Insight
How To Best Manage Raw Data for Computer Vision

Hanan Othman
Content Writer | 2022/11/10 | 7 min read
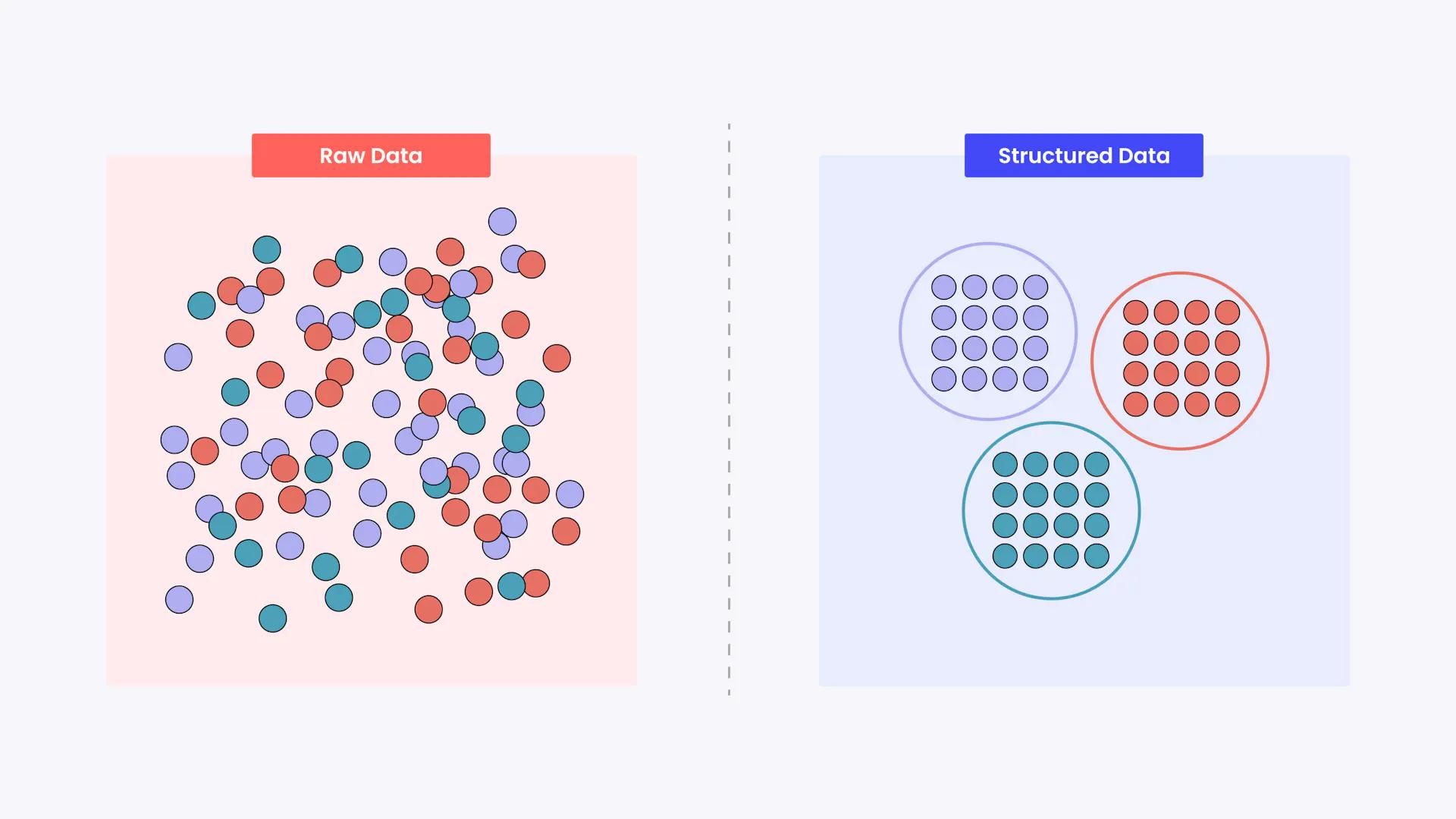
All data requires processing to some degree to be properly read and followed by an AI model, and computer vision (CV) systems are no different.
In this article, we'll be breaking down the first, fundamental step of preparing data for custom model training, which entails acquiring raw data, methods of secure data management and covering the best practices for preprocessing; prior to starting the labeling or annotation work cycle.
Collecting data for models often takes more time and effort than the cyclical and repetitive endeavor of training them. For that reason, the work that is done during the data acquisition, is widely considered as crucial to a model's long-term performance potential.
To work raw data into a usable state, the sources it's gathered from should be chosen mindfully and according to the objects it needs to detect and analyze in a specific, live environment. Beyond the means of acquiring the right type of data for a CV model, there's the question of managing it for convenient and secure access by a development team as a whole; from data prepping to model design and maintenance following deployment.
Continue reading to learn more about the particulars of handling raw data and how to start off your CV project on the right foot through that initial and important initial step.
We will cover:
- How To Utilize Raw Data For Model Learning Approaches
- Raw Data Acquisition Strategies
- Storing Raw Data Securely
- Methods of Managing Stored Raw Data
- Closing Note on Raw Data Management
Structuring Unstructured Data
To understand how to best handle raw data, it's helpful to start by understanding the major differences between the different stages of data going from being raw or unstructured to being preprocessed correctly.
Raw Data for Unsupervised Learning
To use raw data to benefit unsupervised learning, it requires interpretation. There are multiple patterns that can be derived from the input data, but they need to be identified; and that is possible through machine learning (ML) algorithms like clustering and association to distinguish the patterns and provide the most accurate outputs possible.
Since an ML algorithm is used to interpret the data and derive meaningful insight to train a model, it's considered "unsupervised" or a method that doesn't require human involvement to execute data processing.
Raw Data for Supervised Learning
In the case of a supervised learning approach; which is the most common method for training models, a labeled dataset (that starts out as raw data that needs labeling), is required to help the model learn from the data and make correct predictions.
From the annotated or tagged data, which are provided by human labelers, the model picks up on the same patterns as it needs to for unsupervised learning; except in the case of supervised learning, it picks up on these patterns further through model training.
If successful, then a model is capable of making accurate new predictions using the labeled data as a standard or a base to work off of. This standard is formally referred to as ground truth. It's worth the effort of perfecting this standard or baseline dataset, because its accuracy is then transferred to a trained model.
Raw Data and Semi-Supervised Learning
Semi-supervised learning by definition, utilizes both labeled and unlabeled forms of data (as well as supervised and unsupervised techniques). It's a method that is helpful in the case that there isn't enough data, but still enough that a model can learn from it.
The models trained through semi-supervised learning use a small amount of labeled data, then provides the rest of the data that the model requires through the unsupervised method.
Preparing for Preprocessing
In all three approaches, data starts off in raw form and there's always the possibility of challenges or barriers to preparing it for processing. For one, the possibility of insufficient training data or lack of diversity in the data, along with the presence of noise, which makes the data impure and insuitable for training.
Preprocessing and the way labeling teams go about preparing raw data for one specific approach over another can impact how datasets meet training needs and models being able to make and follow through on the decisions they're meant to.
That means, specifically, to preprocess the data so that it's in the correct format for the algorithm to work with. This can necessitate techniques like scaling the dataset with normalization, or reducing input variables through dimensionality reduction, among others.

How To Acquire Raw Data
Acquiring data should mean one specific thing; collecting data from relevant sources, then storing it, cleaning it, preprocessing it, and continually retrieving it according to reiterative training needs during later model development phases.
Raw data is most commonly acquired through the following methods:
- Public or open-source databases.
- Creating the data in-house or internally.
- Manually
- Crowdsourcing
- Web scraping
In line with the process of acquiring data, there are also several approaches that can be organized into three separate segments.
- Data Discovery
- Data Augmentation
- Data Generation
The first approach, data discovery, involves finding or collecting data, the second, data augmentation; means to enhance or enrich the data, while the third and last is to generate the datasets - automatically, synthetically, or manually.
When putting these approaches into practice, there are certain questions that can help you determine which one is best for a project's use case. Such as where the data will be sourced from, how much data is actually needed, what type of data is most relevant or even necessary for a build, any anticipated issues that will require resolving or cleaning, like bias or noise.
How to Store Raw Data
Every model has iterative training needs, and once raw data is acquired, whether it be processed or not - needs to be put somewhere for safe keeping. Luckily, there are plenty of options, more than ever, available for the data storage and management needs of a labeling team.
There are two categories that data storage can fall into, either in cloud (online), or offline, and they separately utilize distinct frameworks to perform. Offline using batch cluster frameworks, while online executes through frameworks like PyTorch, TenserFlow, and others.
Offline data preprocessing usually involves the following steps:
- Extracting the characteristics and features needed from raw data.
- Cleaning and validating the input data.
- Converting the input data to a different, binary format, which helps the CV framework intake and process it.
Online data preprocessing, on the other hand, is associated with the following executions:
- Data is extracted and read from where it's stored online.
- Transforming data in many ways; batching, augmenting, etc, can only be performed when stored online.
- Loading the data for training computations to be executed.

How To Manage Stored Raw Data
A large volume of unstructured or raw data is a heavy burden from a storage and maintenance standpoint, understandably; and it's a common practice or belief that data should only be stored if a labeling and model development team plans on reprocessing the datasets at some point.
Take a look below at our listing of the most effective measures to maintain data and their associated storage methods.
Reducing Data File Size
First and foremost, before storing data anywhere it's important to keep in mind that when there isn't an imperative, project-focused need to maintain the data, then at the very least the image and video files should be compressed and formatted to take up less storage space. It might even be worth considering lowering the resolution of image data to help reduce its size, since it doesn't make much difference to a labeler.
Data Lakes Versus Data Pools
Data can take on varying forms and occupy more or less space depending on its volume and the nature or type of data that needs to be stored.
Cloud-based storage doesn't limit data in a physical sense, helpfully enough, but that doesn't mean it's disregarded entirely. There are two popular terms used to differentiate large scale datasets in the context of data storage; data lakes and data pools.
Data Lakes
Data lakes refers to a centralized, digital repository that allows CV teams to store both structured and unstructured data, regardless of scale. To reiterate but rephrase for emphasis, data does not require structuring to be stored in a data lake.
Following storage, the data can be analyzed through methods such as SQL queries, full text search, etc, and can be implemented to derive valuable insights from the data in its entirety.
Data Pools
In contrast, but hardly far off through interpretation, data pools are essentially one big large database made up of several other different databases. It provides the same access to CV practitioners, to analyze and query the data based on their data management and curation objectives.
Data pools work well as a centralized source, just like a data lake, for team members or users to share a considerable volume of information amongst themselves. But, they can be limited by their capacity to handle relational databases and standardized data.
Data Warehouse
On par with data lakes and pools, data warehouses analyze large scale relational data, but they stand out from them from a data structure and quality standpoint. The data is meant to be structured when stored and that enables faster SQL queries and richer results for analysis.
For that reason, the data is regarded as more reliable or trustworthy; since it's clean and enriched to the point that it can be depended on as a source of truth.
Short and Long-Term Data Management
Arguably the most obvious question that comes up when storing anything, including data, is how long and what that'll cost. Well, the rule of thumb can differ from team to team or company, because it really depends on the particular space and resource needs of a project.
A few to start you out or are worth considering are the following; training data should be retained for six months to up to 12 depending on the project scale and production issues, raw data should be retained for six months at most, video data is kept for two years as an organizational standard.
Data Management Done Right
All data starts out unstructured, more or less, and it's a labeling team's responsibility to preprocess it as thoroughly as possible, in order for it to be viable for model training and validation.
Managing data, especially once converted from raw form and correctly structured; requires a secure storage solution that also enables teams to access it as-needed at different points of the model development pipeline.
Considering the methods presented in this article, CV developers or practitioners should know what they're for, when debating how to best manage their data for long-term and collaborative use.
Related Posts

Insight
How to Restart an AI Project That Stalled for Lack of Data—with Just 10 Images

Hyun Kim
Co-Founder & CEO | 7 min read

Insight
Three Years of the Few-Shot Object Detection Challenge: Mapping the Global Vision AI Landscape
Hyun Kim
Co-Founder & CEO | 7 min read

Insight
⑪ Germany's Physical AI Moment: Siemens, BMW, and the Robot Unicorn Counteroffensive
Hyun Kim
Co-Founder & CEO | 15 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.