Insight
An Introduction to Automated Data Labeling

Caroline Lasorsa
Product Marketing | 2022/04/06 | 7 min read
Artificial intelligence has made waves throughout the past decade, where advancements are showing up in everyday applications. But getting there requires a ton of data, and curating that data and putting it into action requires a lot of work.
ML professionals have turned their attention to automated data labeling to implement ML models into real-world applications faster, and it’s easy to understand why. Every ML practitioner knows that a successful model requires thousands of data labels. Doing that manually means putting in thousands of hours of work, streamlining strategy, and overseeing each step in the process. For most practitioners, automated data labeling is a no-brainer.
The Automated Advantage
Data labeling in the machine learning pipeline is notorious for having large bottlenecks and slowdowns. It requires an expansive team to individually annotate the important objects in each image, which can sometimes be heavily detailed and time-consuming. Leading a team of labelers often entails ensuring that each person follows the same uniform pattern for every image because any differences can confuse the model.
In addition, hiring a team of in-house data labelers is very expensive, and outsourcing leads to miscommunications and errors. If you haven’t gathered by now, manual data labeling is tedious. And through each step, data annotation must be overseen by QA professionals, and mistakes must be corrected.
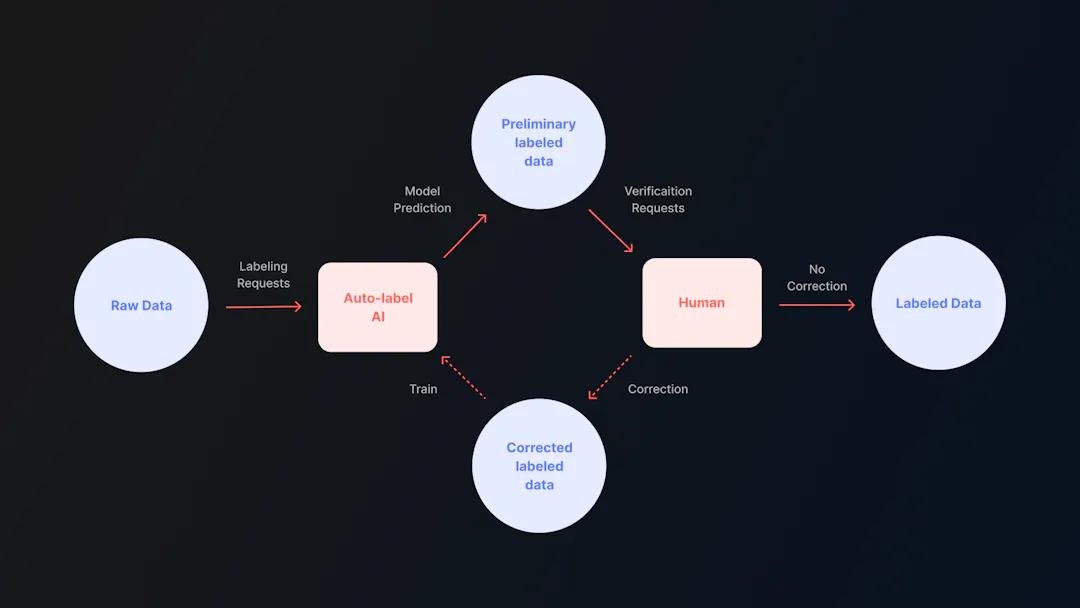
Adding automation to your machine learning project counteracts many of the issues described above. Though no project is entirely without a human-in-the-loop influence, minimizing that need reduces cost, minimizes error, negates the need for outsourcing, and ensures a faster end-to-end operation. Introducing automation into your workflow tackles the bottleneck that has been plaguing ML professionals since the introduction of artificial intelligence.
When to Use Automation
Automation makes the most sense for certain projects more so than others. When training a model that is reliant on thousands and thousands of data images, it’s almost impossible not to automate. Using only humans is a recipe for slowdowns and errors, so the more detail your project entails, the more helpful automation will be. In addition, certain types of labeling projects go hand-and-hand with automation, and implementing this strategy just works.
Automation not only reduces costs and minimizes errors but also negates the need for outsourcing and ensures faster end-to-end operations. The introduction of automation into your workflow addresses the persistent bottleneck in ML that has existed since the advent of artificial intelligence.
Introducing Auto-Edit: Auto-Labeling with a Human Touch
The emergence of new tools like Auto-Edit from Superb AI adds another dimension to automation in data labeling. Auto-Edit is a revolutionary AI-based annotation tool that automates the creation and editing of polygons across various object forms, including complex and irregular shapes.
This tool makes polygon segmentation—the most laborious, time-consuming, and precision-oriented task—simple and efficient. Auto-Edit can quickly and easily correct manually drawn or auto-generated polygons, enabling teams of all skill levels to work smarter, annotate faster, and repeat as needed until the job is completed.
Boosting Labeling Efficiency and Accuracy
By using AI to drive progress, Auto-Edit saves teams significant annotation time per data point, directly increasing project velocity and scaling potential while reducing labor/workforce requirements. This results in faster value delivery from AI investments with more and better data, particularly when used alongside other automation methods like auto-label and mislabel detection.
Moreover, unlike other forms of Interactive AI, Auto-Edit is a powerful tool for further automation, enabling teams to create ground truth datasets for training a custom auto-label with minimal effort and in less time. By using Auto-Edit for QA in each new iteration, the time to create a highly performant and accurate AI is significantly reduced.
This tool allows teams to complete polygon segmentation tasks faster with fewer clicks, increasing labeling speed and throughput while reducing fatigue. It also helps annotate complex or irregular objects more accurately, as the AI handles shapes that would be challenging to accurately annotate using traditional points.
Auto-Edit ensures more consistent annotation from object to object and provides a single-click correction feature to fix mistakes in real-time, reducing the likelihood of human error and QA time. The tool can also automatically revise a polygon generated via Auto-Label, further reducing QA time and effort, particularly when used in conjunction with Uncertainty Estimation (UE) to identify labels to review. It even offers the ability to automatically fix a polygon drawn with the pen tool, saving even more QA time and effort.
Models that Need Frequent Updating
In machine learning, your models are only as good as their real-world applications. In many instances, that means adapting to changing surroundings and accounting for newer innovations. With this in mind, ML practitioners need to keep updating their models so that they continue to deliver accurate results.
Self-driving cars are a prime example of an application that needs continuous revision. Car models change, street signs get updated, and overall surroundings rarely stay the same. Failing to update your model can lead to dangerous errors or lead to accidents in a concept known as model decay.
On the contrary, there are examples when frequent model revision does little to no improvement on model performance. Adding more data to a model necessitates more QA and oversight as well as additional training. Sometimes it just isn’t worth it. On the other hand, if your model degrades with time, fine-tuning a retraining schedule is a part of making sure performance remains optimal. If frequent retraining is a part of your project, then automated labeling is essential.
In addition, automated labeling can be programmed to identify edge cases and calculate confidence levels. When your model is automatically labeling images, identifying the ones that it’s less certain about can eliminate a lot of time in the QA process. Superb AI’s uncertainty estimation tool, for example, does exactly this. It identifies edge cases prone to error and flags them for a human to inspect. This reduces the amount of human involvement required without eliminating it entirely.
Types of Labeling for Automation
Automated labeling might feel like the best option if it’s available to your project type, and the good news is that it likely is. There is a plethora of annotation techniques that go hand-in-hand with a programmatic approach, which we will break down:
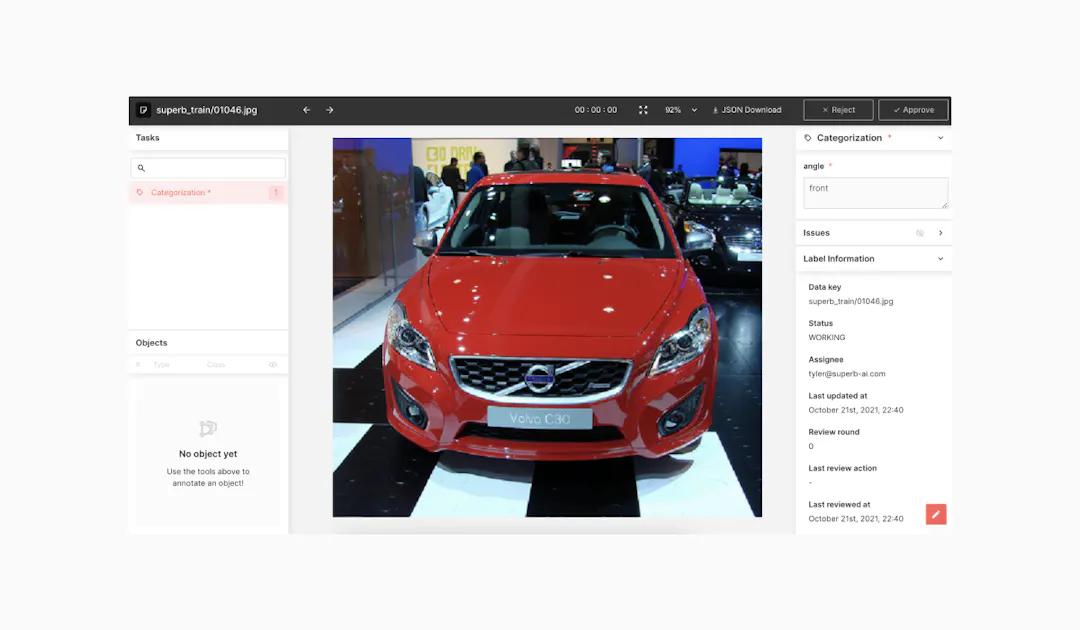
Image Classification
The least involved form of labeling for many initiatives is image classification. Annotators will set their projects up so that they can choose from a variety of tags to describe their data. Classification by itself involves selecting a label from a dropdown list; there is no drawing or outlining objects with a mouse and classification can be used as an add-on to other annotation projects, or it can stand alone. Once a model’s ground truth is created, automation can be added to identify the objects in unclassified data.

Bounding Boxes
Bounding boxes are also a simple annotation type, but that doesn’t mean that it isn’t highly effective for many applications. Here, an annotator simply clicks and drags their mouse until a box shape forms around the objects being labeled. Annotators should be careful to include all aspects of their labeled objects and avoid including extra space. Following these two rules alone makes forming a ground truth dataset a simple task.

Segmentation Tasks
Segmenting an image is a crucial, albeit complex, step in many data labeling projects. As a fusion of localization and classification, segmentation strives to generate an accurate outline of specific objects in an image. There are several techniques to achieve this, each with its unique considerations and challenges.
- Keypoint
Keypoints, for instance, attempt to join major points of an object to create a skeletal outline. This approach is typically used for biological and structural shapes, but it can be labor-intensive and requires a deep understanding of the object's structure. - Polygon
Polygon annotation, on the other hand, outlines the entire image. While this method provides a comprehensive view of the object, it can be painstakingly slow, especially for intricate and irregular shapes. The complexity of the object can often lead to inaccurate outlines and considerable time investment, thereby slowing down the entire data labeling process. - Polylines
Polylines are used to trace linear outlines of an object, such as a crosswalk. However, this method can be problematic when dealing with curvilinear or complex objects, leading to potential inaccuracies in the data set. - Semantic SegmentationSemantic segmentation, which traces each object's shape and categorizes them into classes, can be incredibly detailed but also time-consuming. It requires a fine balance between accuracy and efficiency, often leading to a slower labeling process.
- InstanceLastly, instance segmentation differentiates between different instances of the same object type, such as distinguishing individual people rather than grouping them together. While this offers a granular level of detail, it can be a time-intensive task and prone to human error, especially when dealing with large data sets.
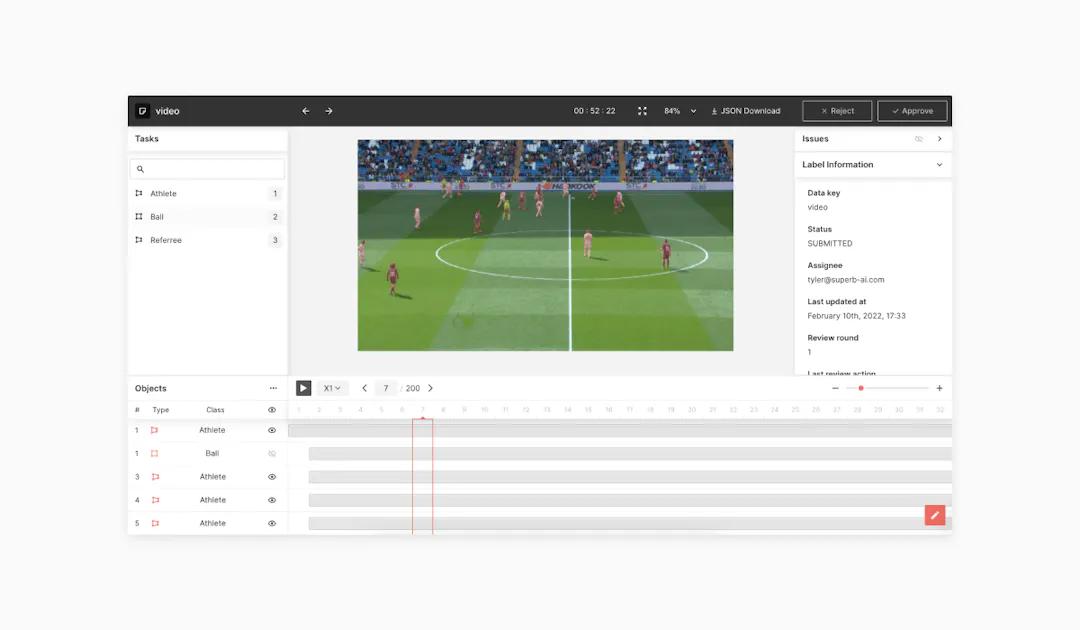
Video Labeling
For many computer vision applications, video is a major component. Surveillance, for instance, now has the capability of identifying suspicious activity such as theft. Learning to understand what stealing looks like involves a well-trained computer vision algorithm. The problem? Video footage contains a lot more detail and information than images do, so labeling is a lot more laborious. Breaking each file down by individual frames is tedious, and isolating them by applicability can take countless hours. Establishing ground truth and then training it to quickly label certain objects and people can therefore be a lifesaver.
When to Implement Manual Labeling
Automation is ideal for many scenarios and teams alike, as it streamlines the model-building process and reduces the overall time it takes. However, there are a few instances where programmatic implementation is less efficient.
Building Your Ground Truth Datasets
The initial part of data labeling involves annotating a small subset of data in which to train your model. This part relies entirely on human-in-the-loop intervention to ensure that the initial data is correctly annotated. Here’s why: jumping into automation relies on pre-trained datasets. More often than not, outside data is helpful but not perfect for every use case. Implementing an outside dataset into your model can be like fitting a square peg into a round hole, so it’s better to work with your own data and have humans do the first leg of the work.
Additionally, building a ground truth dataset also entails that each error in this phase is corrected and guided toward the next phase of labeling. When putting together a model, one must go through each image and ensure that labeling boundaries are tight and that the labels are done correctly. If left to automation in the initial phase, your model will miss some of the important labels and set the stage for an ineffective and inaccurate model.
What’s more, working with proprietary information presents its own obstacles. Regulated industries like medical, finance, and security pose a greater risk if not overseen by humans at least in the initial stage. Training a model to detect certain types of cancer is best left to medical professionals during the initial stage of building a ground truth. With financials, a breach in your model can prove disastrous, especially for accounts holding a lot of wealth. The same is true for government models. Without careful oversight into these models, the potential for harm is much greater.
Working with Edge Cases
Some datasets and models are more complex than others, meaning that an automated model is likely to miss the mark on some of the labels. When a model is mostly edge cases, it will likely need human intervention. Automating a model that requires more oversight than not is highly inefficient and cancels out any of its conveniences. In other cases, using people to QA images with lower confidence levels supersedes a model’s initial predictions. Working with edge cases requires a fine-toothed comb that often cannot be replaced with machines.
Is Automated Labeling the Right Approach for my Project?
In a short answer: probably. Automation has proven to accelerate the labeling process and help machine learning practitioners expedite their projects. Applications that involve frequent updating are easier to oversee when manual annotation is left out of the equation. In some cases, such as in the medical field, manual labeling takes away precious time from doctors and practitioners who are the only ones qualified to identify, and therefore properly label, abnormal growths or illnesses. This should only be necessary when building your ground truth dataset and during the QA process. The same principle applies to other scenarios as well: borrowing valuable resources like engineers to oversee the manual labeling process just doesn’t make sense.
Conclusion
Deciding which approach to take when labeling is entirely dependent on your project and which stage you’re on. If establishing ground truth, then automation is easy at first, but the results are unhelpful in the end. Taking that shortcut does nothing to save you time in the end and only yields an inaccurate model. On the other hand, complicated segmentation tasks only lead to headaches if done manually, and it’s an easy solution for less complex projects such as bounding boxes. Automation, then, is key in expediting and updating machine learning projects.
At Superb AI, we specialize in bringing automation to your machine learning and computer vision projects. As we continue to expand our capabilities, you’ll find a well-integrated combination of features that humanizes the data labeling process while also making it seamless and automatic.
Schedule a call with our sales team today to get started.
Related Posts

Insight
How to Restart an AI Project That Stalled for Lack of Data—with Just 10 Images

Hyun Kim
Co-Founder & CEO | 7 min read

Insight
Three Years of the Few-Shot Object Detection Challenge: Mapping the Global Vision AI Landscape
Hyun Kim
Co-Founder & CEO | 7 min read

Insight
⑪ Germany's Physical AI Moment: Siemens, BMW, and the Robot Unicorn Counteroffensive
Hyun Kim
Co-Founder & CEO | 15 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.