Product
Introducing Model: Easily Train and Deploy Powerful AI Models With Just A Few Clicks

2023/08/10 | 4 min read

Today, we’re excited to announce the launch of Superb Model. Model is Superb AI’s solution to the problems many companies face when trying to adopt computer vision or even build on early successes:
- A dedicated ML team is often needed just to get started
- Custom model building can require significant know-how and computational resources
- Deploying and integrating AI into existing products, services, or business logic can be tricky
- Knowing what changes to make to your training data based on model performance isn’t always clear
- It can take months to build prototypes and test feasibility, meaning a long time to value
Model aims to significantly reduce these barriers to entry by making it possible to train and deploy high-performance AI models fast with no coding or ML experience required.
At the same time, companies with ML teams can use Model to complete critical early steps in the ML lifecycle before investing significant time and energy in custom model building.
What is Model?
Model is part of Superb AI’s ongoing mission to make AI more accessible for every team and company. This means, just as with Superb Label (Custom Auto-Label) and Superb Curate (Auto-Curate), automation is a key component of the product. Model consists of:
- Foundational models for kickstarting AI projects (Superb AI and open-source)
- AutoML for automatic model training and hyperparameter optimization (Bayesian Optimization)
- Performance evaluation metrics that are easy to understand (class-wise precision, recall, IoU, etc.)
- One-click cloud deployment and endpoint monitoring (volume, frequency, etc.)
Model aims to make the barrier of entry to AI as low as possible, regardless of whether you’re looking to deploy an end-to-end computer vision solution for the first time or just need to build a few proofs-of-concept.
The initial release of Model includes bounding box detection. Support for more annotation types will be following soon!
Who is Model for?
Model is perfect for product, software development, ML, and other similar teams. How, you might be asking yourself? Especially considering only one of the above has ML experience.
Let’s unpack this a bit.
Product and Software Teams
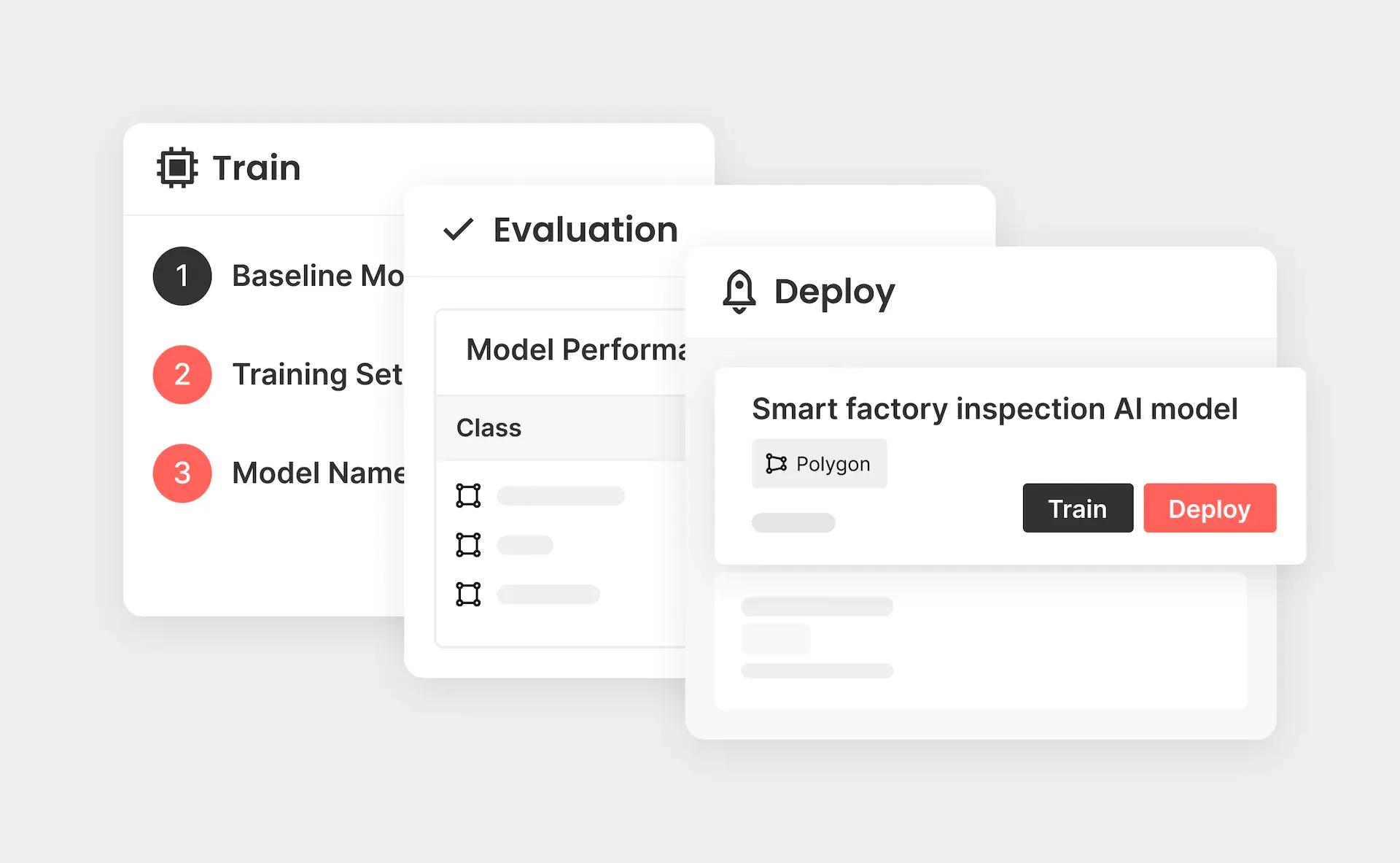
Because Model provides a powerful form of AutoML that abstracts away and automates many of the complexities of model training, evaluation, and deployment, product or software development teams with no ML background or custom models can simply follow a few simple steps to go from a training dataset to a trained model.
Here are a few ways product teams are using Model:
- To quickly integrate computer vision into an existing product
- To determine if they have enough training data by measuring model performance
- To create an MVP to determine if the company should invest in an internal ML team
ML Engineers

AutoML is also a valuable tool for ML teams because it can save them significant time when paired with foundational models. While actual model training time can vary considerably, it takes most teams at least a month, if not longer, to develop and then deploy a custom model.
This development is often done before success or ROI can be appropriately measured, so plenty of rework is usually required. What Model provides is the ability to train and test state-of-the-art models to measure the performance of your training datasets and create a baseline for overall performance before ever putting in the hard work required for custom model building.
Those baseline performance metrics can also be helpful after you build your custom models, allowing you to benchmark against open-source models on the same data (hint: we’re also working on model diagnostics for your data for Curate).
Here are a few ways ML engineers are using Model:
- To quickly test concept feasibility on different models
- To rapidly build a prototype or POC to measure ROI early in a project
- To directly test the impact of their training data on the performance of leading models
Kickstarting Model Training and Deployment With Superb Model
- Step 1: Pick a baseline model
Model provides several options to help you quickly get started with model training and deployment. This initial release includes support for Faster-RCNN and Superb AI’s home-grown AI models. Support for additional open-source models, such as YOLO and other transformer-based ones, is coming soon. You can also retrain models already trained on the platform, making iterating on models as easy as initial training.

Not sure which model to use? Each option includes helpful information so you can get a feel for which choice is right for your use case or performance needs, such as estimated inference speed, throughput, and more.
- Step 2: Select your training and validation sets
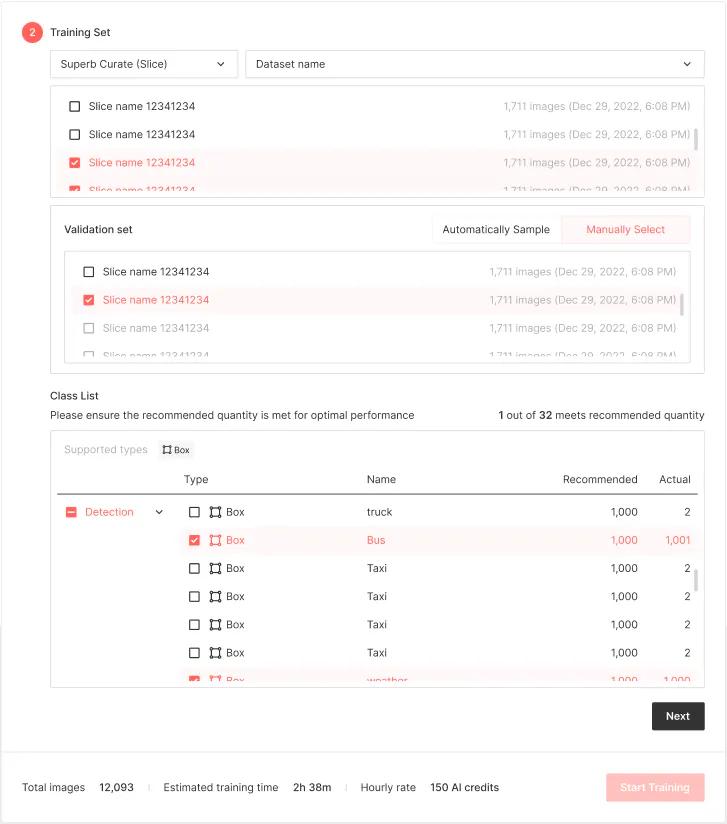
Once you’ve selected your baseline model, it’s time to choose your training and validation sets. Your training set can contain whatever data you need, including slices created within Superb Curate. Alternatively, you can select a dataset and train your model directly within Curate. For the validation set, you can either manually choose the data yourself, or Model will automatically sample the data for you, meaning one less thing to worry about when evaluating model performance.
Next, you’ll choose the classes you want to train your model on. To simplify and automate this process as much as possible, Model provides helpful recommendations for your data, including how many training examples of each object type or class you should include to ensure the best results. For example, the ‘recommended quantity’ metric provides an idea of whether or not your selected dataset should be used as is or further refined.
Once you’ve finalized your choices, all that’s left to do is name your model and click train. Our AutoML technology will do the rest for you, including preselecting the optimal hyperparameters for your chosen model.
- Step 3: View your model’s performance and iterate accordingly
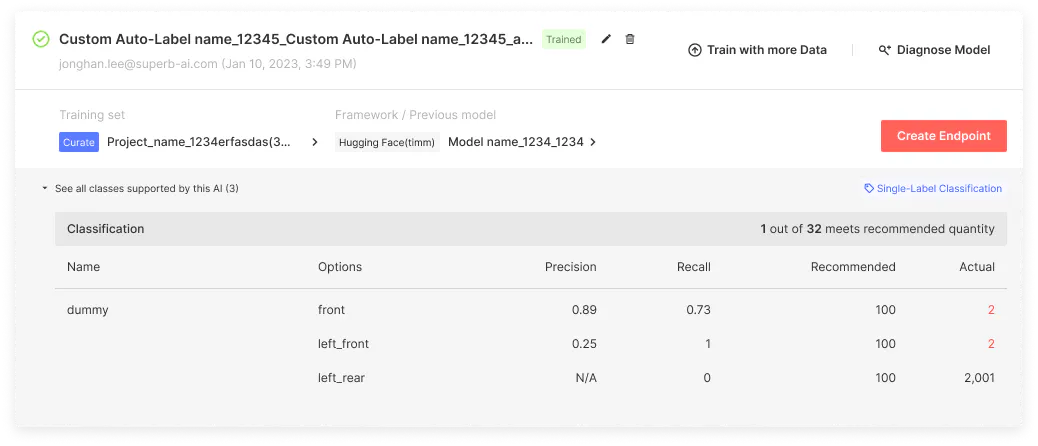
Now that you’ve trained your initial model, it's time to view the results and refine and optimize as needed. Since Model eliminates a major bottleneck, that being all the steps and nuances involved in model training, you can spend much more time iterating on your data without slowing down your project.
Model provides a centralized hub for all your trained models and all the tools needed for quick iteration. This includes:
- Model accuracy metrics based on your validation set
- Visualization of model performance on sample data
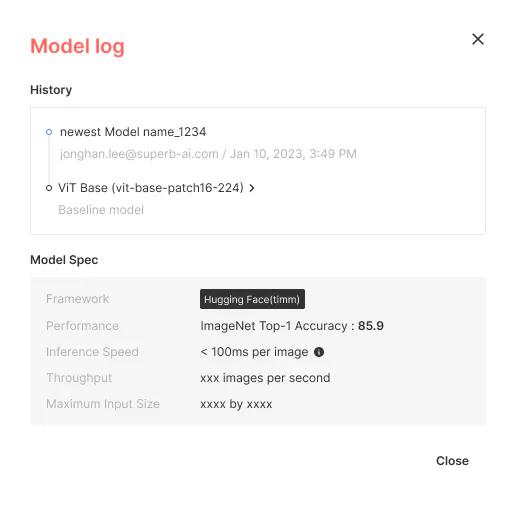
- Full dataset and model logs
- The ability to train your model with more data
- Comprehensive search and filtering for managing your trained models
- Deep model and data diagnostics via Curate (coming soon!)
Once you’ve analyzed the performance of your trained model and determined that it’s acceptable for your use case, it’s time to put it into action.
Looking for a fast way to improve your ground truth dataset after reviewing model performance? Superb Label’s custom auto-label, coupled with Superb Curate’s auto-curate, can be used together to seamlessly build new datasets or iterate on existing ones in a fraction of the time.
- Step 4: Deploy your model to the cloud with one click

A model is, of course, of little use until deployed, even when you are just using it to test the quality of your data or create a baseline for performance for more advanced models. However, the transition from model development to model deployment has long been a major challenge for companies since the skills and experience required for both tend not to overlap.
With Model, we’ve made deployment as easy as possible. All you have to do is click ‘Create Endpoint’ to create an API endpoint. And endpoint, in tech-speak, simply means a remote computing device that allows back-and-forth communication between that device and the network to which it is connected (in this case, between your trained model and you).
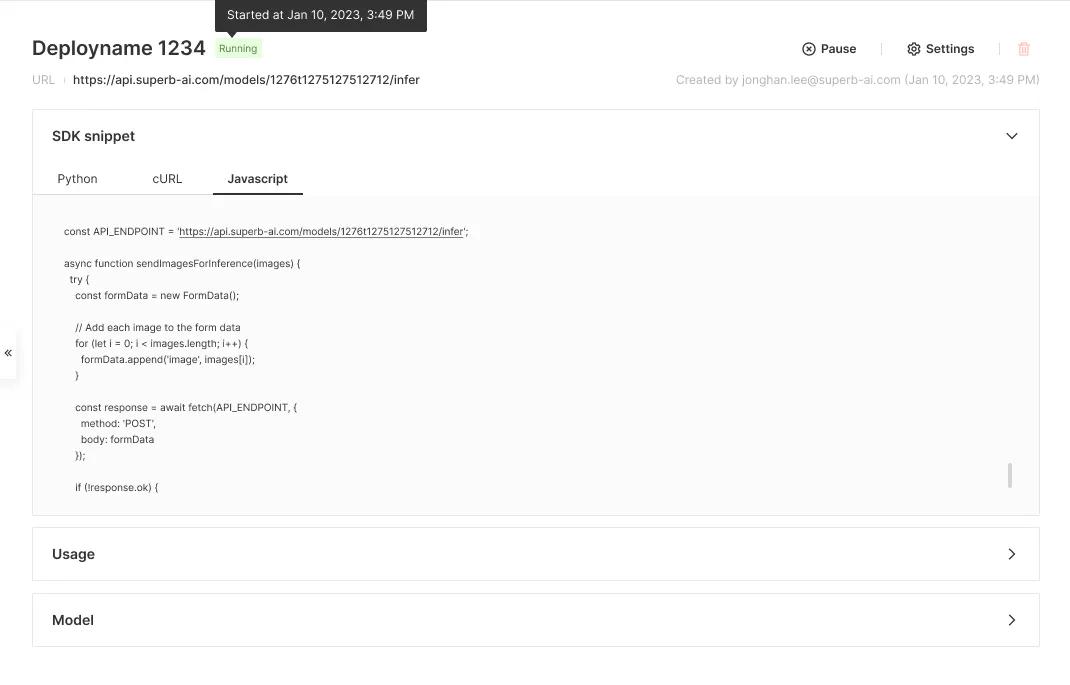
💡 Don't have any ML or software engineers to help you integrate your trained model into your product, service, or business logic? Never fear! We’re currently working on a graphical interface that will allow you to simply plug and play Model’s API wherever needed.
- Step 5: Monitor your deployed model
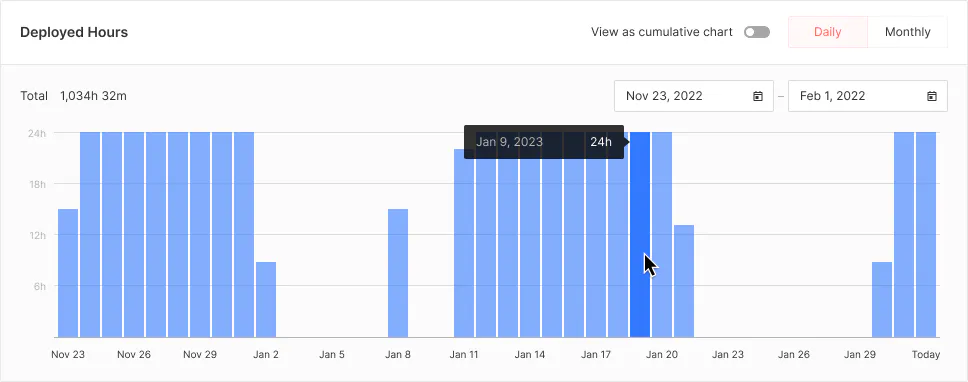
Model deployment, of course, isn’t the end. It should be continuously monitored to keep track of issues, determine performance with increased traffic, and so on. Model provides complete control over endpoint usage, including the ability to start, stop, and pause an endpoint whenever needed with a click of a button. It also provides endpoint visualization metrics like volume and frequency over defined periods.
And that’s it! In just five easy steps, you can train and deploy your very 1st (or 100th) model.
Conclusion
Whether you’re just getting started adopting computer vision, or already have an entire team of in-house ML engineers and data scientists who develop custom models, Model can save you significant time and cost. And we’d love to show you how!
You can try it out for yourself with a 14-day trial, or our sales team would be happy to give you a personalized demo.
Related Posts

Product
How to Build & Deploy an Industrial Defect Detection Model for a Lucid Vision Labs Camera

Sam Mardirosian
Solutions Engineer | 15 min read

Product
How to Build & Deploy a Safety & Security Monitoring AI Model for an RTSP CCTV Camera
Sam Mardirosian
Solutions Engineer | 15 min read

Product
How to Use Generative AI to Properly and Effectively Augment Datasets for Better Model Performance

Tyler McKean
Head of Customer Success | 10 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.