Insight
How to Crush QA and Build Ideal Ground Truth Datasets Using the Superb AI Suite

James Kim
Growth Manager | 2022/12/13 | 10 min read

Introduction
In Part 2 of this series, we discussed labeling types, their appropriate applications and use cases, and how to optimize the Superb AI Suite for your team. In Part 3, we examine quality assurance strategies that monitor and mitigate issues, best practices for auditing, how to establish ground truth datasets, and the best way to split your data.
Before jumping into automated workflows, your team must establish a successful machine learning pipeline with diversified datasets and proper auditing. Knowing how to divide your data and optimize the Suite’s interface can only help your team succeed.
In Part 3 of this series, we will cover:
- How to Manage Labeling Issues
- Auditing with Superb AI
- Building Your Ground Truth
- Exporting Your Data for Automation
Issue Management
It's important to know how to properly label your data, but identifying label errors is equally essential. A crucial part of this process is building a communications channel between team members.
Using Superb AI's 'Issues' feature to track labeling progress and annotation discrepancies is a powerful tool geared toward quality assurance.
With the help of the filtering tool in the label list, a user can populate only labels that have resolved issues once the issues have been resolved and resubmitted. This makes keeping track of your labeling progress much easier.
Here's how it works - For a walkthrough guide of the ‘Issues’ feature, watch the video below.
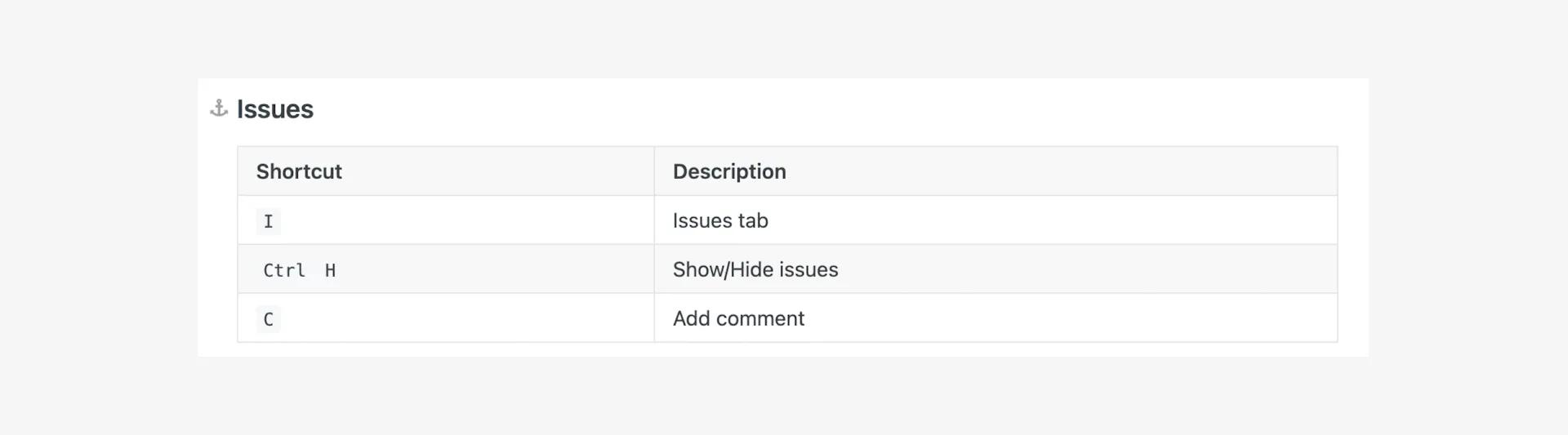
Issue shortcuts
Using the issue management tool in Superb AI is easier thanks to baked-in shortcuts, which include making the issues tab easier to use, hiding and showing issues based on visibility preferences, and adding comments. Check out the keyboard commands listed below:
Common Issues to Watch Out For
Classification errors
The process of classification assists your ML model in identifying and deciphering objects, but it's up to your labelers to perform this action correctly. In addition to being unable to recognize its surroundings, a label misclassification might lead to errors, which would be detrimental to model performance, which is something to watch out for as part of the QA process.
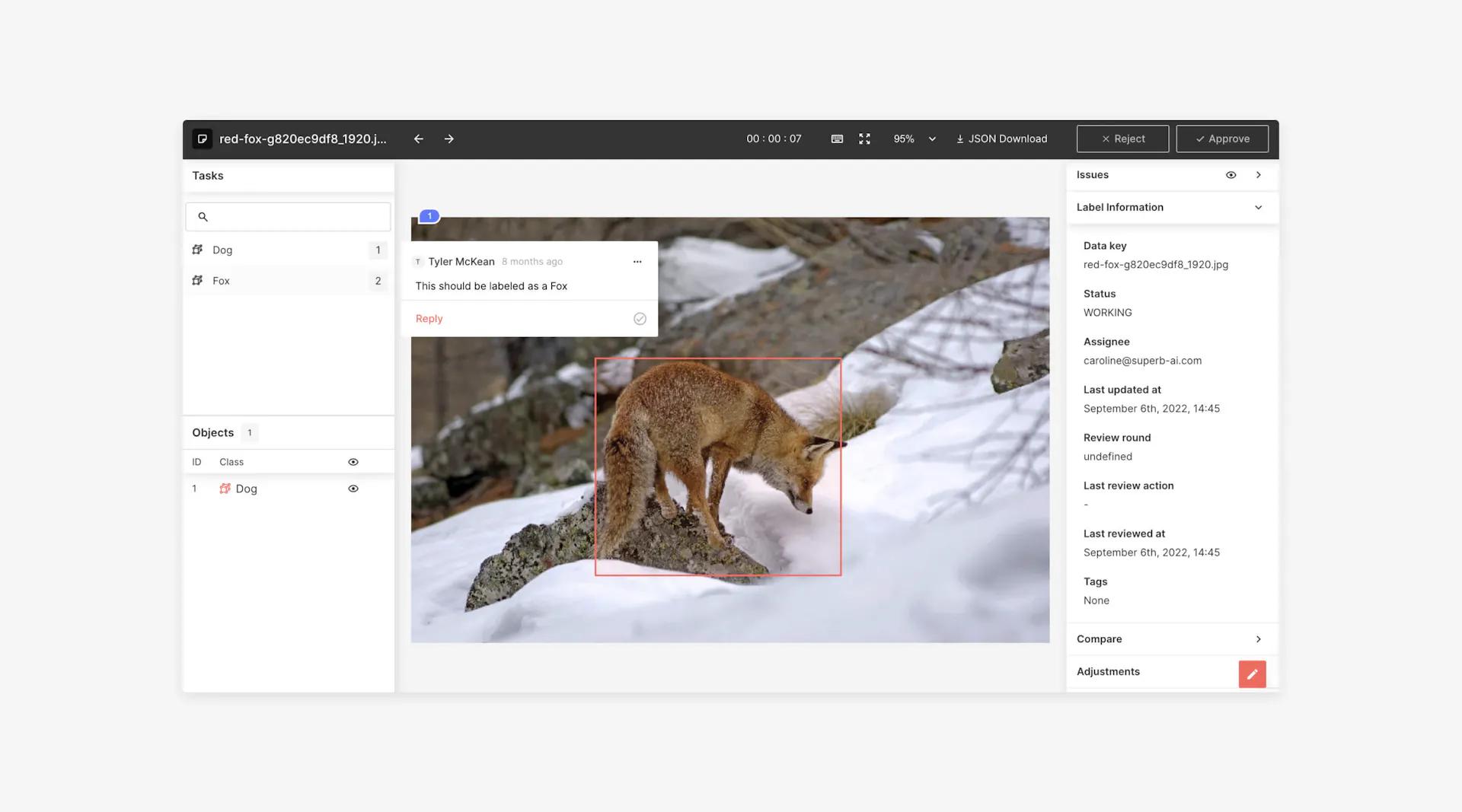
Imprecise labeling
Annotators must delineate their subjects with utmost accuracy; otherwise, the model will deliver a lousy reading. Poor labeling varies from case to case and across annotation types, so it's crucial to provide your team with instructions from the beginning.
A bounding box with excessive empty space between edges or a polygon segmentation that excludes a portion of an object are two of the most frequent but problematic labeling errors. Having well-trained teammates can help prevent these mistakes.
Incomplete labeling
Poor execution can result in performance problems just as easily as skipping objects. Labelers often miss fine details or blurry ones in images, which makes model execution a big job. Labeling each object correctly is a key component of a successful review process.
Auditing Results
Building an effective machine learning model requires quality assurance and auditing of workflow. The Superb AI Suite has been specifically designed to include an auditing process. To learn more, view our Academy video directly below to get a step-by-step overview of creating an efficient QA and auditing process for your model development workflow.
Before diving into the nitty gritty, there are a few things you can check right away:
- That the object class is correct
- That every object is annotated
- That no parts of an object were left unlabeled
You can choose to "Approve" or "Reject" images at the top of the page. If there are issues, you may let your team know by using the "Issue" function. If this is the case, selecting "Reject" at the top of the menu is your best option. Rejecting or approving an image doesn't just signify that they are marked as such, but it also changes the status of the image in your status bar.
Once you submit an image, it will appear as "Submitted" on the status bar, and a picture that is rejected will appear as "In progress." Having these statuses improves the efficiency of labeling workflows, thus helping them run coherently. Additionally, accepting or rejecting an image helps clear reviewers' queues, allowing them to keep track of their progress.
Manual Review Statistics
Knowing your auditing structure's strengths and shortcomings in real-time helps your workforce understand its achievements and failures. Management tools embedded in your labeling software can assist your team in recognizing what to look for when defining your model's success, as well as your progress and assessment structure.
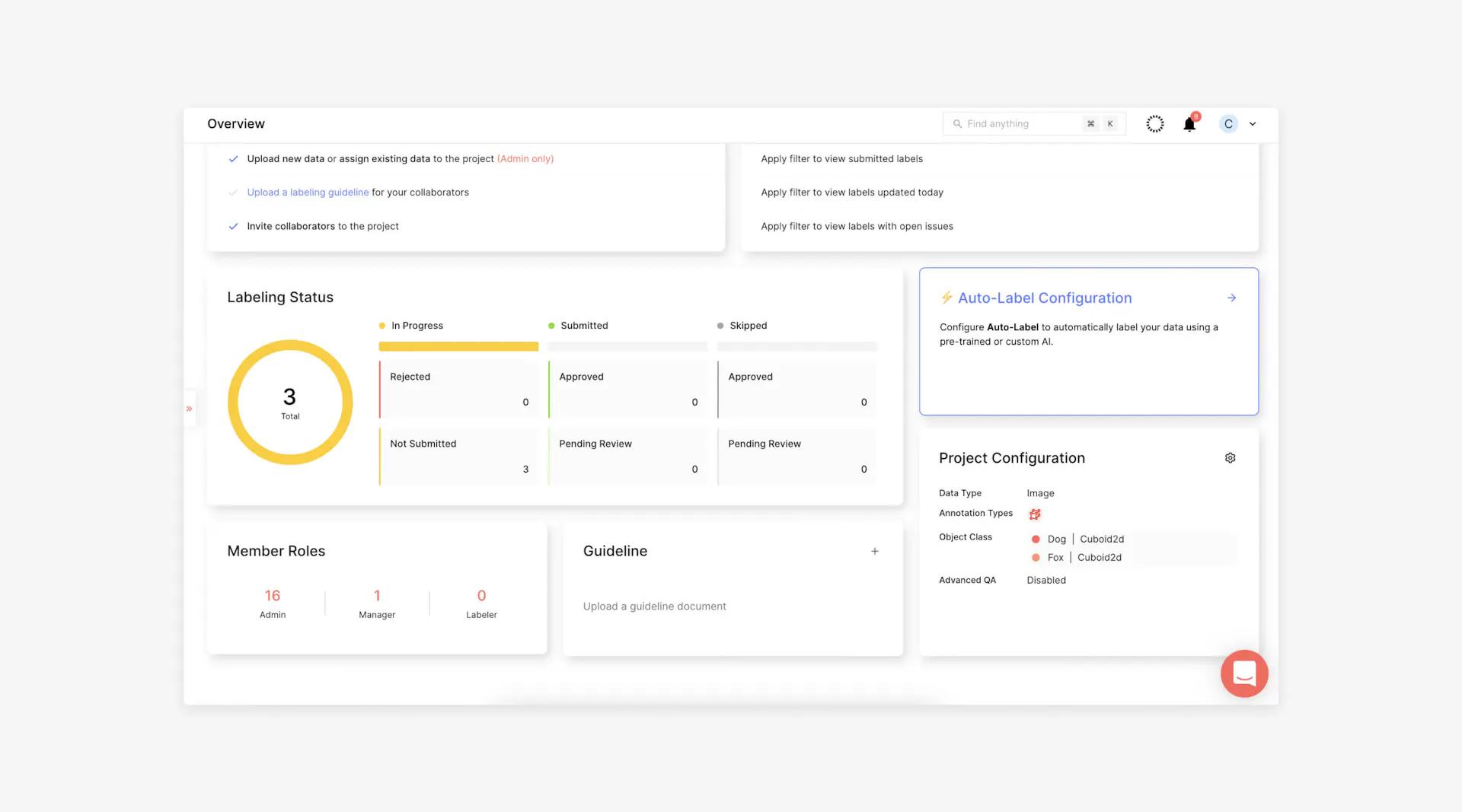
As a manager, knowing your workforce's progress and success in auditing by deadline not only informs you of their progress, but also keeps them on task. Attempting to keep track of progress and success with external tools or manual methods is disorganized and may impede your team. In contrast, the Superb AI Overview Menu provides a visual reference for managers and labelers alike.
Labeling Status
With Labeling Status, you can monitor your team's labeling progression and status in real time. You can see how many labels are in progress, with a visual of the number that have been rejected or not submitted, signified in red and yellow.
The number of labels that have been submitted is displayed in kelly green, showing how many have been approved, and a melon green representing those that have been submitted but are still under review.
You'll see how many labels have been skipped, with a darker gray representing approved labels and a lighter gray referring to those that have been skipped.
Member Roles
View the Member Roles menu to see how your team is structured. See how many admins, managers, and labelers are on your team. Soon, the Reviewer role will also be included, so you can have a better understanding of your auditing process.
Auditing Reference for Annotation
An auditing workflow can be aided by referencing annotation guidelines as a point of reference. These guidelines can be accessed from the Project Overview, but auditors also must be able to do so. Having them close at hand may help auditors during the reviewing process, enabling it to proceed more smoothly.
Useful Links
The purpose of this section is to remind auditors which filters can be used to identify certain labels. By separating your labels by status and only viewing those that have been submitted, viewed today, or reviewed for open issues, your team will be on track and stay true to the review process. Having this information readily available also makes it easier for your team to stay organized and have a thorough understanding of the status segments of the review process according to your needs.
Create Ground Truth Datasets
The Superb AI Suite is an extensive resource platform made up of tools that are important to understand how to navigate. Once you've mastered the fundamental principles, you'll be able to build ground truth datasets to prepare your model for an automated workflow.
Ground truth 101
What exactly is ground truth? Ground truth is a term for manually labeled datasets that the model considers to be true. When creating a ground truth dataset, you should consider several factors. You shouldn't just throw any data together for your model. Quality data and selection are crucial for iteration and for ground truth datasets in particular.
Know the basics
Though each labeling platform is different, there are some things that remain consistent in building a workable ground truth:
1. How many labels you need
To create a self-sufficient automated process, you should have an extensive ground truth dataset. This quantity can vary based on the size of your dataset and your platform's minimum specification. The Custom Auto-Label technology from Superb AI requires a minimum of 100 labels for training and usage, but It's commonly believed that your model will need more than that; at least 2,000 labels for every object category. Therefore, the quantity of images is not fixed based on your classification and image details.
To ensure your model runs as efficiently as possible, you should create a sufficient number of labels for each class. Underfitting your model may result from generating insufficient labels, which will negatively impact its functionality. Additionally, some labels must be set aside for hyperparameter optimization and prediction model performance.
It would be almost impossible to carry out these tasks if you didn't have enough data because you wouldn't be able to set a class score threshold or determine if annotations are necessary. This may only result in too many false positives and negatives, which will only become worse over time.
2. Diversify your dataset
In order for your model to function properly, you should ensure that your datasets contain a diverse set of examples without preference over others. The same principle applies when creating ground truth. This is the rationale behind requiring a set number of annotations per object class. Having an equal number of annotations per class minimizes any bias, resulting in better performance.
3. Defining your classes
There is no magic number when deciding on your class groupings; using fewer classes is always a better choice. Having too many object classes might slow down your model or confuse it. If you must create subcategories, do so, but avoid grouping rare objects or those that are difficult to categorize into the same category. This will help you avoid creating classes with too many objects, which 1) will be easier for labelers and 2) will prevent your model from tuning hyperparameters, resulting in lower performance.
4. Organizing your image sets
To build an agnostic ground truth dataset without biases, your images should represent all your classes as equally as possible. Furthermore, you should consider what it means to split your data into distinct subsets, i.e. your training, validation, and test sets. We discussed how to upload and assign names to our datasets in part one of this series. To accomplish this, break up your dataset into the following categories:
Training set:
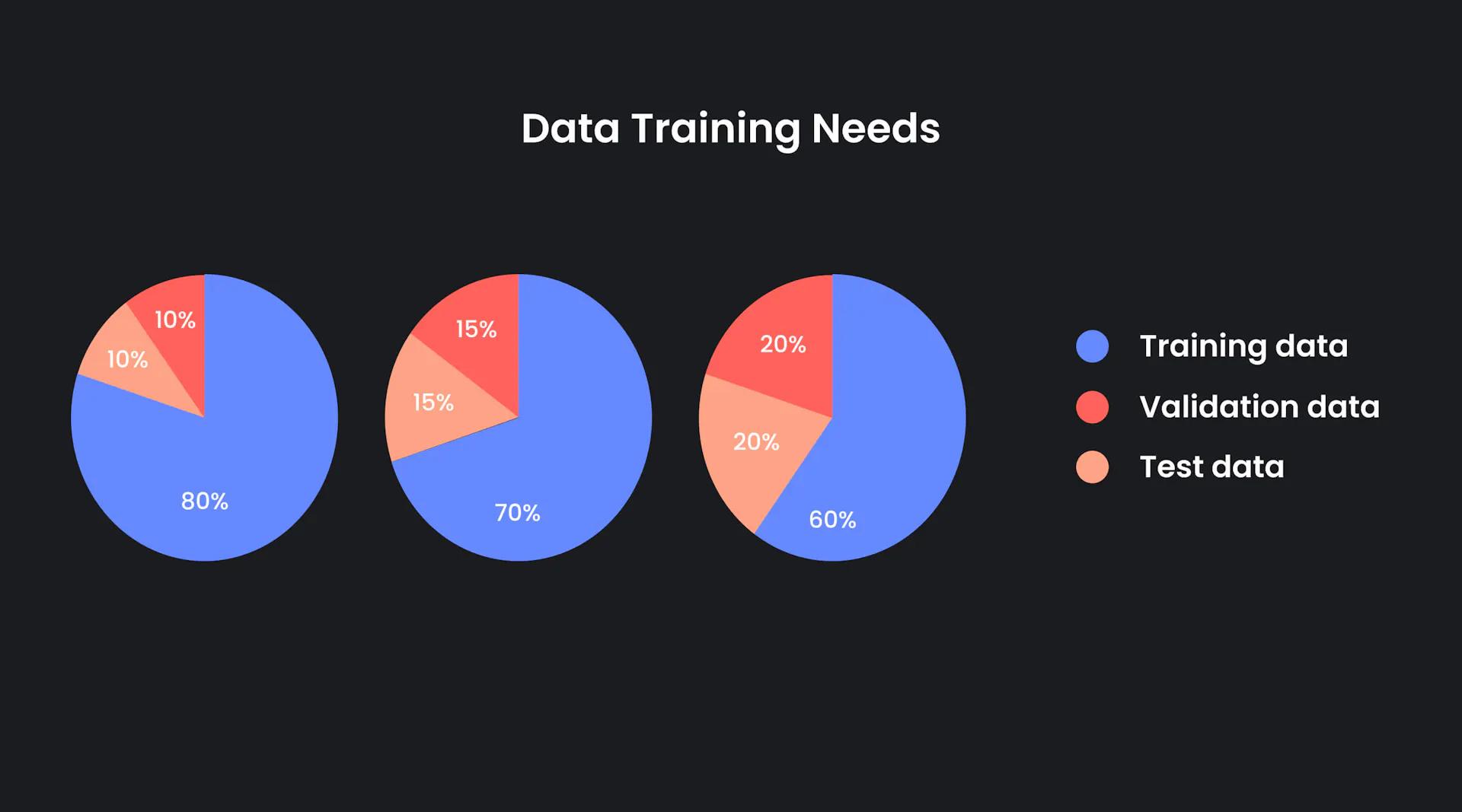
Your training set is used to train and test your data, so that it can learn various features and patterns through each iteration. Typically, machine learning practitioners allocate 80 percent of their data to training.
Validation set:
Your validation set acts as a gold standard in which to compare your data. Your test set is distinct from your training and validation sets in that it tests the performance of your model after training. It's a way to assess how well your model performs.
Tip: If you name your validation set __VALIDATION__, the system will be notified to use this dataset as a static validation set. This will be helpful later on.
Splitting your datasets
There are several things to take into account when splitting your dataset, as previously mentioned. Keeping your image classes evenly dispersed and having enough data to begin with are important, but there are other issues to consider as well.
Hyperparameters
Machine learning models with a robust number of hyperparameters often require a larger validation set than other models. Hyperparameters can include a large number of iterations, branches in a decision tree, or learning rate. Your validation set must be equipped to handle all of these factors, which is the reason for its larger size.
Number of iterations
A poorly calibrated model can substantially damage the performance of your model. If the accuracy of your model relies on its precision, you should reevaluate your data after each iteration. For example, if you are building a medical application to detect a large number of illnesses, a single incorrect diagnosis could negatively impact a patient's treatment plan.
Too little training data
Having insufficient training data can result in high variability. A random variable's value is compared to its expected value in machine learning; the difference is referred to as variability. Having too much variability between training sets makes it difficult for your algorithm to correctly estimate model outcomes.
Not enough testing data
Similarly to training data, not having enough testing data can impact your model performance metrics by showing high levels of variance.
Ultimately, there is no correct answer for how to split your data, but below are a few common methods among machine learning practitioners.
Sampling Methods
Dividing your data into validation, training, and test sets requires strategy to ensure that each set is properly diversified. Machine learning practitioners often follow these methods:
Random sampling
With this method, data is mixed together like you would shuffle a deck of cards. Based on your team's preferences, images are then divided into test, validation, and training sets.
Though effective in its unbiased selection process, random sampling has its drawbacks. If your data lacks balance in its object classes, it’s easy for your datasets to lean heavily toward one class over another. This can divide your training and validation sets unevenly and negatively affect your model’s performance.
Stratified sampling
Rather than choosing data at random, stratified sampling allows you to choose your data allocation by class, thereby preventing an imbalanced structure.
With random sampling, the likelihood of an imbalanced data distribution is quite high, but we could dictate this process much more easily with stratified sampling, which allows for additional parameters. These parameters can determine what class percentage is allocated for a certain dataset, reducing bias.
Cross-validation
Another popular, though more involved method of data sampling and distribution is through cross-validation. In this approach, your data is equally divided into subsets and evaluated a set number of times (K) on various samples.
Cross validation allows for your data to be used for both testing and validation, in as many combinations as your data subsets allow. For example, let’s take a 4-class dataset composed of 2,000 images, with an equal and separate distribution of each class. With cross validation, we could sub-divide the data into 5 equal parts, each with 400 images. Then, we could train 4 subsets and validate with the remaining data. Each iteration would contain a different combination of datasets as a way to reduce bias. One thing to keep in mind, however, is how you split your data, as distribution may become unequal.
Splitting Your Data in the Superb AI Suite
Once you’ve added your datasets into the Suite with evenly dispersed classes, it’s time to implement what we know about data allocation and apply it to our project. To begin, navigate to your Labels page and do the following:
1. At the top left-hand side of the page you have the option to use filters, which allow you to isolate certain labels based on various data. Click where it says “Filter by” and notice that there are several options to choose from. Scroll through and click “Dataset.”
2. In the search field, type in the name of your training dataset.
3. Use the check option to select them all.
4. Next, select the “Edit Tags” option in the right-hand side of the screen. Here, you can type in the name of your tag, which we recommend be clearly chosen to reflect each grouping. So for this instance, it would be wise to name your dataset “train” or “training”
5. Repeat this process with your validation and test sets.
6. Assign your data to your team members and begin labeling. For more on this, refer back to Part 1.
Export Your Data
Now that your data is labeled, it can be exported as part of your initial ground truth dataset and later, your custom auto-label. It’s easy to do with just a couple of buttons.
1. Populate your tagged training and validation sets.
2. Select the box at the top left-hand corner as well as the option to choose all of your populated images.
3. Select “Export” on the top, right-hand side of the page and let the Suite do the rest.
To see your data exports, navigate to the exports tab on the left-hand menu. View your export progress and history, and later, create your Custom Auto-Label designed specifically for your use case.
What’s Next
Setting up a project properly, using best practices for labeling, and organizing images are the keys to successful and efficient project execution. Next, we will train an adaptable model on ground truth, improve its performance, and optimize automation for time, accuracy, and cost savings. Stay tuned for Part 4 of this series.
Related Posts

Insight
How to Restart an AI Project That Stalled for Lack of Data—with Just 10 Images

Hyun Kim
Co-Founder & CEO | 7 min read

Insight
Three Years of the Few-Shot Object Detection Challenge: Mapping the Global Vision AI Landscape
Hyun Kim
Co-Founder & CEO | 7 min read

Insight
⑪ Germany's Physical AI Moment: Siemens, BMW, and the Robot Unicorn Counteroffensive
Hyun Kim
Co-Founder & CEO | 15 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.