Insight
An Introduction to Segmentation

Caroline Lasorsa
Product Marketing | 2022/03/16 | 6 min read

Introduction
In machine learning, data-labeling is often thought of as a tedious, cumbersome process that requires a lot of time - but not necessarily a high skill level, although that, of course, depends on the subject matter at hand. Some use cases, such as those involving medical imaging, may require a highly-trained medical professional. That said, the simplest aspect of computer vision is still one of the most important.
Establishing accurate labels is the difference between a model that runs smoothly and a model that makes a fatal movement or mistake. Depending on the details of your project, your approach to data labeling will vary. Some machine learning models require little detail in their labels, while others are extremely intricate. When the latter is true, ML engineers want their datasets to be defined by more than just bounding boxes common in image localization; they’ll typically require their datasets to undergo a process known as image segmentation.
Image Segmentation: What is it?
Data sets often include images with multiple objects, all of which need to be labeled for your computer vision project. The detailed outline of these objects, where each object is grouped under its respective class, is image segmentation. This process combines image classification and image localization to produce a more precise map of the image. The level of detail required for your dataset is dependent on the project you’re working on. If, for example, you’re looking to locate dogs and cats in a set of images, then bounding boxes used for basic image localization should be fine. However, if you’re training your model to identify medical imagery, then accuracy and precision are paramount.
The first step: annotate your images
The backbone of your computer vision model is the thousands of annotated images used to train your data. Dissecting your raw data to make sense of the images themselves and assigning them a label is an annotation, but how you annotate your data is dependent on your project. Some are more complicated than others, and annotation is simply an umbrella term for a plethora of techniques ML engineers use to label their data and achieve ground truth. Before diving into segmentation, let’s begin by breaking down some of the annotation techniques your team will need to understand for more complex segmentation projects.

Polygon Annotation
When it comes to annotating your images, some models require a precise outline rather than just a simple bounding box. Because the objects in your image are often irregular, labeling teams must create boundaries around them to conform to their shapes. One highly effective method, known as polygon annotation, works by marking the edges of your object, similar to how you would trace a shape with paper and pencil. Polygon annotation is a popular technique for many computer vision applications in which datasets are made up of irregular shapes. This type of labeling is extremely useful, as most objects in the real world are not a perfect formation, such as a square or a rectangle. With this strategy, machine learning engineers are able to build accurate models that account for everyday objects, such as street signs and people.
Polygon annotation isn’t the only strategy that data labeling teams use to outline irregular objects in image sets. At Superb AI, we offer polyline annotation and keyline annotation in addition to polygon annotation and basic bounding boxes. Let’s dive a little deeper into some of these capabilities:

Polylines
Despite its name, polygon annotation is highly useful for everyday objects that don’t necessarily conform to an exact shape, but what happens when you’re looking to label objects that are a little more linear? In these instances, data labelers prefer to use polyline annotation. Here, your team draws a series of lines and connects them at a shape’s vertices. Polylines are commonly drawn around streets, sidewalks, and railroad tracks, for example. These are all objects with regular shapes and therefore require a tool that matches.

Keypoint Annotation
Keypoints are a little different from polygon or polyline annotation techniques. Where the aforementioned labeling methods concentrate on outlining various shapes in an image, keypoints work as a kind of skeleton within the shape you’re looking to label. They connect at the same points in the same order, along the x and y coordinates. Keypoints are best applied when the shapes in your image share the same structure, such as the human body or face. The drawback, however, is that keypoint annotation cannot be replicated with edge cases, where the shape you’re looking to label is somehow altered. Keypoints are commonly used to label video datasets where the subjects are moving. Examples include shoppers in a retail store, moving livestock, and sports analytics.
If annotation is the technique ML engineers use to outline their objects for labeling, then segmentation is the strategy your model uses to separate and distinguish individual objects in a dataset. Deciding how each dataset should be segmented is largely dependent on the project and field in which your team is working.
Types of Segmentation
Image segmentation strategies can look very different across different machine learning initiatives, but every team is working toward the common goal of achieving accuracy. However, the level of exactness is something that varies. In certain instances, a bounding box that properly frames the object in an image is considered accurate, while in others, your annotation comes down to individual pixels. Because of the different projects ML engineers find themselves using different types of segmentation, including instance, panoptic, and semantic segmentation.
When labeling your dataset, the level of detail needed is dependent on the project. At times, an image containing different types of vehicles will be grouped under the same class, teaching your model that a motorcycle, a truck, and a car are all one in the same. In other instances, your model will need to know that each type of vehicle is its own entity while accurately discerning each object in your dataset and in the real world.
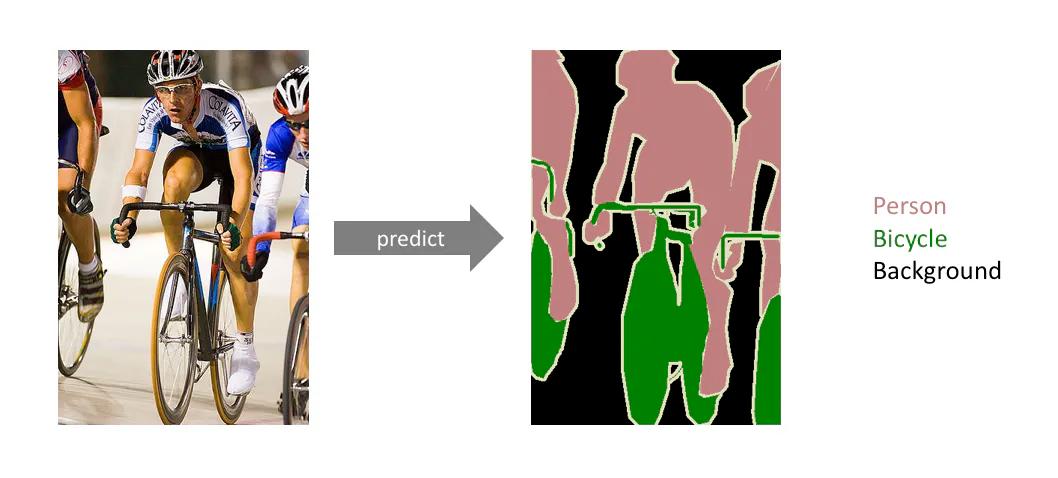
Semantic segmentation
In semantic segmentation, your model divides each object within your image into classes but does not specify any further than that. For example, our phones use semantic segmentation in everyday camera functions, such as portrait mode. Here, your smartphone camera lens can distinguish between the foreground and background using semantic segmentation, creating that blurred effect that’s become popular. On social media, filters use semantic segmentation to identify our faces before mapping out where to place dog ears or fake eyelashes. In essence, semantic segmentation only needs a top-level understanding of detail.

Instance segmentation
Conversely, instance segmentation gets into more specific classifications within your dataset. While semantic segmentation looks at overall groupings, instance segmentation classifies the objects individually. The need for instance segmentation is usually seen in examples like autonomous vehicle datasets and medical imaging, where a high level of detail is important. However, because of its high level of specificity, instance segmentation takes a lot of time to achieve a high level of accuracy. In addition, it is not known in advance how many instances will be in each image, meaning that your model must make adjustments throughout the labeling process.

Panoptic segmentation
We’ve come to understand how different types of image segmentation are needed for different projects and how the level of detail for each dataset is dependent on the needs of your model. While semantic segmentation explores a dataset with the least amount of detail, instance segmentation dives deeper into the particularities of a dataset. It’s hard to imagine a machine learning model that requires even greater precision, but with panoptic segmentation your images are annotated with more detail than the aforementioned methods.
Before diving into panoptic segmentation, it’s essential to understand the two aspects of image segmentation: stuff and things–two very nondescript words that are official terms in machine learning. “Things” refers to anything that can be counted in an image, such as a dog, car, or lamp. “Stuff”, on the other hand, is the filler details in an image, like the background, the sky, or a path. In panoptic segmentation, we look at both the “things” and “stuff” that make up an image, meaning that this is the most complex type of image segmentation.
Because of its level of detail, panoptic segmentation is used for similar datasets to that of instance segmentation. Medical imaging and self-driving vehicles commonly use panoptic segmentation, as both feature specific objects as well as ambiguous backgrounds. In practice, panoptic segmentation is best applied to images that depict a scene rather than just an object, utilizing segmentation masks to annotate each item as well as its backdrop. Taking into account every detail in an image rather than a few items proves beneficial for instances when your model needs to know both. In an autonomous vehicle application, for example, understanding the backdrop of a scene helps the car understand all of its surroundings, not just oncoming traffic.
Conclusion
Data annotation and segmentation require a lot of manpower, time, and money to build an accurate, usable dataset, especially when your model requires a high level of detail on the pixel level. This is very true of many scenarios, including robotic surgeries, package delivery vessels, and autonomous vehicles. Annotating hundreds of thousands of images and segmenting them into detailed labels is a gigantic undertaking, and it is something that ML engineers are all too familiar with. At Superb AI, we understand the headache of annotating and segmenting images, so we’ve created an ergonomic approach to streamlining your workflow. Establish ground truth faster and with less images, and use our uncertainty estimation tool to audit your datasets quickly.
Data labeling does not need to be complicated. With Superb AI, you can achieve accurate datasets with unparalleled accuracy. Request a demo today.
Related Posts

Insight
How to Restart an AI Project That Stalled for Lack of Data—with Just 10 Images

Hyun Kim
Co-Founder & CEO | 7 min read

Insight
Three Years of the Few-Shot Object Detection Challenge: Mapping the Global Vision AI Landscape
Hyun Kim
Co-Founder & CEO | 7 min read

Insight
⑪ Germany's Physical AI Moment: Siemens, BMW, and the Robot Unicorn Counteroffensive
Hyun Kim
Co-Founder & CEO | 15 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.