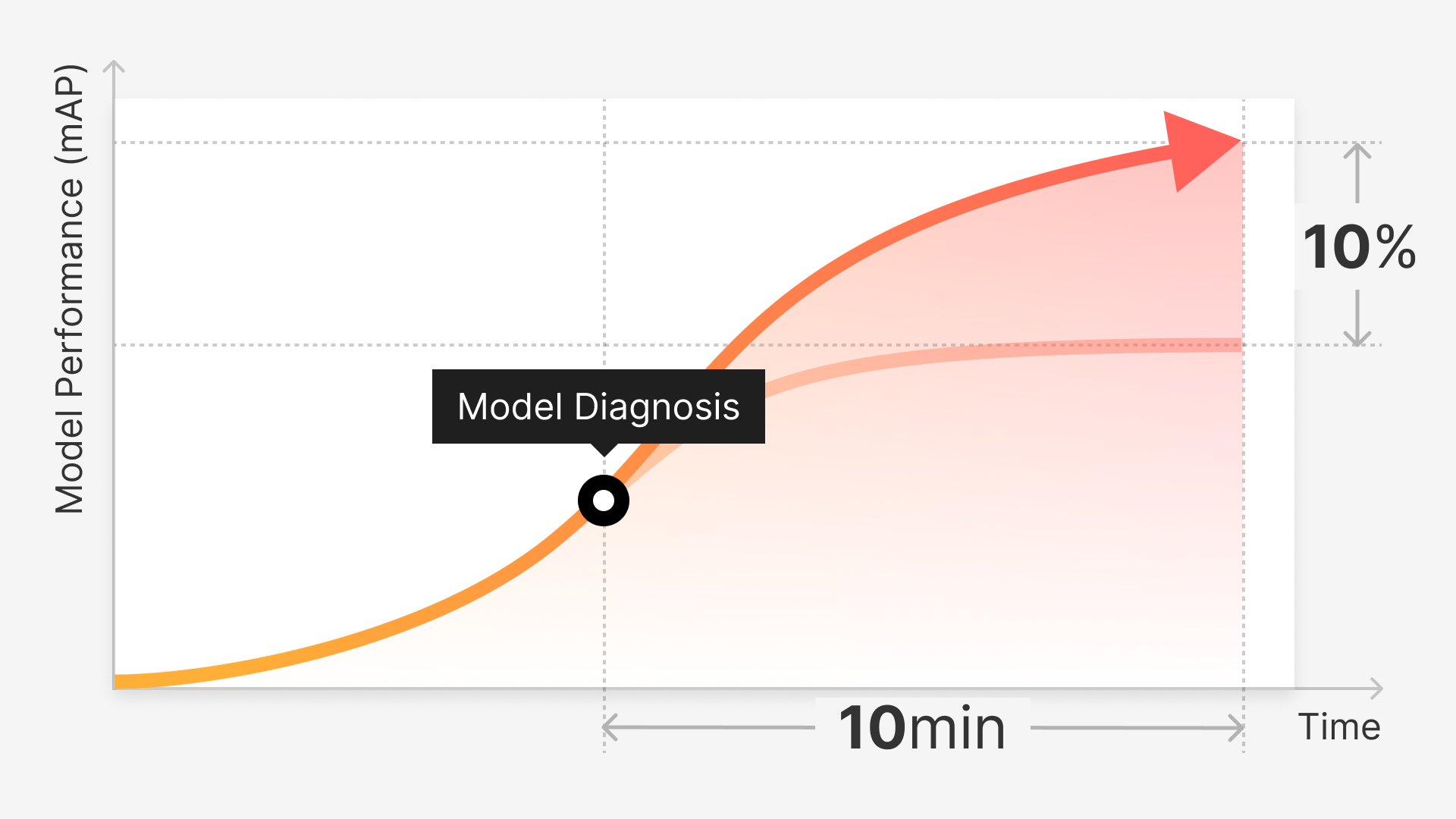
Regardless of your technical expertise or experience in the field of machine learning and computer vision, one thing is universally true: the success of your model largely depends on the quality of your data. Garbage in, garbage out (GIGO), as they say.
However, real-world data is often messy, full of noise and mislabels. This article aims to guide machine learning practitioners and data labelers in their journey to clean up such datasets for more accurate classification tasks.
We Will Cover:
Why quality data matters to model success
Definition and impact of data noise
How manual labeling introduces label noise
Managing noisy datasets
Clustering algorithms and embeddings
Curating clean high-value data
Understanding Label Noise and Mislabeled Data
Noise in data refers to irrelevant or meaningless data, random errors, or variances that distort the underlying structure and the truth we are trying to extract. On a related note, 'label noise' is a particular category of data noise that refers to data likely to be mislabeled or data points located nearby in the embedding space but assigned different classes.
Mislabeled data, on the other hand, is an instance assigned to the wrong class. This is especially damaging for classification problems, as it can significantly diminish the performance of your model. Auto-Curate, a feature of Superb Curate, intelligently identifies such data and selects those likely to be correctly labeled and similar to other data points in the same class.
How Manual Labeling Leads to Mislabels
Manual data labeling can pose numerous challenges, particularly when dealing with large datasets. Manual selection processes can be time-consuming, error-prone, and difficult to scale. Without automation, curating a subset of high-value data to effectively train a machine learning model becomes an intricate task.
One of the main drawbacks of manual data labeling is its propensity to introduce label noise and mislabels into datasets. The impact of these errors on the performance of machine learning models can be profound and far-reaching. They can introduce bias, cause overfitting, or lead to incorrect predictions, underscoring the importance of accurately identifying and rectifying them.
The Issue of Mislabels
To illustrate, consider a manual labeling process where individuals are tasked with categorizing images of animals into different classes. Mislabels can occur in a variety of ways, such as due to simple human error, where an image of a dog is incorrectly labeled as a cat.
Similarly, the manual process may introduce label noise when an image, perhaps one with poor lighting or an unusual angle, leads to confusion about the correct class. A penguin might be mistaken for a blackbird due to its black and white coloration, for instance.
The Risk of Bias in Manual Labeling
Bias can also creep into a manually labeled dataset, as human labelers may subconsciously favor one class over another. If, for instance, a labeler is more comfortable identifying dogs than cats, they may be more likely to label ambiguous images as dogs, leading to an overrepresentation of the "dog" class.
Overfitting Resulting from Manual Labeling
Overfitting is another problem that can arise from manual labeling. Suppose the labeler consistently mislabels a subset of the data, for instance, consistently misclassifying wolves as dogs. The model trained on this data might then perform exceptionally well on this training data, but poorly on new data because it has learned to recognize wolves as dogs due to the incorrect labels.
Managing Noisy Mislabeled Data
Detecting noise in data can be challenging as it often requires domain knowledge to distinguish between actual noise and meaningful outliers. Exploratory data analysis (EDA), using visualizations like scatter plots, box plots, and histograms, is a good start to reveal inconsistencies or anomalies.
Superb AI’s Auto-Curate feature, however, brings automation into the mix by providing the ability to curate datasets of unlabeled images with even distribution and minimal data redundancy. It manages the task of detecting mislabeled data by applying the label noise criterion, which assumes that if a data point is located near other data points with different labels, it is likely to be mislabeled. This user-friendly feature allows for quick corrections of labeling errors.
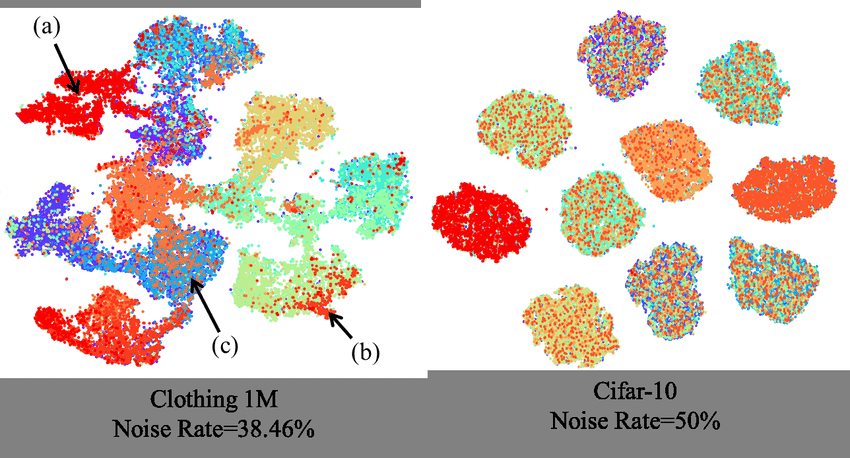
Balancing Class Distribution
Addressing class balance is another crucial aspect when managing datasets. Auto-Curate helps rectify skewed class distribution by undersampling frequent classes and oversampling less frequent classes. For instance, if a dataset has one class appearing much more frequently than others, Auto-Curate selects more data from the less frequent classes to balance the distribution.
By reducing the manual work of curation, Auto-Curate ensures machine learning teams can build more effective models with accurate and well-curated datasets. Whether handling label noise, correcting mislabels, or balancing classes, Auto-Curate enables efficient dataset management and enhances model performance.
Data Imputation with Advanced Tools
In the face of missing or corrupted data, one could employ imputation methods such as mean/median imputation, k-NN imputation, or more advanced models like autoencoders. Real-world data often comes with its fair share of missing or corrupted values, making data imputation a vital step in data preprocessing.
Superb AI's Auto-Edit, a class-agnostic, AI-assisted annotation tool, can be a valuable asset in this process. Auto-Edit allows labeling teams to automatically segment individual objects in images and videos, including complex and irregular shapes, and create pixel-perfect polygons in less than a second. By improving throughput and accuracy, Auto-Edit effectively handles noisy data in image and video-based datasets.
Outlier Removal and Efficient Annotation
Outliers - data points that lie an abnormal distance from other values - can distort your model's learning and its ability to generalize effectively. While some outliers represent genuine extreme values, others may result from noise, error, or data corruption. Removing these outliers is, therefore, an essential part of cleaning noisy data.
Superb AI's Auto-Edit assists in this process by automating polygon segmentation, one of the most laborious, time-consuming, and precision-oriented tasks in data annotation. Auto-Edit enables teams to work smarter and annotate faster, saving significant annotation time per data point, thereby accelerating project velocity and scaling potential.
The Power of AI in Data Cleaning
By using AI to help drive progress, Auto-Edit can deliver substantial impacts at the project and organizational levels. When combined with other automation methods like Auto-Label and mislabel detection, Auto-Edit contributes to the delivery of AI investments faster, with more and better data.
Auto-Edit also aids in further automation by enabling teams to create ground truth datasets for training custom auto-labels, thereby significantly reducing the time required to create a highly performant and accurate AI.
The use of Superb AI tools extends beyond data labeling and project management to data curation. The focus is on curating the “data that should be labeled first” out of large data piles. This curation can be classified into two types:
Pre-model curation, which captures visual attributes of data and curates them to ensure a balanced distribution of these attributes.
Post-model curation, which analyzes model inference results and selects additional data required to enhance model performance.
These comprehensive strategies ensure that noisy data is handled effectively, thus paving the way for robust and accurate machine learning models.
Semi-Supervised Learning
Unlabeled data can be used in combination with a small amount of labeled data to correct the mislabels and improve the classification performance. Semi-supervised learning is an important and often under-utilized approach in machine learning, which combines both labeled and unlabeled data during training.
It allows us to exploit the abundance of unlabeled data along with a smaller amount of labeled data, and in doing so, can often improve the performance of our models and correct mislabeled data.
Simplifying Outlier Detection
Superb Curate and Superb Label streamline the process of detecting and correcting these outliers. You can easily spot potential labeling errors using the 'Find Mislabels' option under Auto-Curate. Just select the dataset or slice you wish to inspect, and let 'Auto-Curate' do the heavy lifting.
Leveraging Scatter Visualization for Efficient Data Analysis
One of our powerful visualization tools, the Scatter visualization, allows you to perceive the distribution of images or objects clustered based on visual similarities across a two-dimensional space. This understanding will help you identify patterns in your dataset and detect outliers effectively.
Overcoming Obstacles in Data Management
Data management often presents a set of challenges including the exhaustive manual search and review, compounded by the lack of systematic metadata design and collection during data acquisition. The sheer volume of unannotated data can make managing it a daunting task.
Many teams resort to adding more data, but this approach often leads to diminishing returns in terms of model performance and the increasing costs associated with preparing the data. Others rely heavily on intuition and experience, which can result in a high margin of error and near-impossible perfect random sampling.
Clustering Algorithms and Embeddings
Clustering algorithms like K-Means, DBSCAN, or Hierarchical Clustering are unsupervised machine learning methods that group data points based on their similarities. They are instrumental in identifying inconsistencies or irregularities in the data, allowing you to detect mislabeled or noisy data points.
To augment these approaches, Superb Curate introduces automated curation feature based on embeddings. Embeddings function as a foundational technology that powers Superb Curate's AI features, allowing the AI to understand and compare "visual similarities between images," such as background, color, composition, angle, and more.
AI-based Data Curation Features in Superb Curate
Superb Curate offers the following embedding-based data curation features:
Image Curation: Curates a dataset of unlabeled images ensuring even distribution and minimal redundancy of data.
Object Curation: Curates a well-balanced dataset of labeled images, ensuring equal representation of classes and an even distribution of objects within each class.
Edge Case Curation: Groups data according to similarity (clustering) and curates only images that are rare or have a high likelihood of being edge cases.
Common Case Curation: Curates only images that are common or have a high likelihood of being redundant.
Leveraging Query for Data Management
The Query feature in Superb Curate helps users find the data they want by searching metadata and annotation information tagged to the images. It supports advanced search capabilities including the ability to:
Search for data that satisfy certain metadata conditions.
Search for “images with more/less than X number of annotations,” or images with specific compositions of objects.
A mixture of the above, where filters or filter groups can be added using Query Builder.
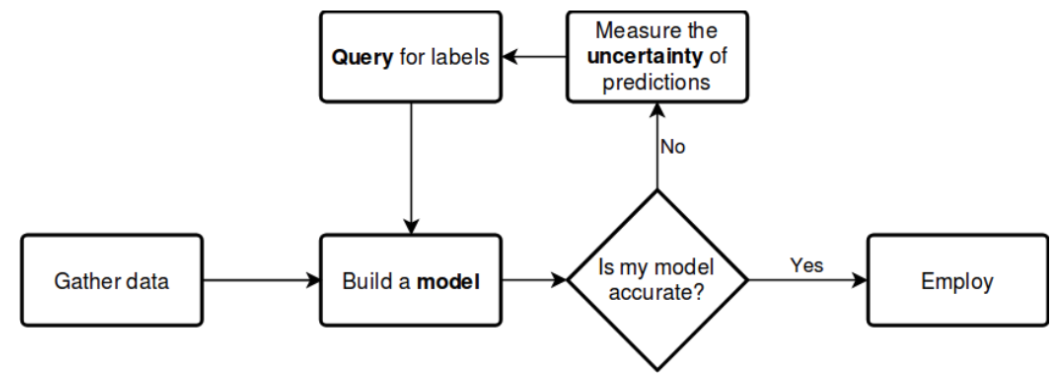
Curating Clean High-Value Data
The challenge of managing and curating data is a significant one in machine learning and computer vision applications, but advanced tools and methods are emerging to meet these challenges head-on. Superb AI, with its suite of automation tools including Auto-Curate, Auto-Edit, and Query feature, streamlines this process, helping machine learning teams to tackle issues of mislabels, label noise, class imbalance, and more.
Embedding-based curation and advanced search capabilities add to the toolbox, enabling better handling of unannotated or poorly annotated data. The importance of these tools cannot be overstated; they pave the way for more efficient and accurate model training, ultimately leading to more robust and successful AI deployments.