Announcements
Zero-Shot Vision AI: Why One Day is All You Need to Deploy AI

Hyun Kim
Co-Founder & CEO | 2025/06/24 | 15 min read

Zero-Shot Vision AI: Why One Day is All You Need to Deploy AI
Imagine a company launching a new product line. What would it take to automatically classify and manage these new items using a conventional computer vision system?
In reality, the process would look something like this : First, it takes 2-3 weeks to systematically collect thousands of images of the new products. Then, an additional 1-2 weeks is needed for annotation—assigning accurate labels to each image. Retraining and validating the AI model takes another 2-3 weeks. Finally, when you account for system integration and production deployment, the total development cycle spans 6 to 9 weeks and costs tens of thousands of dollars.
And that’s not the end of it. If another new product is released 3 months later, the same process must be repeated. If quality standards change 6 months down the line, everything starts over. This naturally raises the question: Why do AI systems need to go through an entirely new training process every time?
AI’s Structural Limit: It Only Knows What It’s Trained For
The Constraints of the Closed-Set Paradigm
Most computer vision systems in business use today are built on a closed-set paradigm. Much like a multiple-choice test, these systems can only classify images into categories that were explicitly defined during training. For example, systems trained on datasets like ImageNet ( 1,000 classes) or COCO (80 object categories) can only operate within those fixed label sets.

Example data from the ImageNet dataset
Here’s how inference works in such systems: when an input image is provided, the system selects from categories it has already seen—like “dog,” “cat,” or “car.” If a new or unexpected object appears, the model either forces it into the most similar known category or outputs an entirely incorrect result.
Siloed AI Architectures for Each Task
A more fundamental issue is that, oftentimes, separate AI models are required for every business need. CNNs for image classification, R-CNNs for object detection, anomaly detection models for quality inspection, and counting models for inventory management—all built and deployed independently. These models use isolated architectures, meaning the visual representations and domain knowledge learned by one model don’t transfer to another.
As a result, even though different models within an organization process similar visual information, they accumulate knowledge separately. This fragmentation negatively affects development efficiency and system performance. High-quality data and insights collected in one domain cannot be utilized effectively in others.
The Real Challenges Enterprises Face
From a development and maintenance perspective, companies must form dedicated AI teams for each domain, repeatedly collect and label data, and manage separate server infrastructures for each model. Furthermore, when new requirements arise, the entire development cycle often needs to be restarted from scratch.
From a business agility standpoint, it can take months to respond to changing market demands or customer needs—leading to lost competitiveness. New product launches and business expansions are delayed due to slow AI adaptation. Most critically, these limitations cause many departments to delay or abandon AI adoption altogether. Tasks that could be automated remain manual, and the organization’s full data potential goes unrealized.
Foundation Models: A Fundamental Paradigm Shift in AI
A Revolution That Began in Natural Language Processing
The foundation model revolution began in natural language processing (NLP) with the introduction of BERT in 2018 and the success of GPT-3 in 2020. Until then, each NLP task—such as machine translation, document summarization, question answering, or sentiment analysis—required its own architecture and training data. But the emergence of large-scale language models made it possible for a single, unified model to perform a wide range of language tasks simultaneously.
ChatGPT is a prime example. Built on a single transformer architecture, it can handle tasks such as Q&A, summarization, multilingual translation, creative writing, code generation, and data analysis—all without task-specific fine-tuning. Instead, prompt engineering alone allows it to adapt across domains.
Expanding the Paradigm to Computer Vision
Now, the same transformation is happening in computer vision. Vision foundation models are designed to perceive and generate visual signs, aiming to serve as general-purpose AI agents that reason about and interact with the visual world. This is not just about consolidating multiple models into one—it’s about redefining the fundamental approach to visual understanding.
The development of vision foundation models has gone through 3 main phases. Initially, the dominant approach was task-specific specialization, where separate models were trained for each task or dataset. This was followed by the pretraining-and-finetuning paradigm, in which large models were pretrained on massive datasets and then fine-tuned for specific tasks—where task-level customization was still required.
Today, we’ve entered a new phase, where a single model handles diverse vision tasks in an integrated way—image classification, object detection, segmentation, and visual question answering—to enable multi-purpose AI agents. This can be achieved by making models open-ended, supporting varying levels of granularity, and enabling prompt-based interaction.
The Power of Transfer Learning and Scale
As defined by researchers at Stanford HAI:“On a technical level, foundation models are enabled by transfer learning and scale. …Transfer learning is what makes foundation models possible, but scale is what makes them powerful.”
Transfer learning allows representations and knowledge learned in one domain to be effectively applied to another. For instance, low-level visual features like lines, edges, and dots learned in general object recognition tasks can also be effectively leveraged in medical imaging or satellite imagery. This makes it possible to achieve strong performance even with limited data in the target domain—dramatically reducing training time and cost.
The effect of scale reveals even more fascinating dynamics. As the number of model parameters and the size of the training dataset increase, model performance doesn’t just improve linearly—new, emergent capabilities often arise once a certain threshold is crossed. Representative examples observed in the GPT series include few-shot learning and chain-of-thought reasoning.
Zero-Shot Learning: The Ability to Instantly Respond to Unseen Data
Technical Definition and Business Implications
Zero-shot learning refers to a model’s ability to make inferences about new classes or tasks it was not explicitly trained on. This capability stems from its meta-learning ability to generalize to novel situations using prior knowledge—marking a major shift from the traditional supervised learning paradigm.
From a business perspective, the key advantage of zero-shot learning is immediate adaptability. When new product categories emerge or market conditions shift, companies can respond instantly—without collecting new data, labeling it, or retraining a model. This eliminates the most time-consuming and expensive parts of traditional machine learning workflows.
CLIP: Unifying Vision and Language Through Contrastive Learning
Released by OpenAI in 2021, CLIP (Contrastive Language-Image Pre-training) was a landmark study that proved the viability of zero-shot learning in computer vision. CLIP was trained on 400 million image-text pairs collected from the internet using contrastive learning—a method that maps visual and textual information into a shared representation space.
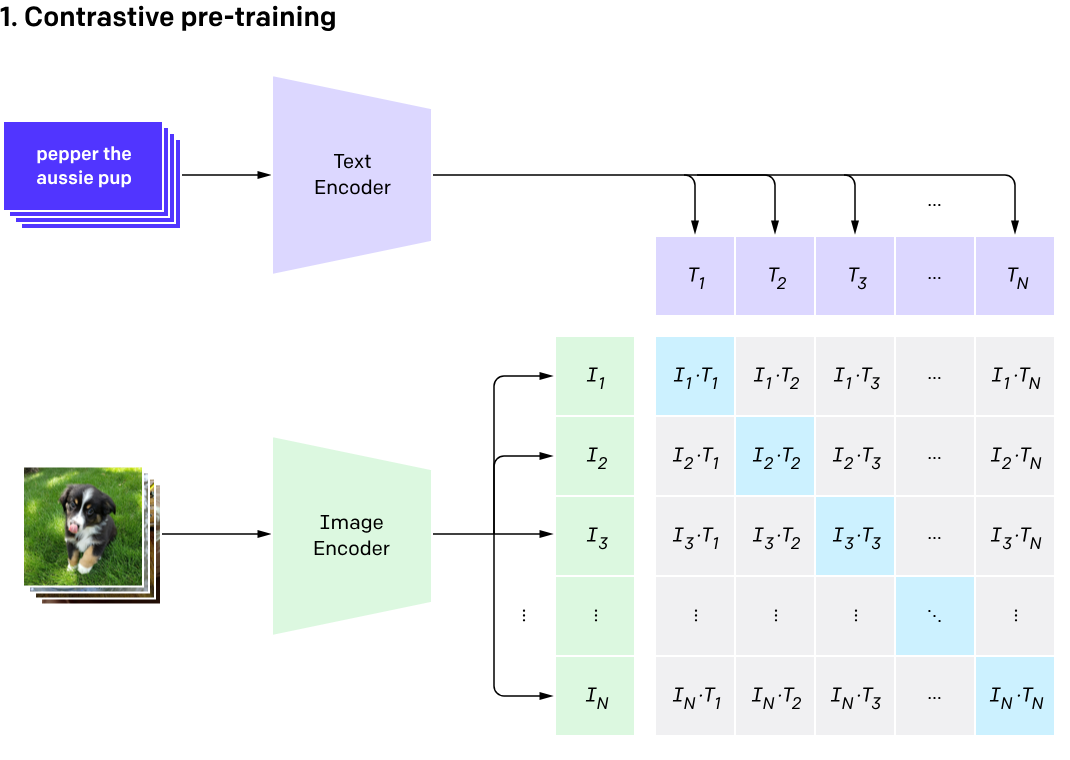
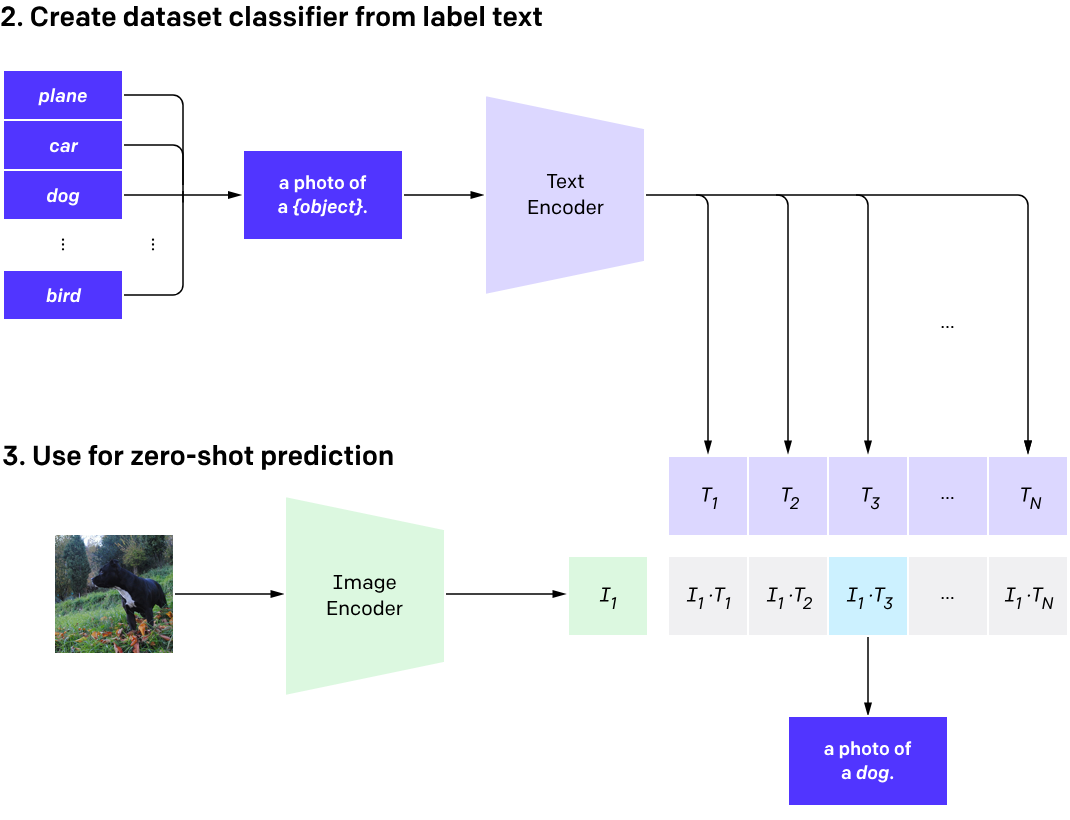
Training structure of CLIP – Source: OpenAI
The core mechanism behind contrastive learning is simple yet powerful: it brings semantically related image-text pairs closer together in the representation space and pushes unrelated ones further apart. Through this process, the model learns that a caption like “red sports car” is semantically similar to the actual image of a red sports car. Critically, this generalization applies to any concept expressible in natural language, not just to pre-defined object categories.
Since the introduction of CLIP, various follow-up studies—such as ViLD, RegionCLIP, and OVR-CNN—have been achieving significant results across a wide range of applications by leveraging CLIP’s vision-language representations:
- ViLD: Developed a zero-shot object detection system by leveraging CLIP knowledge
- RegionCLIP: Enabled open-vocabulary recognition of specific regions within an image
- OVR-CNN: Greatly improved practical usability by detecting objects using open-ended vocabulary

Example: A global retail company optimizing inventory management using zero-shot learning
Open-World Systems: A Breakthrough in Natural Language Interfaces
A Paradigm Shift From Closed-Set to Open-Set
There is a fundamental philosophical difference between traditional closed-set systems and modern open-set systems. Closed-set systems can only classify inputs within a fixed set of predefined labels established during training—for example, limited to 80 categories like “dog,” “cat,” “car,” or “chair.”
In contrast, open-set systems can understand and process any concept expressed in natural language. They are capable of handling virtually unlimited concepts such as “a vintage-style teal bicycle,” “premium sneakers with a prominently printed brand logo,” “a floral-patterned summer dress,” or “a surface scratch that fails quality standards.”
What truly marks this shift is that AI systems are no longer bound by rigid classification schemes. They can now directly interpret human language. This represents not just an expansion in recognition capabilities but a qualitative transformation in how AI and humans interact.
Visual Grounding: Precision in Vision-Language Interaction
One of the most advanced forms of open-world systems is the visual grounding technology—the ability to identify precise locations and regions in an image based on natural language descriptions.
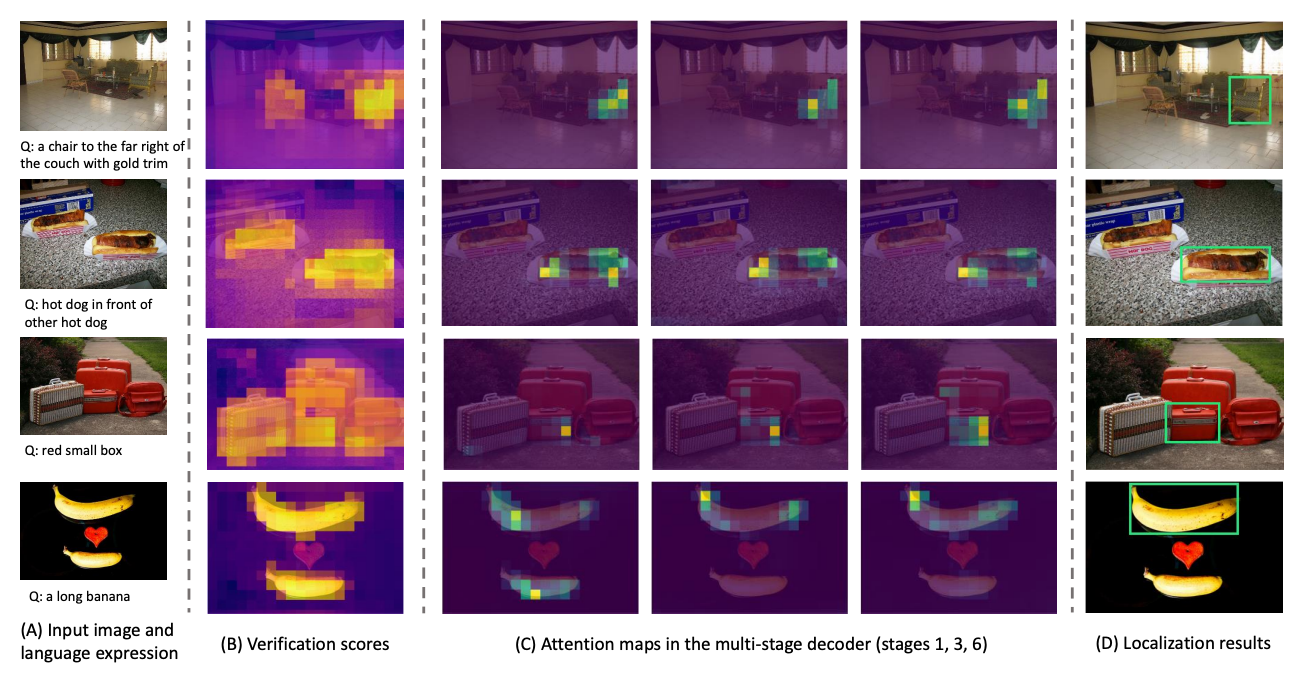
Visual grounding research using various images and natural language input
For example, in a warehouse management system, if a user inputs “the damaged box on the left shelf in Zone A on the second floor,” the system can pinpoint the exact location and automatically notify a manager. In quality inspection, a detailed phrase like “a small scratch on the bottom right of the front panel” can be used to accurately highlight defects and automatically assign a severity grade.
In security monitoring, complex spatiotemporal contexts like “a vehicle parked at the entrance of the parking lot for over 10 minutes” can be recognized and trigger alerts. These examples illustrate how AI is advancing from basic pattern recognition to near-human-level situational understanding.
The emergence of vision foundation models and zero-shot learning is not just a technical upgrade—it signifies a fundamental change in how enterprises adopt and use AI.
The days of waiting weeks or months to accommodate new business needs or market shifts are over. We’ve entered an era where you can describe what you want in natural language, and AI will understand and act on it instantly.
This shift not only improves businesses’ operational efficiency but also transforms their market competitiveness and innovation speed. Experience this new standard of AI adoption enabled by zero-shot learning and open vocabulary systems.
In the next post, we’ll explore how Vision AI models communicate with users in various forms, such as text prompts, image references, and mouse clicks—and closely examine the differences between Vision-Language Models (VLMs) and Vision Foundation Models (VFMs).
Related Posts

Announcements
Superb AI’s ZERO Takes 1st Place in the CVPR 2026 Foundational Few-Shot Object Detection Challenge
Hyun Kim
Co-Founder & CEO | 10 min read

Announcements
Celebrating Superb AI’s 8th Anniversary — 130 Million Images, Korea’s First Vision Foundation Model, and the Next Chapter of Physical AI
Hyun Kim
Co-Founder & CEO | 5 min read

Announcements
We're heading to NVIDIA GTC — and we have a lot to show you!
Hyun Kim
Co-Founder & CEO | 2 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.