Insight
What is Interactive AI and Auto-Edit?

Tyler McKean
Head of Customer Success | 2023/03/01 | 4 min read
Three major image segmentation types are recognized and frequently employed in the AI development community: semantic segmentation, instance segmentation, and panoptic segmentation. Image segmentation, as an umbrella concept or term, is viewed as the act of separating or dividing image data up into "segments" that are associated with an object label.
In other words, Image seg enables data scientists to break image data content down to a more granular level and, in doing so, provide a denser picture of understanding and richer context for the purpose and effort of AI model training.
The three variant methods of achieving this denser view and extracting more insight from the image through that view; semantic, instance, and panoptic, are as follows:
Semantic

Semantic segmentation divides an image according to pixel distribution.
Semantic segmentation divides an image according to pixel distribution. The objects within an image are assigned probability percentages and a single class label. (Image/Ayoola Olafenwa)
Semantic segmentation classifies the parts of an image that belong to the same class; it also can perform predictions for pixels and estimate the probability of classes based on pixels.
Instance

Instance segmentation detects all distinct objects in an image, segments them, then produces a mask for each individual object.
Instance segmentation detects all distinct objects in an image, segments them, then produces a mask for each individual object. (Image/Nikita Shiledarbaxi)
Going one step further than semantic, instance segmentation identifies each distinct object within an image rather than segments per class.
Panoptic

Panoptic segmentation segments images through both instance and object class, assigning pixels based on the instance of a class.
Panoptic segmentation segments images through both instance and object class, assigning pixels based on the instance of a class. (Image/Alexander Kirillov, Facebook AI Research)
Panoptic segmentation segments images by both instance (object) and class; assigning pixels by instance of a class.
In this article, we'll be honing in on the second image segmentation method, instance segmentation, to explore its function as a pixel-level training method for CV applications through image annotation.
The Basics of Instance Segmentation
Instance merges the strategies behind object detection and semantic segmentation and elevates them to a more comprehensive hybrid technique. Object detection works to localize the positions of objects in image data (through bounding boxes), as well as classify those positions.
While semantic classifies pixels in an image to create a pixel-precise map for each individual image. Combining these two approaches results in instance segmentation, the ability to detect distinct objects in images, segment them, and produce an accurate representation of an image through a segmentation mask.
Input-wise, instance requires an image and instance targets, as well as classes, before producing outputs like bounding boxes, segmentation masks, and the class of each instance.
Users can differentiate one instance of a specific object class from another and keep count. For example, if using "animal" or "vehicle" to represent a class, an algorithm will mark each animal or vehicle in an image as a separate class instance ("person 1", "person 2", and so on).
There are two basic process steps for any instance segmentation task:
- Define specific instance classes (as aforementioned through the "animal" or "vehicle" examples).
- Create a segmentation mask for the distinct instances within those classes.
Instance Versus Semantic
Instance tagging provides teams with more information to analyze unknown or uncertain circumstances in data evaluation, like counting elements belonging to the same class and the detection of certain objects that need to be identified and retrieved by, for instance, an ML-enabled robotics application.
Unlike semantic, instance recognizes the same objects in a single image as different. To break down this process and capability, the image is divided into multiple segments, and every pixel becomes associated with an object type.
If you're unsure whether you should use instance versus semantic segmentation, ask yourself: are you looking for an image segmentation technique that counts each distinct object? If that's the case, then instance segmentation is the way to go. And remember that it's easier to use labels created for instance segmentation to solve a semantic task; but harder the other way around.
Semantic Versus Panoptic
Both semantic and panoptic segmentation require each pixel in an image to be assigned a semantic label. For that reason, both techniques are similar if ground truth doesn't specify instances or if all the classes are stuff. The inclusion of 'thing' classes (which may have multiple instances per image) differentiates these tasks.
Instance Versus Panoptic
Instance and panoptic segmentation share the function of segmenting each object instance in an image. Their main difference lies in how they individually handle overlapping segments.
Instance permits overlapping segments, while the panoptic segmentation tasks allow assigning a unique semantic label and a unique instance ID to each pixel of the image. So, for panoptic segmentation, no segment overlaps are possible.
Challenges to Instance Segmentation
The inherent variation present within and among different datasets, class imbalance, a lack of task-specific training data, imperfect segmentation labels, and clustered and overlapping objects are some of the most prominent challenges with instance segmentation.
Image segmentation challenges show that besides an adapted network architecture, further improvements such as task-specific data augmentation, customized loss functions, and specialized post-processing is needed. For the design of a deep learning-based segmentation, the developer has to choose the network architecture and training process settings.
Including; regularization, activation, and loss functions, gradient descend optimization algorithms, batch normalization, and the corresponding hyperparameters. In contrast to shallow networks, deeper networks are able to use far fewer parameters per layer to fit a training set and often generalize the test set but are also harder to optimize. Task-specific ideal network architectures must be found experimentally, guided by the validation set error.
Instance Segmentation Model Architectures
As an essential tactic to accelerate image processing and also bypass the significant endeavor of building an ML algorithm from the ground up, object detection architectures have an important role to play in successfully executing instance segmentation.
Mask R-CNN
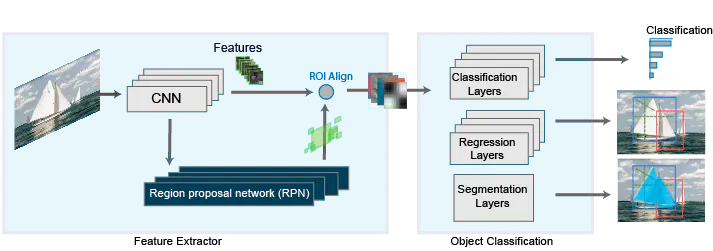
The Mask R-CNN network is comprised of two stages. The first is a region proposal network (RPN), and the second; an R-CNN detector that refines RPN proposals.
The Mask R-CNN network is comprised of two stages. The first is a region proposal network (RPN), and the second; an R-CNN detector that refines RPN proposals. (Image/MathWorks)
A popular architecture specific to the instance image segmentation method, in particular, Mask R-CNN extends another architecture it's built off of, Faster R-CNN, a region-based convolutional neural network that outputs bounding boxes for each object as well as a class label confidence score.
For that reason, in order to get a well-rounded view of Mask R-CNN, it's best to start with its foundation. Faster R-CNN has two stages of function:
Stage 1
The first stage of Faster R-CNN is comprised of two networks that analyze image data once and present a set of region proposals. Which are simply regions within the feature map that contain the object.
Stage 2
The network predicts bounding boxes and object classes for each proposed region that is identified in stage 1. Each region can be of a different size, while the connected layers in networks require a fixed-size vector to make predictions. The fixed-size regions are determined through the ROI pooling or ROI align methods.
With Faster R-CNN as a base stage, Mask R-CNN also has two stages that lead to instance-level object understanding. The first stage being a region proposal network (RPN), and the second a combined object detection and segmentation network.
Hybrid Task Cascade
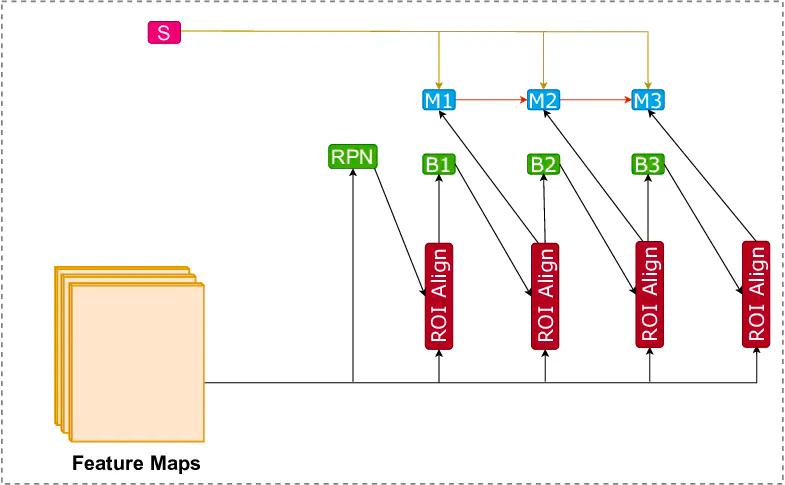
Illustration of Hybrid Task Cascade network. It utilizes three box and mask heads to produce accurate predictions.
Illustration of Hybrid Task Cascade network. It utilizes three box and mask heads to produce accurate predictions. (Original Image used under CC BY 2.0 license)
Hybrid Task Cascade (HTC) is an architecture touted for its capability to boost the performance of various segmentation tasks, but it's not yet a standard choice for instance segmentation, as combining Cascade R-CNN with Mask R-CNN has only resulted in limited benefit through research-based testing in the past.
However, a new and more effectively promising approach has helped to leverage a reciprocal relationship between detection and segmentation. A study presenting a new framework called Hybrid Task Cascade (HTC) offers two distinct and important aspects: rather than performing cascaded refinement on detection and segmentation separately, it blends them into a partnered multi-stage processing.
This joint union provides spatial context, which can better distinguish a hard foreground from a cluttered one. Essentially, the HTC framework can learn from discriminative features in a progressive way as it integrates complementary ones together in each stage.
Top-Down and Bottom-Up Approaches
The primary goal of figure-ground segmentation is to identify an image and separate it from its background or the image scene. One approach to do so is, of course, known as segmentation.
What is referred to as the bottom-up approach, is the act of initially segmenting an image into regions and then identifying the image regions that correspond to an individual object. Relying on continuity principles, this approach gathers and groups image pixels according to the grey level or texture uniformity of image regions, as well as the smoothness and continuity of contours.
The problem with this approach is that an object could potentially be segmented into multiple regions, and some of those regions might merge an object with its background or scene. This struggle suggests that object recognition facilities segmentation. While a complimentary approach, top-down segmentation, draws on prior knowledge about an object, such as shape, color, or texture, to guide segmentation tasks.
The downside of this approach is the considerable variability in the shape and appearance of objects in a target class. Another consideration is that segmentation outputs produced by a top-down approach may not accurately define an object's figure boundaries.
Combining Top-Down With Bottom-Up
Inspired by the ambition to achieve an optimal balance between bottom-up and top-down segmentation, a tactic introduced by scholars integrates the approaches.
The proposed method combines the top-down class-specific approach, addressing high variability within object classes and automatically learns class representation from unsegmented training images, and a bottom-up approach; to detect homogeneous image regions rapidly.
This combined segmentation is effective because it's unlike other common approaches to combining class-specific knowledge with bottom-up information. The combined method is faster and considers image measurements at multiple scales, converging them in a single pass. The best part yet, the tactic is generally versatile and suited to a range of top-down and bottom-up algorithms.
A Happy Medium Solution
In review, object detection is a necessary step to progress from coarse to a finer quality of digital image quality. It not only provides classes for image data objects but provides the location of the objects that need to be classified; that location is commonly communicated in the form of bounding boxes.
While semantic segmentation aims to give that finer degree of image inference by predicting labels for every pixel in an input image by labeling every pixel according to its object class or region. To further this precision even further, the focus of this article, instance segmentation, comes in.
Instance segmentation provides different labels to match distinctive instances of objects that belong to the same object class. By doing so, instance seg is considered a task that is the happy medium and solution between object detection as well as semantic segmentation
Related Posts

Insight
How to Restart an AI Project That Stalled for Lack of Data—with Just 10 Images

Hyun Kim
Co-Founder & CEO | 7 min read

Insight
Three Years of the Few-Shot Object Detection Challenge: Mapping the Global Vision AI Landscape
Hyun Kim
Co-Founder & CEO | 7 min read

Insight
⑪ Germany's Physical AI Moment: Siemens, BMW, and the Robot Unicorn Counteroffensive
Hyun Kim
Co-Founder & CEO | 15 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.