Insight
A Practical Guide to Feature Embeddings for ML Engineers

2023/05/08 | 5 min read
In the rapidly evolving world of machine learning, Feature Engineering with Embeddings: A Practical Guide for ML Engineers seeks to provide a comprehensive and hands-on approach to the essential task of feature engineering using embeddings.
As ML engineers continually strive to improve the performance of their models, the process of extracting useful and insightful features from raw data continues to be a formidable challenge. This article aims to guide ML engineers through the process of harnessing the power of feature embeddings to enhance their computer vision models and maximize the insights derived from their data.
In this practical guide ,we'll delve into the various techniques and methodologies used for feature engineering with embeddings, including popular techniques such as pre-trained convolutional neural networks (CNNs) and autoencoders. We will also explore the advantages and disadvantages of different embedding techniques, as well as how to optimize them for specific tasks.
We Will Cover:
- Creating feature embeddings with image data
- Applications of feature embeddings
- Tools and Techniques for Implementing Embeddings
- Evaluating and iteratively improving embeddings
- Revolutionizing curation with embeddings
Feature Embeddings with Image Data: Techniques and Applications
Feature embeddings, also referred to as feature extraction or feature learning, is described as the process of converting raw input data, typically images, into a lower-dimensional, continuous vector representation that retains the essential information needed for a given task.
These vector representations, or embeddings, encapsulate relationships and patterns in the data and can be efficiently used by machine learning algorithms to make accurate predictions or classifications. By transforming the data into these compact representations, ML engineers can more easily handle large datasets, improve model performance, and gain deeper insight into the underlying structure of the data.
Techniques for Creating Feature Embeddings with Image Data
Feature embeddings play a pivotal role in the realm of machine learning and computer vision, transforming complex, high-dimensional image data into compact, lower-dimensional representations while retaining the essential information for various tasks.
1. Convolutional Neural Networks (CNNs)
CNNs are a popular choice for creating feature embeddings for image data, as they can automatically learn hierarchical representations from raw pixel data. The convolutional layers capture local patterns like edges and textures, while the deeper layers of the network learn higher-level abstractions like object parts and scenes. The final layers of the network can be used as feature embeddings for various tasks.
2. Unsupervised Learning Methods
Unsupervised learning techniques, such as autoencoders, can be used to create feature embeddings for image data without the need for labeled data. Autoencoders learn to compress the image data into a lower-dimensional representation (the bottleneck layer) and then reconstruct the original image from this representation. This bottleneck layer can then be used as a feature embedding for the image data.
3. Pre-trained Networks and Transfer Learning
Pre-trained networks, such as VGG, ResNet, and Inception, can be used as feature extractors for image data. By removing the final classification layer and using the output of the preceding layer, ML engineers can obtain feature embeddings for their image data. Transfer learning allows engineers to fine-tune these pre-trained networks for specific tasks, leading to even more powerful feature embeddings.
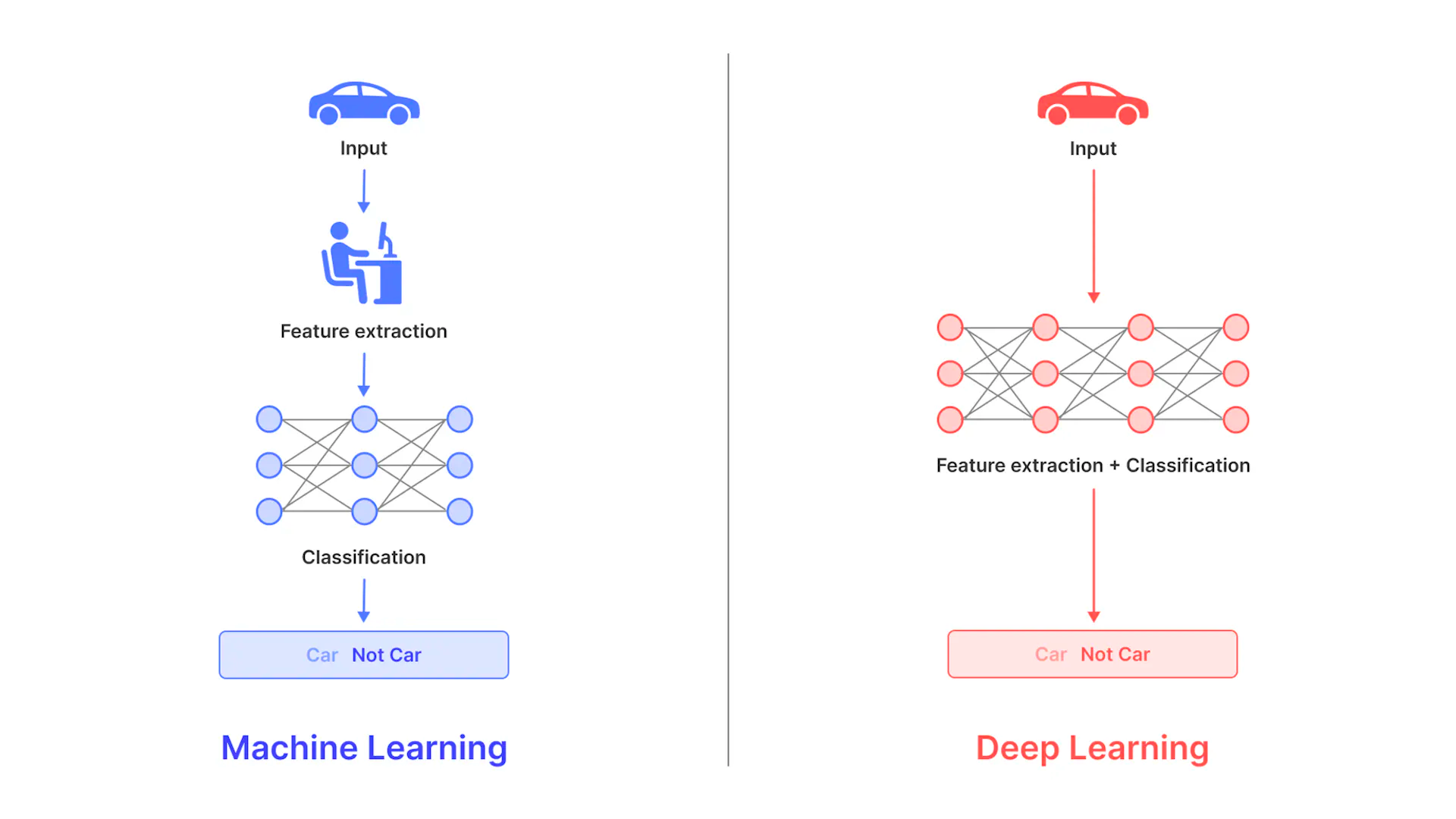
Pre-trained Networks and Transfer Learning
Image Generation and Style Transfer
Feature embeddings can be used as input to generative models, such as generative adversarial networks (GANs) or variational autoencoders (VAEs), for image generation and style transfer tasks. The embeddings allow the models to capture the high-level structure and content of the image data, enabling the generation of realistic and visually appealing images.
Feature Embeddings in Practice: Tools and Techniques
Successfully implementing feature embeddings in neural networks requires a solid grasp of the tools and techniques that can facilitate the process, ultimately enabling machine learning engineers to optimize their computer vision models.
1. Deep Learning Frameworks
Popular deep learning frameworks, such as TensorFlow, PyTorch, and Keras, provide built-in support for implementing and training neural networks with feature embeddings. These frameworks offer a range of pre-processing tools, layer types, and training algorithms, making it easier for ML engineers to design and optimize their computer vision models.
2. Pre-trained Models and Transfer Learning
Several deep learning frameworks and libraries, such as TensorFlow Hub, PyTorch Hub, and Keras Applications, provide access to pre-trained models that can be used as feature extractors. ML engineers can fine-tune these pre-trained models using transfer learning techniques to adapt the feature embeddings for their specific tasks.
3. Dimensionality Reduction Techniques
Tools like Scikit-learn offer a range of dimensionality reduction algorithms, such as PCA, t-SNE, and UMAP, which can be used to visualize and analyze the feature embeddings. These techniques can help ML engineers understand the structure and relationships within their embeddings, informing the design of more effective models.
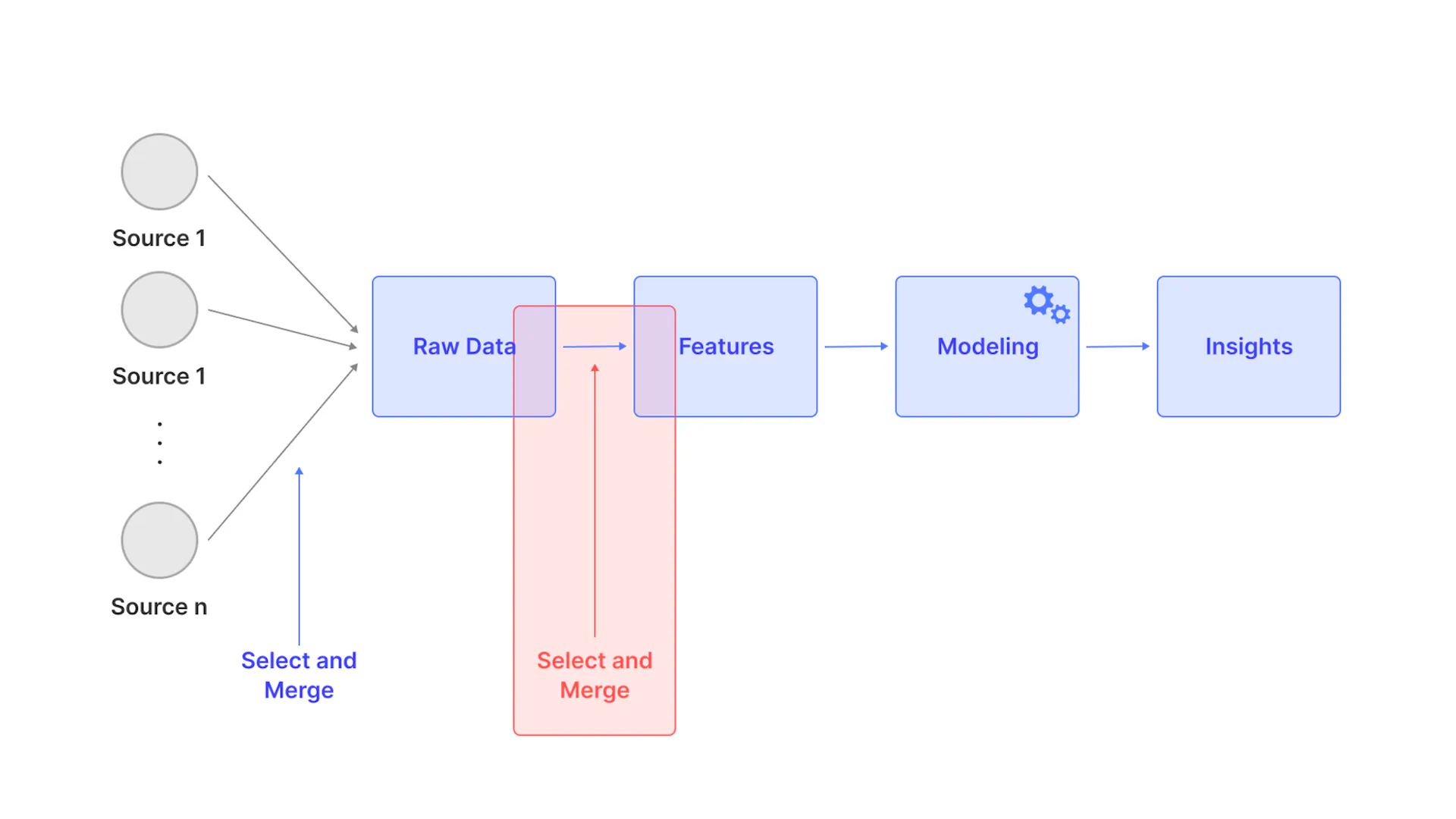
Dimensionality Reduction Techniques
Evaluating and Iteratively Improving Embeddings and Datasets
The process of feature engineering with embeddings is an iterative one, requiring continuous evaluation and improvement to ensure that the embeddings and datasets are optimized for the best possible performance in computer vision models.
1. Embedding Visualization
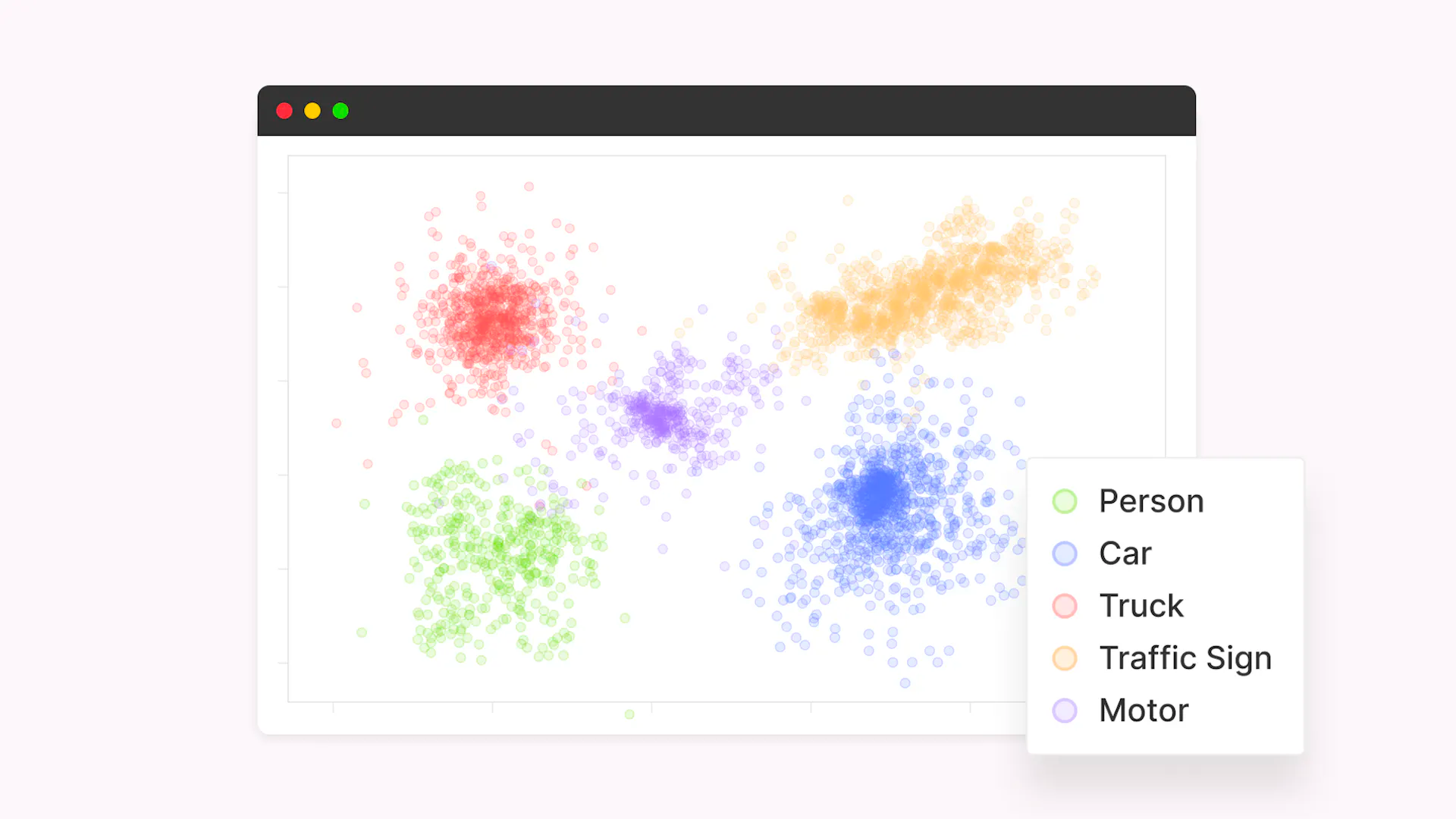
Visualizing the feature embeddings using dimensionality reduction techniques can provide valuable insights into the relationships and structure within the data. By analyzing these visualizations, ML engineers can identify potential issues, such as overlapping classes or outliers, and make informed decisions about their model architecture and training strategy.
2. Quantitative Evaluation
ML engineers can use quantitative metrics, such as classification accuracy, precision, recall, and F1-score, to evaluate the performance of their feature embeddings on specific tasks. By comparing the performance of different embedding techniques and model architectures, engineers can identify the most effective approach for their problem.
3. Data Augmentation
If the evaluation of feature embeddings reveals issues with the training and validation datasets, such as class imbalance or insufficient variation, ML engineers can employ data augmentation techniques to generate additional training samples.
Tools like the Keras ImageDataGenerator and the Albumentations library offer a range of augmentation techniques, including rotation, scaling, and flipping, which can help improve the quality of the feature embeddings and, ultimately, the performance of the computer vision model.
4. Hyperparameter Tuning
Iteratively refining the hyperparameters of the neural network, such as the learning rate, batch size, and the number of layers, can lead to significant improvements in the feature embeddings. Techniques like grid search, random search, and Bayesian optimization can be used to systematically explore the hyperparameter space and identify the best combination for a specific task.
5. Active Learning
Active learning strategies involve iteratively refining the training dataset by selecting the most informative samples for manual labeling. By incorporating these additional samples into the training data, ML engineers can improve the quality of the feature embeddings and the performance of their computer vision models.
Introducing Curate: Revolutionizing Data Curation with Feature Embeddings
Data is the lifeblood of machine learning, and its accuracy, comprehensiveness, and organization determine the efficacy of machine learning models. However, the data collection and curation process can be laborious, expensive, and resource-intensive. That's where our product, Curate, comes in – designed to streamline data curation for machine learning teams, making it faster, more efficient, and cost-effective.
Curate allows teams to analyze their training datasets, conduct metadata-based searches using queries, and visualize dataset distribution through feature embeddings projected into a two-dimensional space. Equipped with an array of features, Curate optimizes the data curation process, enabling teams to work with less training data while achieving similar or even better model performance.
Curate also helps build robust models by curating a validation set that closely mirrors real-world environments, and simplifies large-scale data uploads and management with queryable metadata.
By leveraging Curate and its embeddings, teams can cluster their data without the need to develop their own embedding models. Curate is tailored for machine learning teams that deal with data curation, labeling, and preparation for large-scale computer vision applications.
Its features and capabilities address common data challenges faced by machine learning practitioners, including selection bias, class imbalance, and outlier detection. Curate ensures that training datasets are comprehensive, accurate, and well-balanced, ultimately resulting in more effective machine learning models and improved business outcomes.
Related Posts

Insight
How to Restart an AI Project That Stalled for Lack of Data—with Just 10 Images

Hyun Kim
Co-Founder & CEO | 7 min read

Insight
Three Years of the Few-Shot Object Detection Challenge: Mapping the Global Vision AI Landscape
Hyun Kim
Co-Founder & CEO | 7 min read

Insight
⑪ Germany's Physical AI Moment: Siemens, BMW, and the Robot Unicorn Counteroffensive
Hyun Kim
Co-Founder & CEO | 15 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.