Insight
How Auto-Curate Can Save Labeling Resources: An Experimental Study Using MS COCO

Hyun Kim
Co-Founder & CEO | 2023/05/04 | 4 min read

Introduction
Superb Curate is a powerful data curation tool designed for machine learning teams to easily curate their training datasets and build more robust, high-performing models. One of the key features of Superb Curate is the Auto-Curate feature, which helps to improve the accuracy and robustness of machine learning models by selecting the most valuable data to include in training or validation sets.
In this blog post, we will discuss how our Auto-Curate feature can help build robust object detection models on the MS COCO dataset. We conducted two experiments to show that, with our feature, you can achieve higher accuracy with much less labeled data and fewer resources spent.
MS COCO Dataset
The Microsoft Common Objects in Context (MS COCO) dataset is a widely used benchmark for image recognition and object detection. Released in 2014, this dataset contains over 330,000 images depicting more than 2.5 million object instances, making it one of the largest and most diverse datasets for object recognition. The dataset includes 80 object categories, such as animals, vehicles, household objects, and more. Each object is annotated with a bounding box and a label, which makes it a valuable resource for training and evaluating object detection models. The annotations are also available in different formats, such as COCO JSON, making integrating with machine learning frameworks easier.
One of the unique features of the MS COCO dataset is its focus on complex scenes with multiple objects, occlusion, and varying levels of scale and orientation. This makes it a challenging dataset for object detection models to perform well on, but also more representative of real-world scenarios. Additionally, the dataset includes images taken in natural settings rather than artificially created ones, making it more diverse and representative of the world around us. With its large size, rich annotations, and complexity, the MS COCO dataset has become a standard benchmark for object detection, segmentation, and image captioning tasks in the computer vision research community.
Experiment Setup
We created several subsets for comparison purposes for our experiments on the MS COCO dataset. Specifically, we created two training sets - the Full Train Set, which contains 118,287 images, and the Curated Train Set, which includes only 30,000 images, just 25% of the train set. We also created two validation sets - the Full Validation Set, containing 5,000 images, and the Curated Validation Set, containing 2,000 images, which is 40% of the complete validation set.

The Curated Train Set used in the experiment was 75% smaller than the Full Train Set
Our goal in creating the Curated Train Set was to see if our algorithm could select the most valuable data to include in the training set, enabling us to train a performant model with much fewer data. To achieve this, we utilized our curation algorithm, which includes rare examples in the dataset by sampling from embedding clusters that are sparse, i.e., small clusters with not many images that share visual similarity. This ensures that our curated datasets are well-balanced, including examples from all object categories, and contain the most valuable data to improve the model's accuracy and robustness. By comparing the performance of models trained on the full and curated train sets, we could measure the effectiveness of our curation algorithm in selecting the most valuable data.
We believe this experiment has great significance, especially for smaller companies and startups that may not have the resources to curate a large dataset. With our Auto-Curate feature, these companies can select a small subset of the MS COCO dataset and train their models with comparable performance to models trained on the entire dataset. This is a cost-effective solution that saves time and money while still achieving excellent results.
Experiment 1: Curated Train Set vs. Full Train Set
In our first experiment, we trained two models using the Full Train Set and the Curated Train Set, respectively. We then measured their performance using the Full Validation Set.
The results showed that the Curated Train Set leads to a model with only a 0.3% drop in performance compared to the Full Train Set. We saw a minimal, less than 0.05% change in the F-1 score across almost all object classes. This is an impressive result, considering that we used only 25% of the training data and still achieved similar performance.
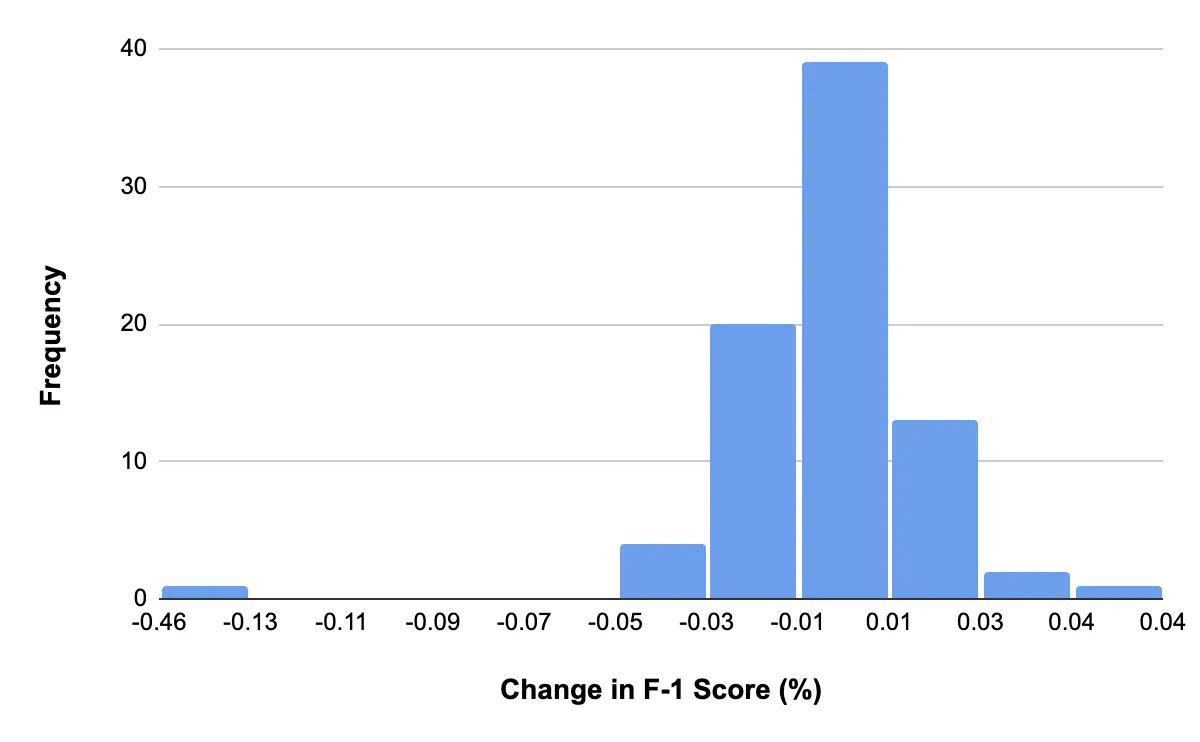
Histogram of percentage change in the F-1 score when using Curated Train Set, evaluated with the Full Validation Set.
The Hair Drier class was the only class that was an outlier in the experimental results with a drop in performance. We will dive deeper into why this happened later in this post.
Experiment 2: Curated Train Set vs. Full Train Set with Curated Validation Set
In experiment 2, we aimed to evaluate the performance of models trained on the Full Train Set and Curated Train Set using a Curated Validation Set. The curation algorithm we used to create the Curated Validation Set selects rare examples in the dataset by sampling from sparse embedding clusters, but at the same time, avoids examples with a relatively high probability of being mislabeled. This means that the curated validation set is likely to contain more edge cases or rare cases for each object class, making it a more robust evaluator of model performance.
To understand why this is important, let's consider the hypothetical example of an autonomous vehicle that needs to detect pedestrians. A model that is trained on a dataset of images that predominantly feature pedestrians walking on sidewalks may perform well in the typical case. However, suppose the model has not been trained on rare cases of pedestrians in unusual locations, such as crossing the street in low-light conditions or walking in groups. In that case, it may fail to recognize pedestrians in these edge cases. Therefore, evaluating the model's performance on a curated validation set that includes these edge cases is essential to ensure that the model is robust and can accurately identify pedestrians in all scenarios.
In experiment 2, we found that the Curated Train Set resulted in a model with a 0.4% improvement in performance compared to the Full Train Set when evaluated on the Curated Validation Set. This shows that the Auto-Curate feature can select the most valuable data to include in the training set. Thus, training a model on a smaller amount of well-curated data can still produce comparable results to training on the full dataset. Moreover, using a curated validation set that includes more rare cases can provide a more accurate evaluation of model performance, which is crucial for real-world applications.
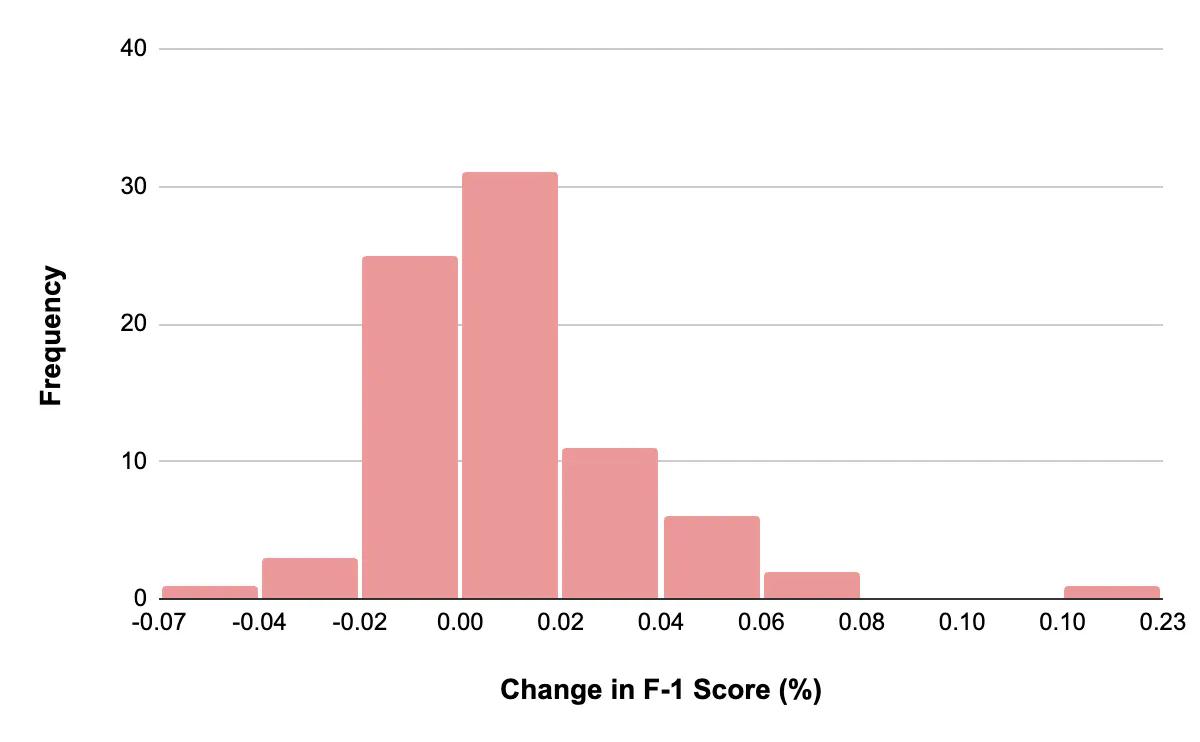
Histogram of percentage change in the F-1 score when using Curated Train Set, evaluated with the Curated Validation Set.
Similar to what we observed in experiment 1, the Hair Dryer object class stood out as an outlier in the results. This is not surprising, considering that Hair Dryer is the least frequent object class in the MS COCO dataset.
Let’s dive deeper into why the Hair Drier class stood out as the outlier. Here are the Hair Drier class instances included in the Full and Curated validation sets.

Hair Drier class instances included in the Full and Curated validation sets.
As you can see from the examples above, the full validation set for the hair drier class contains both typical and atypical examples. Some examples are labeled as hair dryers even though it's difficult for humans to identify them based on the bounding boxed region alone. Including these bad examples in the validation set can lead to flawed model evaluation.
In contrast, our Auto-Curate algorithm identified and removed these bad labels from the validation set. Our curation algorithm takes into account not only selecting rare cases but also additional factors, such as the likelihood of the object being mislabeled. With this curated validation set, we were able to conduct a more accurate evaluation of the model performance, especially for rare or edge cases that may be mislabeled in the original dataset.
This is particularly useful in real-world scenarios where mislabeling can happen for various reasons, such as noise in the data, human error, or limitations of the labeling tools. By removing these bad labels and including more accurate and representative examples in the evaluation set, we can obtain a more reliable estimate of the model's performance in real-world settings.
Conclusion
Our experiments on the MS COCO dataset demonstrated the significant impact of using Curate's Auto-Curate feature in selecting the most valuable data for the training set. With this approach, machine learning teams can create robust models using only 25% of the training data - a remarkable achievement. This result underscores the importance of data quality over quantity and how well-curated data can lead to highly effective models, even with a small dataset.
By leveraging our curation algorithm, teams can choose rare examples from sparse clusters and avoid mislabeled data to build a well-balanced dataset. This process ensures that the most valuable data is included in the training set, allowing teams to improve model accuracy and robustness. This approach also leads to significant resource savings as teams can obtain impressive model performance with a smaller, curated dataset, saving time and money.
If you're interested in learning more about Curate and how it can help you build more robust object detection models, we encourage you to contact our team, who’d be happy to run you through a personalized demo! With its user-friendly interface and powerful capabilities, Curate is the perfect tool for anyone looking to optimize their machine learning models.
Related Posts

Insight
How to Restart an AI Project That Stalled for Lack of Data—with Just 10 Images
Hyun Kim
Co-Founder & CEO | 7 min read

Insight
Three Years of the Few-Shot Object Detection Challenge: Mapping the Global Vision AI Landscape
Hyun Kim
Co-Founder & CEO | 7 min read

Insight
⑪ Germany's Physical AI Moment: Siemens, BMW, and the Robot Unicorn Counteroffensive
Hyun Kim
Co-Founder & CEO | 15 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.