Tech
How ZERO Won the CVPR 2026 Foundational Few-Shot Object Detection Challenge: A Technical Walkthrough of the Winning Solution

Hyun Kim
Co-Founder & CEO | 2026/06/19 | 10 min read

Key Takeaways
- Superb AI’s winning solution is a five-stage pipeline built around its Vision Foundation Model ZERO: data and prompt discovery, fine-tuning, reclassification, test-time augmentation, and multi-source fusion.
- Its design philosophy follows two complementary principles captured in the title of the technical report: Discover the Unknown, which expands the limited information available from few-shot data through prompt search and pseudo-labeling, and Reconsider the Known, which uses a lightweight module to verify the model’s initial predictions.
- Multimodal prompting that combines text, visual examples, and contextual information addresses a core challenge in industrial and medical domains, where category names are often specialized or ambiguous.
- The solution achieved an average mAP of 53.9—2.3 points higher than the second-place joint team from Fudan University and Lenovo, 3.8 points above the previous year’s best result, and 20.6 points above the official GroundingDINO baseline.
- The difference came down to model weight. While some competing teams relied on extremely large models to refine their results, Superb AI developed a lightweight, scalable reclassification module designed for practical deployment. A patent application for the module is currently in progress.
Superb AI took first place in the Overall Track of the CVPR 2026 Foundational Few-Shot Object Detection Challenge with a system built around ZERO, its proprietary Vision Foundation Model designed for industrial applications.
Part 1 explored the significance of the result. This article walks through how the winning solution works, stage by stage. It can also serve as a guide before reading the technical report, “Discover the Unknown and Reconsider the Known: Specializing Multimodal Promptable Detectors for Diverse Domains,” co-first-authored by Kyeongryeol Go and Hyundong Jin, and reviewing the accompanying public code.
The Problem: Why General-Purpose Object Detection Breaks Down in Industrial Domains
The difficulty of few-shot object detection is not simply that there is too little data. The more fundamental challenge is the domain gap.
Models trained on general internet imagery often experience a sharp decline in performance when exposed to unfamiliar industrial data, such as X-ray, thermal, or aerial imagery. The official baselines created by the organizers using widely adopted general-purpose models such as GroundingDINO and Qwen2.5-VL recorded performance below 1% on multiple datasets. The Roboflow20-VL challenge dataset was composed of 20 specialized domains specifically to put this limitation to the test.
A second challenge compounds the first. Category names in manufacturing, healthcare, and security are often technical abbreviations or semantically ambiguous terms. Conventional open-set models such as GLIP and GroundingDINO, which rely heavily on text prompts, may therefore struggle to understand consistently what they are being asked to detect.
Superb AI’s solution was designed to address both challenges directly: the domain gap and category ambiguity.
The Two Pillars of the Winning Solution: “Discover the Unknown and Reconsider the Known”
The title of the technical report captures the solution’s design philosophy:
- Discover the Unknown: Expand the limited information available from a small number of examples through optimized prompt discovery and pseudo-labeling.
- Reconsider the Known: Reevaluate the model’s initial detections through a lightweight verification process to improve accuracy.
“First understand and learn from an unfamiliar environment, then revisit the model’s own answers.”
These two principles run through the entire pipeline.
The Winning Pipeline in Five Stages
① Data and Prompt Discovery
Before fine-tuning begins, the first stage optimizes the inputs provided to the model. Two components are central to this process:
Prompt Alias Search
The default class names provided by a dataset often contain too little information, particularly when they consist of abbreviations or specialized terms.
To address this, the team generated candidate aliases describing the visual attributes of each class. It then performed a greedy search for the optimal combination, adding aliases one at a time for each domain until accuracy stopped improving.
ZERO can evaluate arbitrary combinations of aliases through a single cached computation, making the search highly cost-effective. Instead of requiring a person to refine each prompt manually, the model identifies which descriptions work best for each domain.
Visual Example Selection
The conventional approach is to use all 10 examples provided for each category. Superb AI took a different approach.
Using every example can introduce noise or bias. The team therefore applied embedding-based subsampling that accounts for diversity, selecting only the most effective visual examples.
This methodology belongs to the same family of techniques used by Curate in Superb Platform to identify meaningful data. It is one example of how Superb AI’s research and product capabilities reinforce each other through a shared technical foundation.
② Expanding the Training Data Through Pseudo-Labeling
Another challenge in few-shot learning is sparse annotation.
When objects remain unlabeled within an image, the model may incorrectly learn to treat them as background. To address this issue, the pipeline includes a pseudo-labeling stage in which AI generates and filters preliminary labels to expand the training dataset.
Specifically, ZERO and SAM3 generate candidate object bounding boxes. Regions from boxes that exceed a confidence threshold are then passed to Qwen3-VL-32B, which either classifies them into one of the domain categories or rejects them as unknown. The filtered labels are combined with the original ground-truth annotations to create an expanded training dataset.
External models are used only as supporting tools during this data preparation stage to generate labels for fine-tuning. ZERO remains the model responsible for the actual object detection task. This architecture is fully documented in the published technical report.
The process reflects the expertise Superb AI has developed through its work in automated data labeling: securing high-quality labels quickly and accurately.
③ Fine-Tuning ZERO: Domain Adaptation Through Two-Stage Factorized Search
ZERO is then fine-tuned for each domain using the expanded dataset.
With 20 different domains, exhaustively searching the entire hyperparameter space would have been impractical. At the same time, applying a single configuration across every domain would have produced suboptimal results.
The team therefore divided the search into two stages. First, it selected the learning rate and text augmentation strategy. It then determined which modules to train, including the backbone, detection head, and language adapter.
This design was based on the empirical observation that the optimal learning rate and augmentation strategy remained relatively stable regardless of which modules were selected for training. By separating the search into two stages, the team could identify effective domain-specific configurations at a practical computational cost.
④ Lightweight Reclassification: Reconsidering the Initial Predictions
A detection model fine-tuned with few-shot data may successfully identify where an object is located, but still misclassify what the object actually is. A single confidence threshold is not sufficient to filter out these errors.
Superb AI introduced two mechanisms to address this problem.
First, confidence thresholds are calibrated separately for each category. Second, a lightweight secondary classifier trained on the few-shot examples reexamines the class label assigned to each detection. The classifier is applied only to high-confidence detections because its own predictions can become unstable for low-confidence results. Based on its assessment, the system retains or reassigns the class label. If confidence remains insufficient, the detection is removed.
The detector and classifier therefore take on distinct roles:
- The detector maximizes recall by identifying candidate objects.
- The classifier reexamines the class label assigned to each candidate.
The difference came down to weight.
While some competing teams used models with tens of billions of parameters for this refinement stage, Superb AI chose a lightweight, scalable architecture. The design was intended not only to improve challenge scores, but also to support direct deployment in real customer environments. Superb AI is currently pursuing a patent application for this module.
⑤ Test-Time Augmentation and Multi-Source Fusion: Extracting the Final Gains
During inference, the system applies test-time augmentation by combining multiscale inference, horizontal flipping, and tiling. Tiling helps recover small or densely packed objects within large images. The resulting detections are then consolidated using class-aware non-maximum suppression.
In the final stage, the system fuses detection results generated from different configurations, backbone sizes, and prompting approaches, including both text and visual prompts.
One particularly important decision was the level at which this fusion was performed.
Because the evaluation metric, mAP, is calculated as the average of category-level scores, the team applied category-level routing rather than selecting a single source for an entire domain. For each category, the system selects the best-performing source, while top-performing sources are combined using techniques such as Weighted Boxes Fusion.
The final ensemble used three ZERO checkpoints of different sizes, within the maximum of three models permitted by the challenge rules. This stabilized the predictions and completed the winning pipeline.
All tuning was performed exclusively on validation data. Test data was used only for the final submission, preserving the rigor of the evaluation.
What Made the Difference?
The official GroundingDINO baseline achieved an average mAP of 33.3, while the previous year’s best score was 50.1.
Superb AI achieved 53.9, outperforming the baseline by 20.6 points, the previous year’s best score by 3.8 points, and the second-place joint team from Fudan University and Lenovo, which scored 51.6, by 2.3 points.
The performance gap did not come from a single technique. It was the result of all five stages working in concert. You can see it very clearly even at a category level.
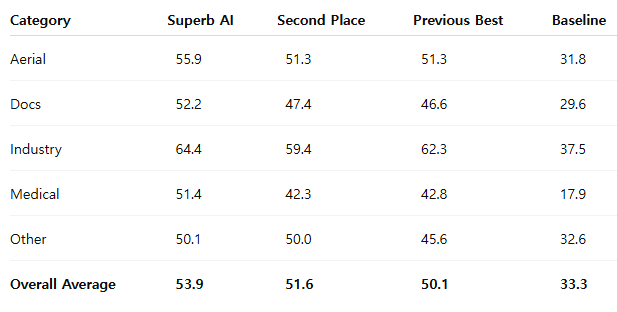
Superb AI ranked first in five of the seven categories. Its score of 64.4 in the Industry category was high enough to be highlighted in the organizers’ presentation. In the particularly challenging Medical category, Superb AI led the second-place team by more than nine points.
The result also supports the hypothesis that multimodal prompting becomes especially effective in domains where category names are ambiguous. This advantage was demonstrated quantitatively in the Medical category, one of the most difficult domains in the challenge.
Underlying the entire solution is Superb AI’s data-centric AI philosophy.
The connected workflow of rapidly securing high-quality data through pseudo-labeling (②), selecting the most meaningful examples through data and prompt discovery (①), and validating model outputs through reclassification (④) directly reflects capabilities Superb AI has developed through its commercial products and services.
Beyond the Score: A Product-Oriented Solution
The publicly released zero-fsod code also reflects Superb AI’s product-oriented approach. The detector is abstracted as an HTTP service, allowing the company to protect the model weights and source code while making the overall pipeline and API contract publicly available.
This architecture balances two objectives: satisfying the challenge’s reproducibility requirements and protecting the company’s intellectual property. It is also consistent with ZERO’s positioning as a production-ready product rather than only a research model.
“The goal was not to deploy the largest possible model, but to design a method that could adapt to real-world environments quickly and with a lightweight footprint,” said Kyeongryeol Go, Machine Learning Engineer at Superb AI. “ZERO’s efficiency allowed us to test multiple hypotheses within a short period and identify the optimal combination.”
The latest version of ZERO, which served as the foundation of the winning solution, is available now on AWS Marketplace.
The workflow validated in the challenge—rapid domain adaptation using only a small amount of data—will also be introduced progressively to Superb Platform through domain-specific module capabilities.
Frequently Asked Questions
Q. Does ZERO perform object detection on its own? What roles do SAM3 and Qwen3-VL play?
ZERO performs the actual object detection. External models such as SAM3 and Qwen3-VL are used only as supporting tools during the pseudo-labeling stage to generate training labels for fine-tuning. This architecture is fully documented in the published technical report.
Q. Why is multimodal prompting important?
Category names in industrial and medical domains are often specialized or ambiguous, making it difficult for a model to understand their visual meaning from text alone. ZERO combines text, visual examples, and contextual information to resolve this ambiguity. In the Medical category, it outperformed the second-place team by more than nine points.
Q. What does the lightweight reclassification module do?
The module relies on the detector’s localization result, but reexamines the object’s class label to improve classification accuracy. By using a lightweight, scalable architecture instead of an extremely large model, it is better suited to real-world deployment. A patent application for the module is currently in progress.
Q. How much did performance improve over the baseline?
The solution improved the official GroundingDINO baseline from an average mAP of 33.3 to 53.9, a gain of approximately 20.6 points. It also surpassed both the previous year’s best result of 50.1 and the second-place score of 51.6 to take first place in the Overall Track.
Q. Can I use this technology today?
Yes. ZERO, the foundation model behind the winning solution, is available now on AWS Marketplace. The technical report and pipeline code for the winning system have also been made publicly available.
Related Posts

Tech
Building Superb AI’s Synthetic Data Pipeline with NVIDIA Isaac Sim
Hyun Kim
Co-Founder & CEO | 7 min read

Tech
Superb AI “Proprietary AI Foundation Model Project” Phase 2: Key Takeaways on Digital Twin Assetization
Hyun Kim
Co-Founder & CEO | 7 min read

Tech
Superb AI Achieves Phase 1 Milestone in the State-Run Proprietary AI Foundation Model Project (1.08M Robot Data)
Hyun Kim
Co-Founder & CEO | 10 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.