インサイト
Zero-Shot Vision AI:AI導入に1日あれば十分な理由

Hyun Kim
Co-Founder & CEO | 2025/06/25 | 15 min read
Zero-Shot Vision AI: AI導入に1日あれば十分な理由
ある企業が新しい商品ラインを立ち上げるとしよう。 従来のコンピューター・ビジョン・システムを使って、これらの新商品を自動的に分類し、管理するには何が必要だろうか?
現実には、このようなプロセスが必要でしょう。まず、新商品の数千枚の画像を体系的に収集するのに2~3週間かかります。 次に、アノテーション(各画像に正確なラベルを付ける作業)にさらに1~2週間かかる。 AIモデルの再トレーニングと検証にはさらに2~3週間かかる。 最後に、システム統合と本番展開を考慮すると、開発サイクルは合計で6~9週間に及び、数万ドルのコストがかかる。
それで終わりではありません。 3ヵ月後に別の新製品が発売されれば、同じプロセスを繰り返さなければならない。 6ヵ月後に品質基準が変われば、すべてがやり直しとなる。 こうなると当然、疑問が生じる: なぜAIシステムは、毎回まったく新しいトレーニング・プロセスを経る必要があるのだろうか?
AIの構造的限界:訓練されたことしか判らない
クローズド・セット・パラダイムの制約
今日、ビジネスで使用されているコンピュータ・ビジョン・システムのほとんどは、クローズド・セット・パラダイムに基づいて構築されている。 多肢選択式テストのように、これらのシステムは、トレーニング中に明示的に定義されたカテゴリーにのみ画像を分類することができる。 例えば、ImageNet(1,000クラス)やCOCO(80の物体カテゴリ)のようなデータセットで学習したシステムは、固定されたラベルセットの中でしか動作できません。

(ImageNetデータセットからのデータ例)
入力画像が提供されると、システムはすでに見たことのあるカテゴリー、たとえば "犬"、"猫"、"車 "から選択する。 新しい、あるいは予期しない物体が現れた場合、モデルはその物体を最もよく似た既知のカテゴリーに押し込むか、あるいはまったく正しくない結果を出力する。
タスクごとにサイロ化されたAIアーキテクチャ
より根本的な問題は、ビジネスニーズごとに別々のAIモデルが必要になることが多いことだ。 画像分類のためのCNN、物体検出のためのR-CNN、品質検査のための異常検出モデル、在庫管理のための計数モデル、これらはすべて個別に構築され、展開される。 これらのモデルは独立したアーキテクチャを使用しているため、あるモデルで学習した視覚表現やドメイン知識は、別のモデルには引き継がれません。
その結果、組織内の異なるモデルが同じような視覚情報を処理しても、別々に知識が蓄積されます。 この断片化は、開発効率とシステム性能に悪影響を及ぼす。 あるドメインで収集された質の高いデータや洞察は、他のドメインでは有効に活用できない。
企業が直面する真の課題
開発とメンテナンスの観点から、企業はドメインごとに専門のAIチームを編成し、データの収集とラベル付けを繰り返し、モデルごとに別々のサーバー・インフラを管理しなければならない。 さらに、新たな要件が発生すると、開発サイクル全体を一からやり直す必要が生じることも多い。
ビジネスの俊敏性の観点からは、市場の要求や顧客ニーズの変化に対応するのに数カ月かかることもあり、競争力の低下につながります。 AIの適応に時間がかかるため、新製品の発売や事業拡大が遅れる。 最も深刻なのは、こうした制約のために、多くの部門がAIの導入を完全に遅らせたり、断念したりすることだ。 自動化できるはずのタスクが手動のままとなり、組織のデータ潜在能力がフルに発揮されない。
Foundation Models: AIの根本的なパラダイムシフト
自然言語処理から始まった革命
自然言語処理(NLP)のFoundation Modelの革命は、2018年のBERTの導入と2020年のGPT-3の成功によって始まった。 それまでは、機械翻訳、文書要約、質問応答、感情分析などの各NLPタスクは、独自のアーキテクチャと学習データを必要としていた。 しかし、大規模言語モデルの出現により、単一の統一モデルで幅広い言語タスクを同時に実行できるようになった。
ChatGPTはその典型的な例です。 単一のトランスフォーマーアーキテクチャ上に構築されたChatGPTは、Q&A、要約、多言語翻訳、クリエイティブライティング、コード生成、データ分析などのタスクを、タスク固有の微調整なしに処理することができます。 その代わり、プロンプト・エンジニアリングだけで、さまざまなドメインに適応することができる。
コンピュータ・ビジョンへのパラダイム拡大
今、コンピューター・ビジョンにも同じ変革が起こりつつある。 視覚の基礎モデルは、視覚的な兆候を認識し、生成するように設計されており、視覚的な世界について推論し、相互作用する汎用AIエージェントとして機能することを目指している。 これは単に複数のモデルを1つに統合するということではなく、視覚理解への基本的なアプローチを再定義するということなのだ。
視覚基盤モデルの開発は、主に3つの段階を経てきた。 当初は、タスクに特化したアプローチが主流で、タスクやデータセットごとに別々のモデルを訓練していた。 これは、大規模なモデルを膨大なデータセットで事前学習し、その後、タスクレベルのカスタマイズが必要な特定のタスク用に微調整するというものです。
今日、私たちは新たな段階に入った。1つのモデルが、画像分類、物体検出、セグメンテーション、視覚的質問への回答など、多様な視覚タスクを統合的に処理し、多目的AIエージェントを実現する。 これは、モデルをオープンエンドにし、さまざまな粒度レベルをサポートし、プロンプトベースのインタラクションを可能にすることで実現できる。
転移学習とスケールの力
スタンフォード大学HAIの研究者たちによる定義では、「技術的なレベルでは、基礎モデルは転移学習とスケールによって可能になる。 ...転移学習こそが基礎モデルを可能にするものであり、スケールこそが基礎モデルを強力にするものである"
転移学習は、あるドメインで学習された表現や知識を、別のドメインに効果的に適用することを可能にする。 例えば、一般的な物体認識タスクで学習したライン、エッジ、ドットといった低レベルの視覚的特徴は、医療画像や衛星画像でも効果的に活用することができる。 これにより、対象領域の限られたデータでも高い性能を達成することが可能になり、学習時間とコストを劇的に削減することができる。
スケールの効果は、さらに魅力的なダイナミクスを明らかにする。 モデル・パラメーターの数とトレーニング・データセットのサイズが大きくなるにつれて、モデルの性能は直線的に向上するだけでなく、ある閾値を超えると新たな能力が出現することがよくある。 GPTシリーズで観察された代表的な例には、数発学習や思考連鎖推論などがある。
ゼロ・ショット・ラーニング 目に見えないデータに瞬時に対応する能力
技術的定義とビジネスへの影響
ゼロショット学習とは、明示的に訓練されていない新しいクラスやタスクについて推論を行うモデルの能力を指す。 この能力は、事前知識を用いて新しい状況に汎化するメタ学習能力に由来しており、従来の教師あり学習のパラダイムからの大きな転換を意味している。
ビジネスの観点から見ると、ゼロショット学習の重要な利点は、即時適応性である。 新しい製品カテゴリーが登場したり、市場の状況が変化したとき、企業は、新しいデータを収集したり、ラベル付けしたり、モデルを再トレーニングしたりすることなく、即座に対応することができる。 これにより、従来の機械学習ワークフローで最も時間とコストのかかる部分を排除することができる。
CLIP: 対照学習による視覚と言語の統合
2021年にOpenAIによって発表されたCLIP(Contrastive Language-Image Pre-training)は、コンピュータビジョンにおけるゼロショット学習の実行可能性を証明した画期的な研究だった。 CLIPは、コントラスト学習(視覚情報とテキスト情報を共有表現空間にマッピングする手法)を用いて、インターネットから収集された4億の画像とテキストのペアで学習された。
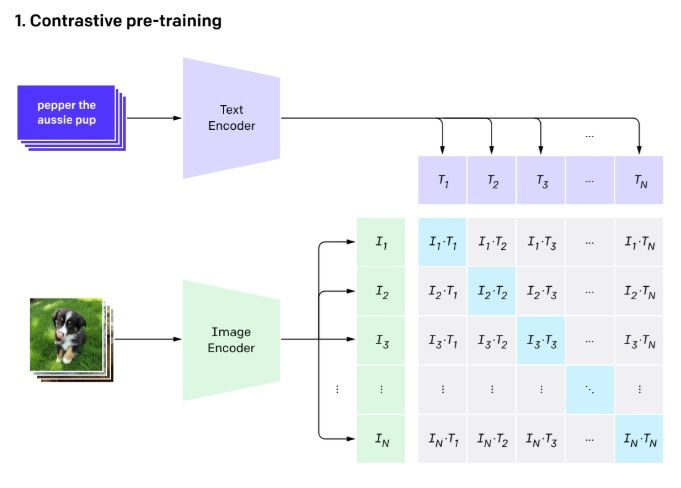
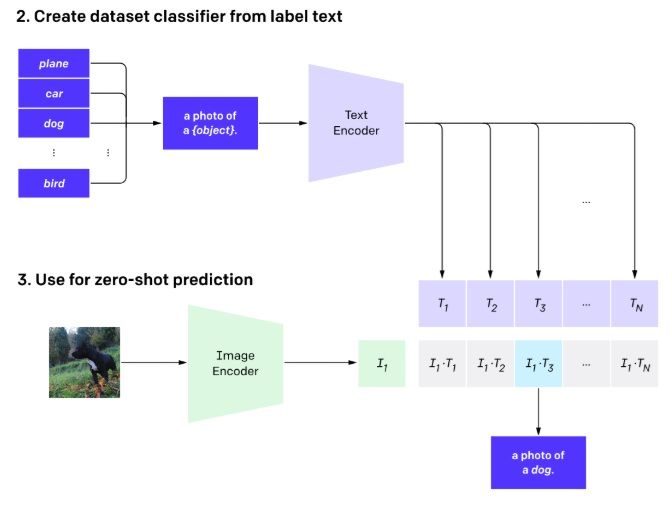
(Training structure of CLIP – Source: OpenAI)
意味的に関連する画像とテキストのペアを表現空間内で近づけ、関連しないペアを遠ざけるのだ。 このプロセスを通じて、モデルは「赤いスポーツカー」のようなキャプションが、実際の赤いスポーツカーの画像と意味的に類似していることを学習する。 重要なことは、この一般化は、あらかじめ定義されたオブジェクトのカテゴリだけでなく、自然言語で表現可能なあらゆる概念に適用されるということである。
CLIPの導入以来、ViLD、RegionCLIP、OVR-CNNといった様々な後続研究が、CLIPの視覚言語表現を活用することで、幅広い用途で大きな成果を上げている:
- ViLD: CLIPの知識を活用したゼロショット物体検出システムを開発
- RegionCLIP: 画像内の特定領域をオープン語彙で認識可能
- OVR-CNN: 自由形式の語彙で対象物を検出することで、実用的な使い勝手が大幅に向上
従来のシステム:
新ブランド入荷 → 商品画像収集 → 分類モデル更新 → システム導入(2~3週間)
Zero-Shot システム:
新ブランド入荷→「高級イタリアンレザーハンドバッグ」だけで瞬時に分類・管理(リアルタイム)
(例 ゼロショット学習で在庫管理を最適化するグローバル小売企業)
オープンワールド・システム: 自然言語インターフェイスのブレークスルー
クローズド・セットからオープン・セットへのパラダイム・シフト
従来のクローズド・セット・システムと現代のオープン・セット・システムには、根本的な哲学的違いがある。 例えば、"犬"、"猫"、"車"、"椅子 "といった80のカテゴリーに限定される。
対照的に、オープン・セット・システムは、自然言語で表現されたあらゆる概念を理解し、処理することができる。 例えば、"ビンテージスタイルのティール色の自転車"、"ブランドロゴが目立つようにプリントされた高級スニーカー"、"花柄のサマードレス"、"品質基準を満たさない表面の傷 "など、事実上無限の概念を扱うことができる。
この変化を如実に示しているのは、AIシステムがもはや厳格な分類スキームに縛られないということだ。 人間の言葉を直接解釈できるようになったのだ。 これは単なる認識能力の拡大ではなく、AIと人間の関わり方の質的転換を意味する。
ビジュアル・グラウンディング: 視覚と言語の相互作用における精度
オープンワールド・システムの最も先進的な形態のひとつに、ビジュアル・グラウンディング・テクノロジーがある。—自然言語による記述に基づいて、画像内の正確な位置や領域を特定する機能。

(様々な画像と自然言語入力を用いた視覚的グラウンディング研究, Source)
例えば、倉庫管理システムでは、ユーザーが「2階Aゾーンの左の棚にある破損した箱」と入力すると、システムは正確な場所を特定し、自動的に管理者に通知することができる。 品質検査では、「フロントパネルの右下に小さな傷」というような詳細なフレーズを使用することで、欠陥を正確に強調し、重大度グレードを自動的に割り当てることができる。
セキュリティ監視では、「駐車場の入り口に10分以上駐車している車両」のような複雑な時空間コンテキストを認識し、アラートをトリガーすることができる。 これらの例は、AIが基本的なパターン認識から人間に近いレベルの状況理解へと進歩していることを示している。
ビジョン・ファウンデーション・モデルやゼロショット学習の登場は、単なる技術的なアップグレードではない。—これは、企業がAIを採用し利用する方法の根本的な変化を意味する。
新しいビジネスニーズや市場の変化に対応するために、数週間や数ヶ月を待つ時代は終わった。 欲しいものを自然言語で説明すれば、AIが即座にそれを理解し、行動してくれる時代に入ったのだ。
このシフトは、企業の業務効率を向上させるだけでなく、市場競争力やイノベーションのスピードも変革する。 ゼロショット学習とオープン・ボキャブラリー・システムが可能にする、AI導入の新しいスタンダードを体験してください。
次回は、ビジョンAIモデルが、テキストプロンプト、画像参照、マウスクリックなど、さまざまな形でユーザーとどのようにコミュニケーションをとるかを探り、ビジョン言語モデル(VLM)とビジョン・ファンデーション・モデル(VFM)の違いを詳しく検証します。





Superb AIについて
Superb AIは、エンタープライズ向けのAIトレーニングデータプラットフォームであり、ML(機械学習)チームが組織内でトレーニングデータをより効果的に管理・提供できるよう、データ管理の新しいアプローチを提案しています。2018年に発表されたSuperb AI Suiteは、自動化、コラボレーション、プラグアンドプレイモジュールのユニークな組み合わせを提供し、多くのチームが高品質なトレーニングデータセットを準備する時間を大幅に短縮する手助けをしています。この変革を体験したい方は、今すぐ無料でご登録ください。