to categorize a high number of object classes. Assuming that you have a high number of classes, we recommend you grouping small sample classes or difficult/ambiguous classes (even for the human eyes) into one bucket (i.e., the 20s and 30s as age groups, Mini Van and SUV as cars). It would be ideal to further define and sub-categorize the classes using properties (also known as class attributes) that you can later manually add within our Suite platform (these properties aren’t used for CAL training).
Try to match the total number of annotations among all object classes: It will be practically impossible to match all classes perfectly, as common classes (like “person” or “car”) will always have way more annotations than less common classes. You should always try to address the class imbalance, and one way to handle this is by grouping small sample classes with other similar classes.
Do not sub-categorize classes until you have enough annotations. Instead, group rare classes (<1000 annotations) together. We provide examples of grouping classes below:
• Gadgets: monitor, notebook smartphone, small appliances, etc.
• Accessories: necktie, watch, shoe, hat, necklace, fashion items, etc.
• Car and Truck: Sedan and SUV as “Car,” while pickup truck and box truck as “Truck.” Grouping similar classes together (such as vehicles and gadgets) makes the CAL model perform better, as it will improve object detection accuracy.
• Others: For classes that are (1) difficult to group with others and (2) different in object size, it is better to group them all as “Others.” Why? Let’s say you only have 100 annotations of bicycles and set them as an object class. Firstly, the CAL model won’t be trained on that sample due to the small sample size and difficulty detecting the object. Secondly, those annotations may be used to tune model hyper-parameters or estimate model performance, which will degrade the overall model performance. Thus, it is better to group those classes altogether.
It would be ideal to have all of your object classes evenly distributed throughout the labels. You should avoid having any images with too many annotations. If you absolutely have to include such an image, then try to get at least 100 annotations of its class in the entire dataset.
3 - Labeling Ground Truth
When an image or video is labeled, the corresponding label is called a “ground truth.” Your labeling policy determines the quality of your ground truth. The labeling policy must be clear and consistent to ensure a high-quality bar when labeling the ground truth. We provide labeling policies for three common object shapes below:
Bounding Box: The box should tightly cover around the object’s edges. You can define the edge as either (1) what is visible or (2) what constitutes the actual edge (but might be occluded by another object). Either way, you should apply that object definition consistently for all your labels.
Polygon: If you do not draw the polygon boundary clearly and consistently, the CAL’s polygon boundary output may not be tight and thus won’t help improve the labeling efficiency. As a result, you need to set a labeling policy on how precisely you want to capture the object boundaries using a polygon.
Keypoint: You need a clear labeling policy on whether or not you will label keypoints that are occluded and invisible. You should also avoid defining the keypoint skeleton as a single horizontal (or vertical) line (for example, avoid a keypoint annotation that has “frontal head - neck - chest - tailbone” for a human skeleton in a single vertical line). You should also include other parts of the object (i.e., left shoulder and right shoulder for a human skeleton) - such that if you have to draw a bounding box around the keypoint annotation, the box is not a narrow horizontal (or vertical) rectangle.
Recommended Workflow using CAL
Assuming that you have followed the best practices to build ground truth datasets discussed above, you have a good chance to get a quality CAL model on your first training iteration.
1 - First Iteration
For the object classes with an arbitrarily satisfactory detection rate, we do not recommend training another batch until you have obtained enough ground truth labels for those classes.
What is a satisfactory detection rate? A rate in which you can tell fairly quickly after reviewing a few labels whether your CAL model detects a particular class accurately or not.
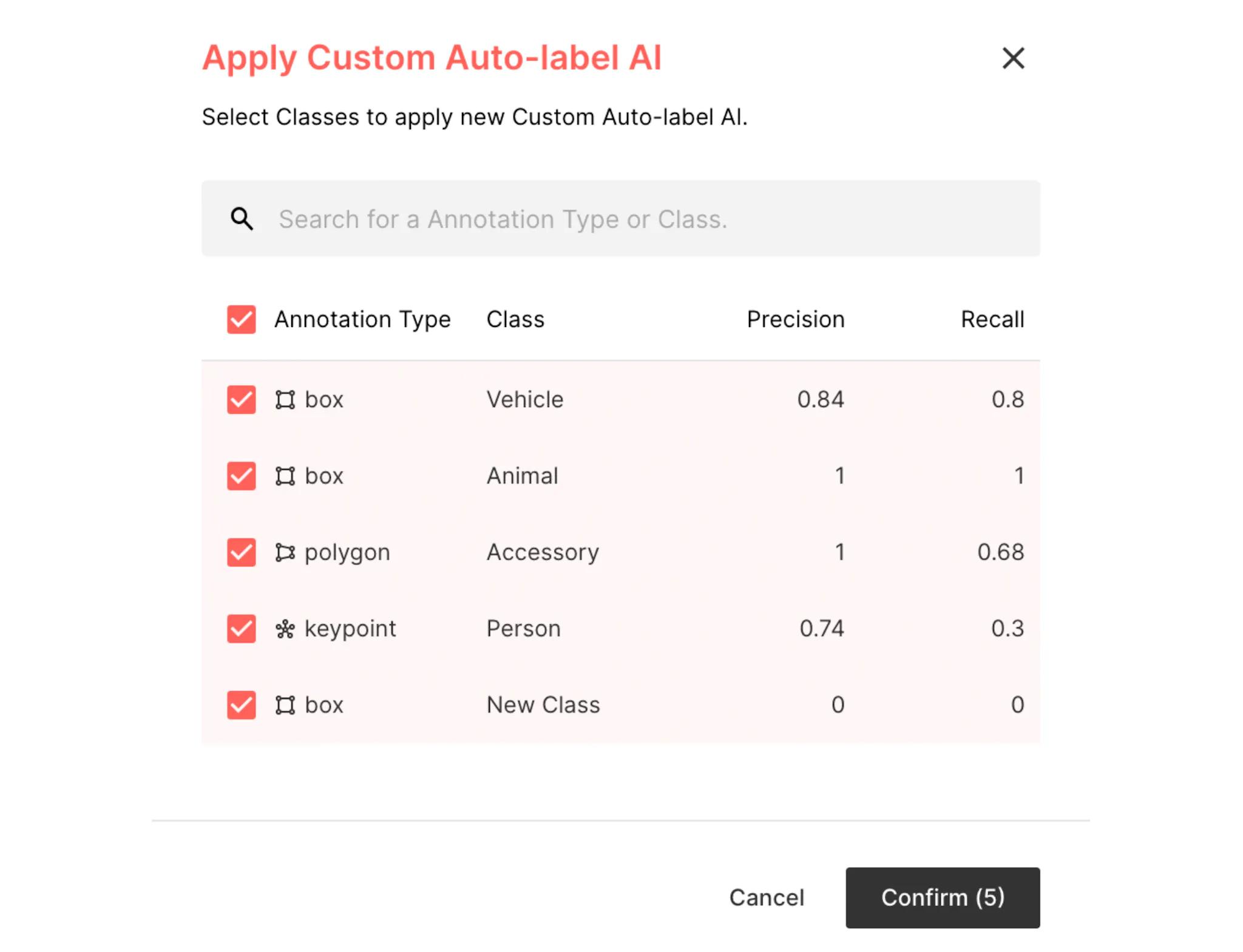
With this feature, users can see how well the trained CAL will perform for each class. Then they can select for which class they want to use CAL.
If the CAL model performance was unsatisfactory for certain object classes, adding more data and manual annotations for the particular class is one possible solution. In this situation, we suggest first disabling those classes in the configuration settings of your CAL project and manually labeling more data for the lacking object classes. If you run into undiagnosable issues, please contact us so we can troubleshoot them and see if we can update your CAL model.
Another reason your trained CAL is not well-performing may be that your data belongs to a highly specialized domain (i.e., medical images, satellite images). In the near future, we plan to develop several pre-trained models for each major domain (i.e., natural images, top-down view satellite images, microscope images, etc.) in a self-supervised manner. CAL users can choose which pre-trained model to start with when using CAL. This, in effect, will increase the likelihood of getting a better model performance on the corresponding domain and task.
After the initial iteration of training CAL, you should continue using CAL for your next batch of unlabeled data. Remember to focus on reviewing the high-difficulty labels and export them for the next iterations of CAL training.
2 - Future Iterations
For the subsequent training iterations, we recommend that users focus on gathering raw data and manually labeling object classes on which the previous CAL model did not perform well on. Doing so enables you to clearly check and capture our CAL’s performance enhancements on those classes as you iterate. More specifically:
First, you can use Suite’s filter feature to filter labels with those classes (“Filter By -> Annotation -> Contains All Of -> Select An Object Class”)._
_

Next, you can add label tags when creating your next batch.
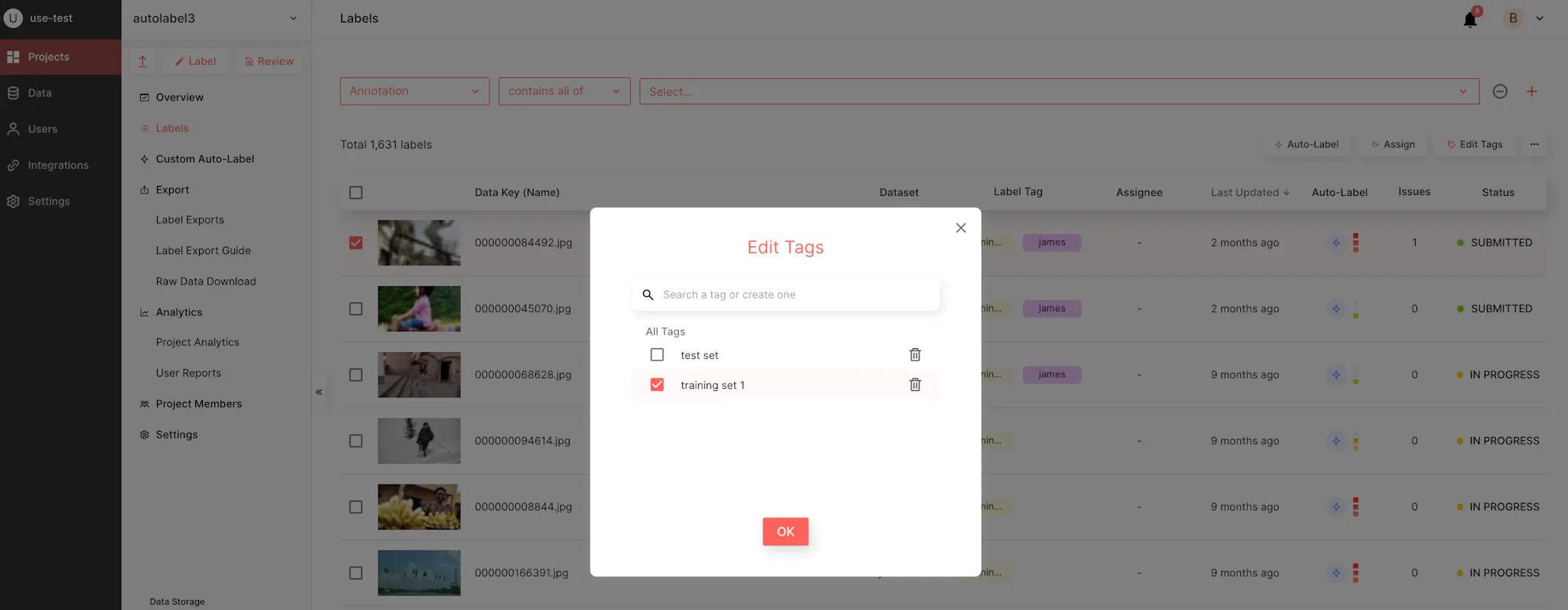
Finally, make sure that you export the previous batches whenever you train a new CAL model. For example, if this is your 3rd CAL iteration, you should export the 1st, 2nd, and 3rd batch together.
How To Get Started
If you're ready to get started with Custom Auto Label, we're happy to help. Feel free to schedule a call with our Sales team. There's a lot to consider with automated labeling, and some teams might not be ready for this feature just yet. That's okay; we aren't pushy and will do our best to help!
Related Posts

Product
How to Build & Deploy an Industrial Defect Detection Model for a Lucid Vision Labs Camera

Sam Mardirosian
Solutions Engineer | 15 min read

Product
How to Build & Deploy a Safety & Security Monitoring AI Model for an RTSP CCTV Camera
Sam Mardirosian
Solutions Engineer | 15 min read

Product
How to Use Generative AI to Properly and Effectively Augment Datasets for Better Model Performance

Tyler McKean
Head of Customer Success | 10 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.