Product
Introducing Curate: Achieve Better Model Performance With Significantly Less Data

2023/04/25 | 3 min read

We’re excited to announce that Curate, formerly known as DataOps, is now available!
Curate is Superb AI’s answer to the data-related questions we’ve all faced at one time or another. What data should I label first? Which data should I use for training vs. validation? How much data do I actually need? And so on.
With Curate, you can easily manage, curate, and visualize all your organization’s computer vision data in a single place. And use AI to answer all of the above questions with minimal manual effort, such as auto-curating a balanced slice for training that best represents your entire dataset or uncovering your most valuable data in the form of edge cases or potential mislabels.
At Superb AI, we believe the future of computer vision and machine learning is one where every organization, regardless of ML team size or resources, can build and deploy AI applications, and this product is the next step in our goal of making this a reality.
In this article, we’ll walk you through all the tools and features you can use today to achieve better model performance with much less data. Want to see it for yourself right away? Let our team know, and we’d be happy to give you a personalized demo.
Data Management
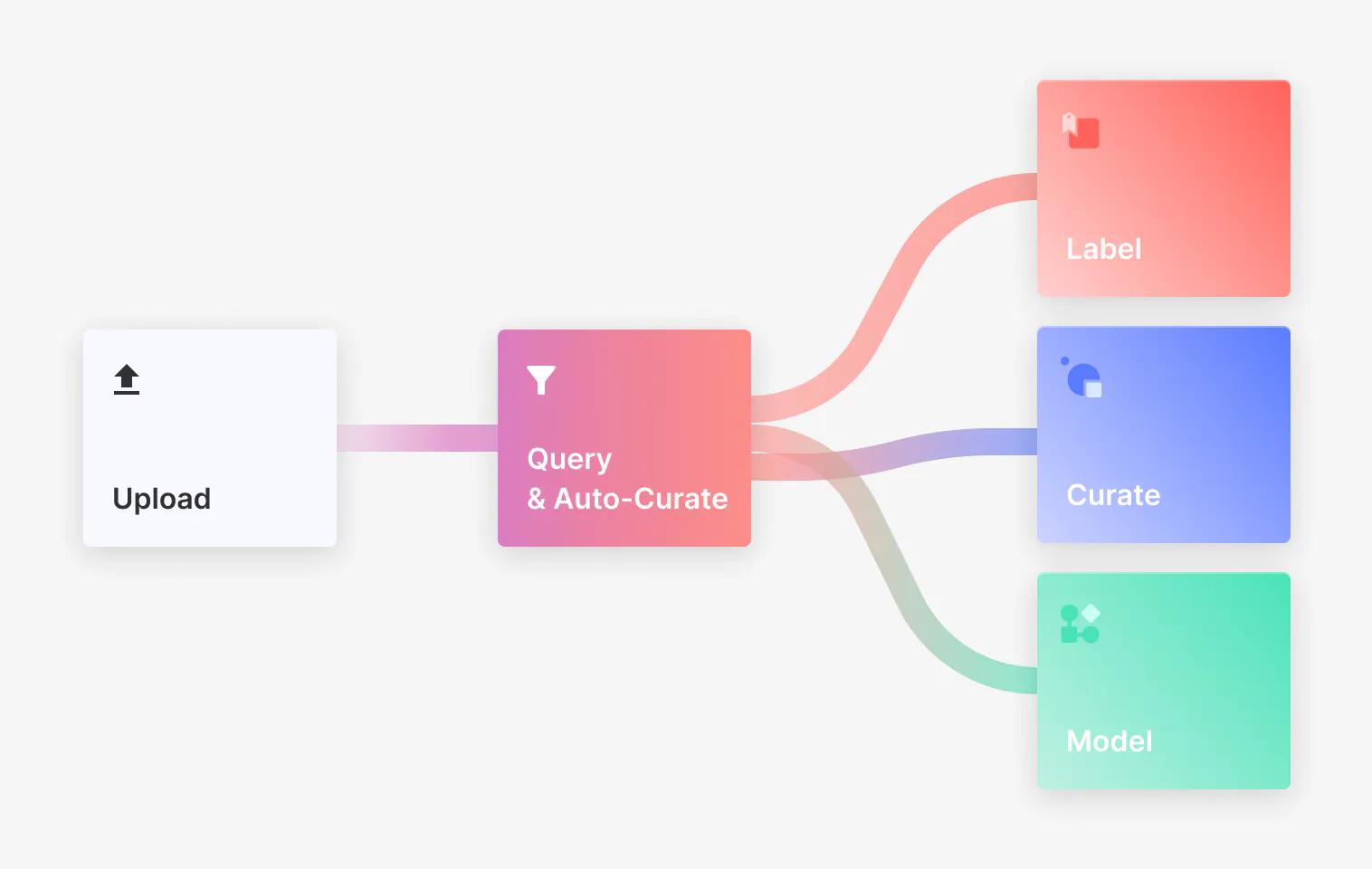
Uploading and pipelining large volumes of data into one place is easy with Superb Curate.
Let’s get started with data management. With Curate, uploading and pipelining large volumes of data into one place as soon as it’s collected is easy. With this initial release, you can upload raw data and labels with associated annotations and metadata using our SDK. Soon, we’ll be working on many other upload mechanisms, including API and CLI, among others, and various forms of pipeline automation.
Embedding Store
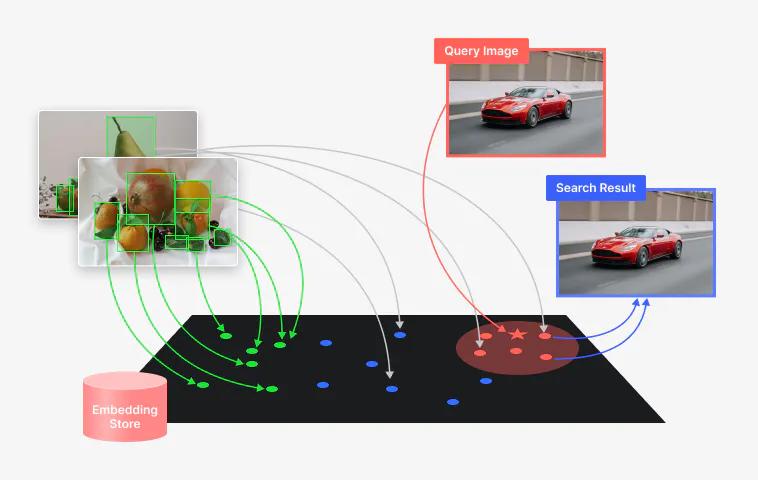
Get access to proprietary, high-dimensional embedding generation algorithms.
One thing that makes Curate unique is that it provides you access to proprietary, high-dimensional embedding generation algorithms. This eliminates the need to build, train, and maintain custom embedding models and infrastructure, which can carry a substantial price tag in data, computational resources, and in-house expertise. It also reduces, or can even eliminate, the need to rely on otherwise slow and cumbersome manual curation techniques.
How it works is simple. Whenever new images or objects are uploaded, high-quality embeddings are generated automatically, and Curate uses unsupervised learning to cluster the image or object data based on visual similarity. Our curation algorithm, which we’ll cover shortly, then uses this to select the data most suitable for your model needs automatically, such as a training or validating set.
Query and Slice
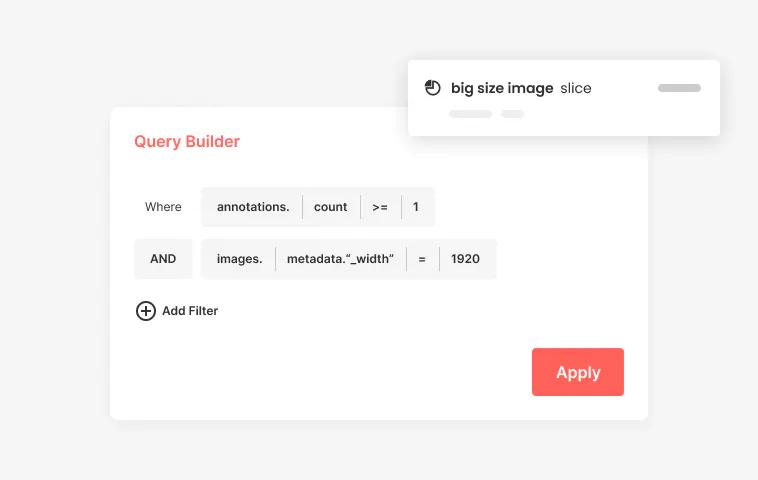
Easily find and meaningfully group data into slices using any combination of metadata or annotation information tagged within your images.
After uploading your data via the SDK, you can easily find and meaningfully group data into slices using any combination of metadata or annotation information tagged within your images. A slice, essentially a data subset, is a foundational concept in Curate, and they can be created manually, as above, or automatically via our AI tools. Using queries to create slices allows you to manually curate data as you see fit - without having to rely on old-school (and painful) search operators like file names.
Using queries combined with image-level views, with tile and scatter views coming soon at the object level, makes it easy to quickly find the exact data you need. Semantic search, also in development, will likewise reduce the time and cognitive effort required even further.
Plus, all your slices are saved within the platform and easy to find, so you can use them immediately or refer back to them whenever needed.
Auto Curate
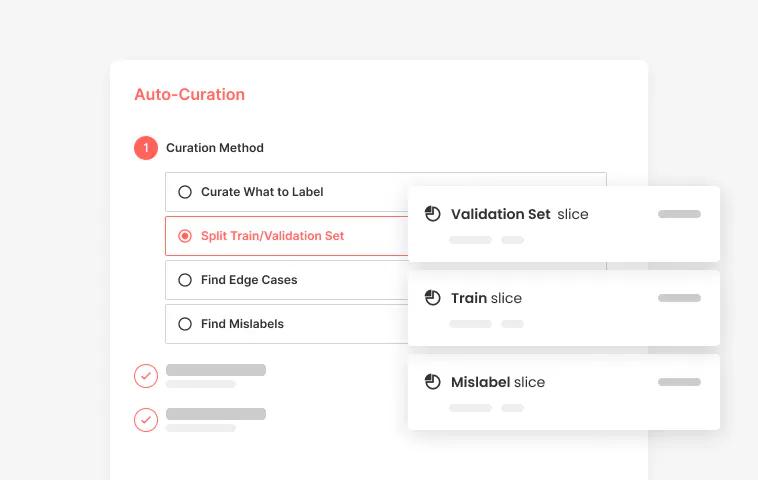
Auto-Curate is an AI-based tool that uses high-quality curation algorithms to curate computer vision demands scale
Too often, as machine learning engineers or project managers, we rely heavily on good old-fashioned intuition and brute force when curating data for computer vision. While there’s no doubt this can work from time to time to solve small problems, the risk of introducing issues like bias, subjectivity, and overfitting, among others, grows as the problem or task we are trying to solve grows. And, to be frank, it’s not all that scalable.
That’s where Auto-Curate comes in. Auto-Curate is an AI-based tool that uses high-quality curation algorithms to curate the following for you at scale:
- Training sets
- Validating sets
- Edge cases
- Mislabels
Want to know more about how our curation algorithms work and what they could do for you? We’ve been hard at work recently putting our AI to the test on popular datasets, and we’re pretty excited with the results. Here’s what we’ve published so far:
- LOCO: 15% improvement in precision and recall across object classes.
- MS COCO: Achieved similar performance as the control with 75% less data.
Scatter Visualization and Analytics
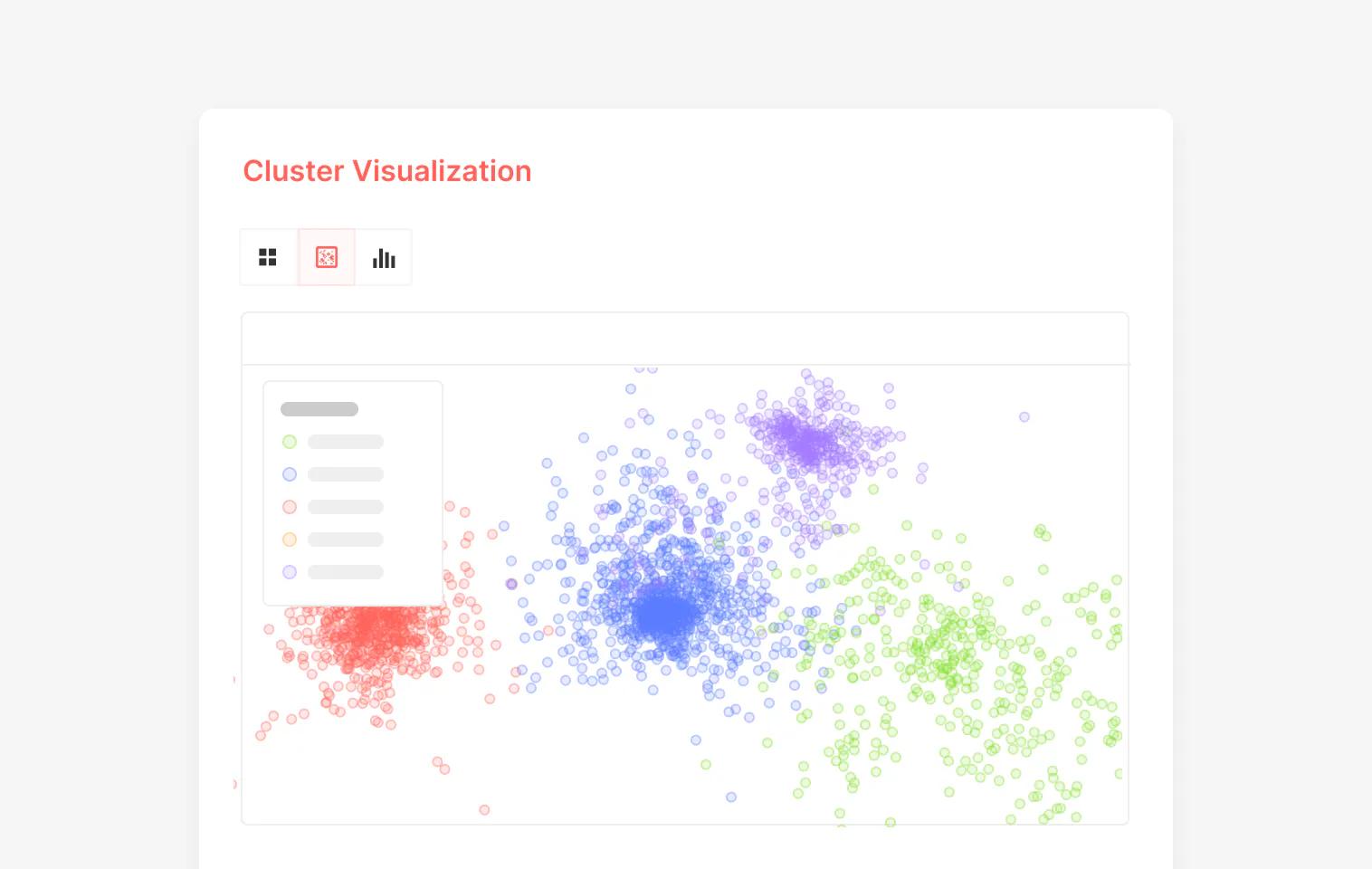
Scatter Visualization and Analytics
Finally, we have some tools to help you better understand patterns and potential outliers in your datasets. To start, we have scatter visualization, which uses embeddings to cluster images or objects over a two-dimensional space based on visual similarities, allowing you to visualize distribution in seconds. Another way is by consulting our in-depth analytics dashboards, which provide insight into the distribution of metadata, annotation types, and object classes in your data pool, among other helpful information.
Stay tuned for many how-to guides on all of these new features!
Enjoyed this? Subscribe to our mailing list to hear more from us!
Learn More About Curate
As the scope and scale of your data and feature sets grow, the ability to build and manage performant models without increasing labeling time, effort, or spending is vital to maintaining ROI. That’s where Curate can help. Talk to our sales team today for a personalized look at how much easier intelligent curation can be!
Related Posts

Product
How to Build & Deploy an Industrial Defect Detection Model for a Lucid Vision Labs Camera

Sam Mardirosian
Solutions Engineer | 15 min read

Product
How to Build & Deploy a Safety & Security Monitoring AI Model for an RTSP CCTV Camera
Sam Mardirosian
Solutions Engineer | 15 min read

Product
How to Use Generative AI to Properly and Effectively Augment Datasets for Better Model Performance

Tyler McKean
Head of Customer Success | 10 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.