Insight
How to Leverage Computer Vision Data Labeling Through Embeddings

2023/05/03 | 5 min read
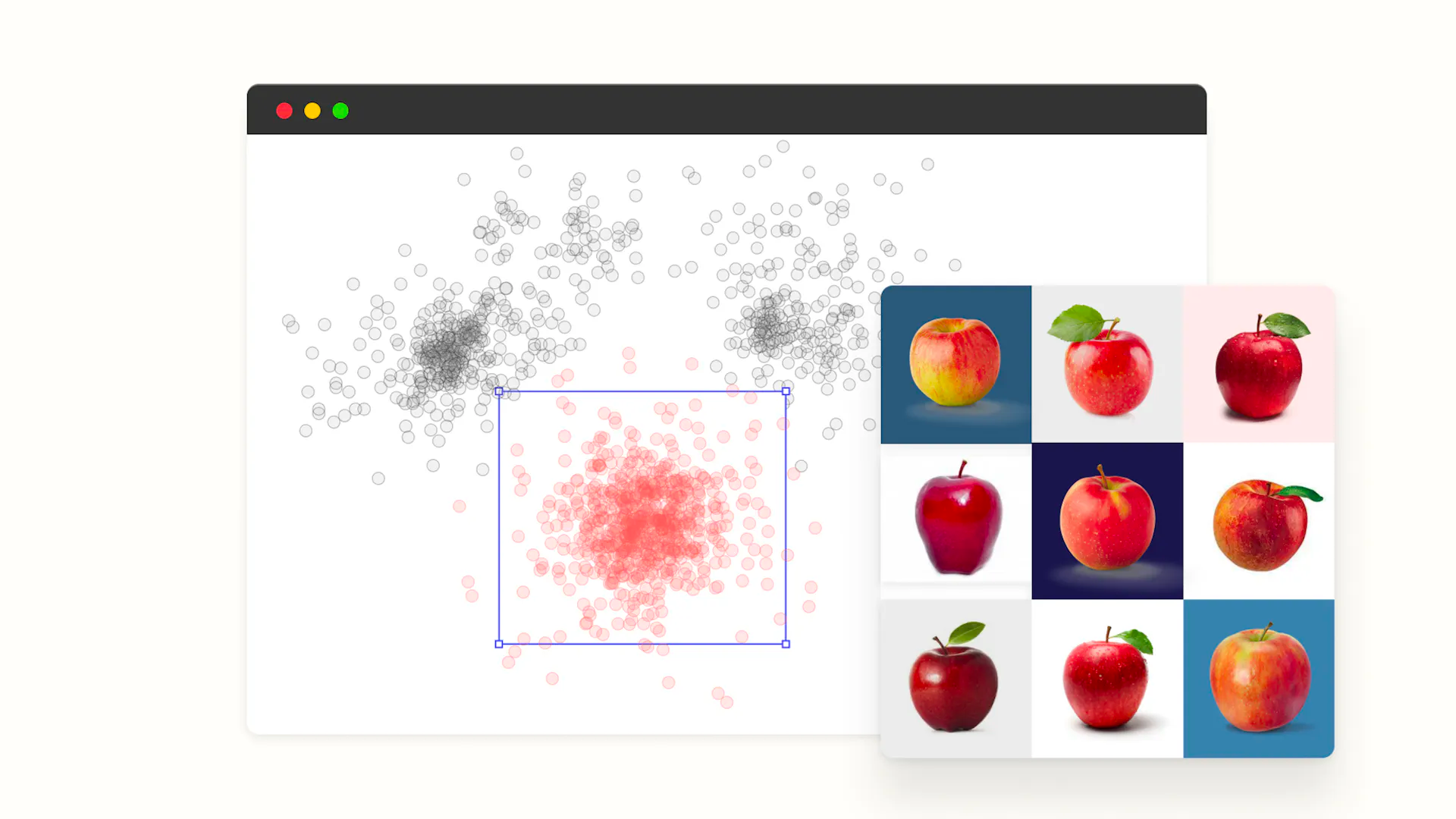
Embeddings are a powerful technique for converting raw data into compact, informative representations or vectors that can be easily processed and compared by machine learning algorithms. They play a crucial role in data labeling for computer vision applications, as they enable AI to understand and compare visual similarities between images.
This capability paves the way for image clustering through embeddings, which allows machine learning development teams to easily identify the most important data to label for their specific model's application, saving time and resources.
In this guide, we'll define embeddings, how to employ them in the data labeling workflow through image visualization or clustering, and novel methods for identifying high-value data through embedding generation.
Furthermore, we'll explore strategies for selecting the most representative samples for training and validation purposes while identifying mislabeled instances in datasets and potential edge cases. This method ultimately streamlines the data curation process, helping machine learning teams build more effective models with accurate and well-curated datasets.
We Will Cover:
- The basics of embeddings
- The challenges of conventional data labeling
- Revealing the untapped potential of querying
- Leveraging embeddings to streamline curation
The Basics of Embeddings
By harnessing the power of embeddings, machine learning development teams can improve the efficiency of their data labeling process, focusing on the most important and relevant data for their models. This, in turn, leads to the creation of more robust, accurate, and reliable computer vision applications, significantly reducing manual curation work and enabling teams to allocate resources more effectively.
For one, embeddings are essential for computer vision data labeling, as they help transform complex, high-dimensional data into lower-dimensional vectors while preserving the most important information.
Creating embeddings simplifies data labeling for computer vision model development, allowing teams to focus on the most relevant features, easily identify patterns or relationships within the data, and significantly reduce the computational complexity of their models.
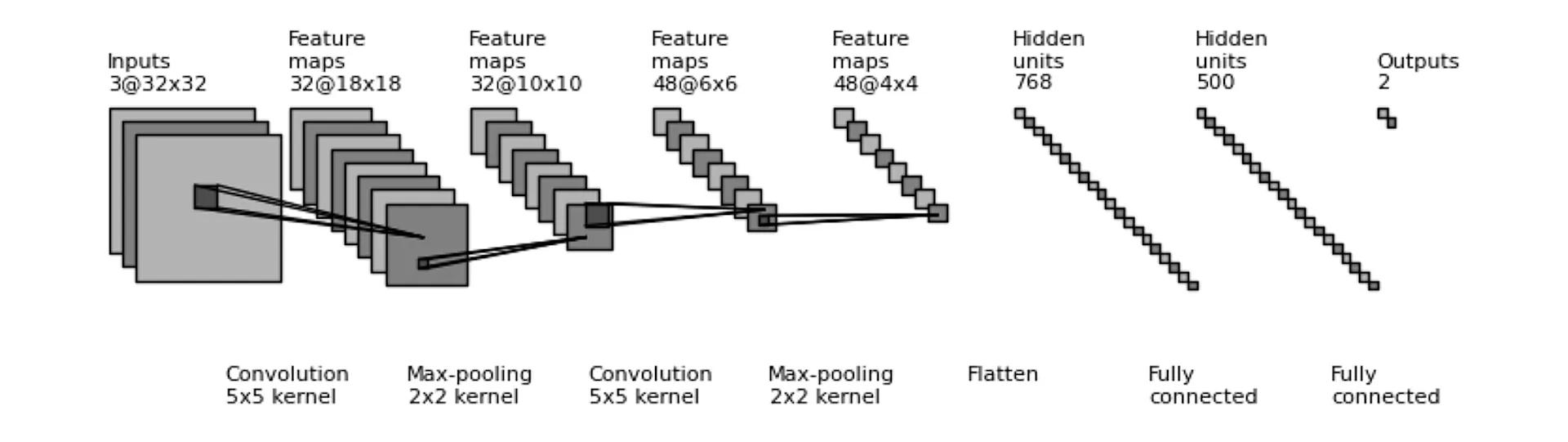
Diagram of a simple Convolutional Neural Network (CNN).
The Challenges of Conventional Data Labeling
When developing computer vision models for domain-specific applications, collecting and labeling high-quality, diverse, and relevant datasets is crucial. However, conventional data curation methods present various challenges for developers, making it difficult to effectively identify and label the most pertinent data for their models. Some of these difficulties include:
1. Manual labeling: Conventional data curation methods often rely on manual labeling, which is time-consuming, labor-intensive, and prone to human errors. This can lead to inconsistencies in the labeled data and hinder the model's performance.
2. Lack of domain expertise: In many cases, labeling data requires domain-specific knowledge, which can be hard to find. Labelers without proper expertise might struggle to provide accurate annotations, ultimately impacting the model's performance.
3. Data imbalance: Curating a balanced dataset that represents all relevant classes or scenarios can be challenging. Over-representation or under-representation of certain classes may lead to biased models that perform poorly in real-world applications.
4. Variability and complexity: Diverse and complex data, such as variations in lighting, pose, and occlusion, can make it difficult for model developers to identify and label the most relevant data points. This increases the time and effort required to create a reliable dataset.
5. Scalability: As the need for larger datasets increases to improve model performance, conventional data curation methods become increasingly inefficient. This poses a significant challenge for developers, as they must find ways to scale up their data curation efforts while maintaining accuracy and quality.
6. Data privacy: Ensuring data privacy is essential, particularly when working with sensitive or personally identifiable information. Conventional data curation methods may require sharing raw data with labelers, increasing the risk of data breaches or misuse.
7. Cost: The financial burden associated with conventional data curation methods can be substantial. Developers must account for the cost of labor, infrastructure, and potential quality control measures, which can limit the resources available for other aspects of model development.
Making the Most of Queries
Querying is an essential aspect of data visualization through embeddings, as it enables users to explore high-dimensional datasets by filtering and extracting relevant information.
By using querying techniques, analysts can efficiently navigate these reduced spaces, identifying patterns, trends, and outliers that would otherwise be difficult to discern in these high-dimensional datasets.
Facilitating Multidimensionality
One major advantage of querying is how it can facilitate the interactive exploration of multidimensional data. Users can formulate queries based on specific attributes or criteria, such as the range of values, similarity to a reference point, or the relationship between different variables.
This targeted approach allows users to focus on specific areas of interest, enhancing their understanding of the underlying data structure and aiding in the identification of relevant insights. Moreover, as the queries are refined, the visualization can be updated in real-time, providing immediate feedback and fostering an iterative, dynamic analysis process.
Insights Through Data Visualization
In addition to enhancing the exploration process, querying also supports the effective communication of insights derived from data visualization through embeddings. By allowing users to create custom views and comparisons, querying makes it easier to demonstrate the impact of various factors on the data, facilitating the interpretation and explanation of complex relationships.
Furthermore, sharing and reproducing these custom views ensures that insights can be effectively communicated across teams and stakeholders, leading to more informed decision-making and better alignment of organizational goals. Ultimately, querying plays a critical role in unlocking the full potential of data visualization through embeddings, empowering users to easily explore, interpret, and communicate complex data.
Streamlining Data Curation with Embeddings
Embeddings can play a crucial role in addressing the challenges associated with identifying and labeling the most pertinent data for domain-specific computer vision models. By using embeddings, developers can streamline the data curation process, effectively manage edge cases, reveal mislabels in datasets, and address common issues such as manual labeling, domain expertise, data imbalance, and more.
Edge Case Identification
Embeddings can help in the identification of edge cases by generating compact representations of images that capture their underlying structure and semantics. By visualizing and clustering these embeddings, developers can spot and isolate unusual or underrepresented data points that may correspond to rare events, boundary conditions, or potential mislabels. This enables the creation of more robust models that can handle a wider range of scenarios.
Revealing Mislabels in Datasets
can severely impact computer vision models' performance. Embeddings allow developers to identify potential mislabels by comparing images' similarity and corresponding labels. Outliers in this space can indicate inconsistencies in the labeling process, prompting further investigation and
Image Segmentation for Enhanced Embeddings
Image segmentation plays a critical role in computer vision tasks, as it involves partitioning an image into distinct segments or regions that share similar attributes or properties. By incorporating image segmentation into the data visualization process, developers can gain more meaningful insights into the data, improve embeddings, and ultimately enhance model performance.
Improving Semantic Understanding with Segmentation
Image segmentation can provide valuable context and semantic understanding when combined with embeddings. By partitioning images into semantically coherent regions, developers can extract region-specific embeddings that capture localized features and relationships.
Visualizing these region-specific embeddings allows for a more detailed understanding of the underlying structure and semantics of the data, leading to more accurate and informed decisions during the data curation process.
Refining Embeddings with Segmentation
Integrating segmentation information into embeddings can lead to more discriminative and informative representations. By capturing local features and relationships within segmented regions, these refined embeddings can better represent subtle differences between images that may not be evident in global embeddings.
As a result, developers can more effectively identify edge cases, mislabels, and high-impact data points for labeling, leading to improved model performance.
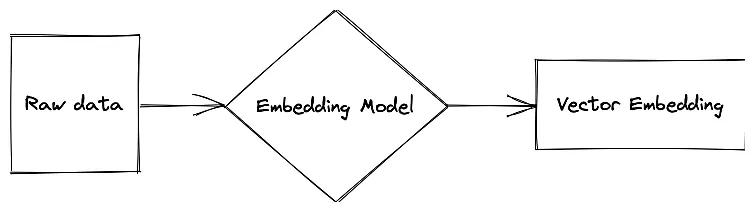
A sequence diagram depicting the use of raw data to create an embedding model which produces vector embeddings.
Overcoming Common Issues
The process of curating and labeling data for computer vision tasks often presents numerous challenges, such as manual labeling efforts, domain expertise requirements, data representation imbalances, and handling complex datasets.
In this section, we explore how leveraging embeddings can provide effective solutions to these common issues, while also addressing concerns related to scalability, data privacy, and cost-efficiency. By overcoming these obstacles, developers can optimize their data curation process and ultimately improve the performance of their computer vision models.
- Reducing manual labeling efforts: By utilizing embeddings, developers can automate the process of grouping similar images, thereby reducing the time and effort required for manual labeling. This also leads to more consistent labeling, which can enhance model performance.
- Addressing domain expertise challenges: Embeddings can help bridge the gap between domain experts and labelers by providing visualizations and metrics that allow for easier identification of relevant data points, even those without extensive domain-specific knowledge.
- Balancing data representation: Embeddings can be used to analyze the distribution of data points across various classes, enabling developers to identify and address data imbalances. This can result in a more balanced and representative dataset for training models.
- Handling variability and complexity: Embeddings capture images' high-level features and semantics, making it easier for developers to identify and label relevant data points amidst diverse and complex data.
Superb Curate, a cutting-edge product designed to help developers overcome the common challenges associated with data curation for computer vision tasks; provides image clustering and 2D cluster visualization features that enable users to take a more hands-on approach in evaluating data distribution and embedding clustering results.
The 2D cluster visualization feature also provides users with a comprehensive view of their data distribution and clustering results. Allowing users to easily spot potential edge cases, mislabeling, and data imbalances that can be considered unpredictable variances in a dataset.
- Scaling data curation: Embeddings allow for the efficient handling of large datasets by reducing the dimensionality of the data, facilitating faster processing and analysis.
- Protecting data privacy: By working with embeddings rather than raw images, developers can minimize the exposure of sensitive or personally identifiable information, reducing the risk of data breaches or misuse.
- Reducing costs: Leveraging embeddings can streamline the data curation process, resulting in lower labor and infrastructure costs, and freeing up resources for other aspects of model development.
The Data That Matters Most to Performance
Utilizing embeddings through a specialized tool like Superb AI's Auto-Curate, machine learning teams can reap the benefits of evenly distributed clustering, minimal redundancy, edge case identification, and reduced manual workloads for annotating training data.
More importantly, embeddings allow teams to pinpoint the most relevant and informative labels, which are vital for training high-performing computer vision or machine learning models. Focusing on the most significant labels ensures that the models capture the data's essential patterns, relationships, and features.
This, in turn, leads to enhanced performance and increased effectiveness when deployed in real-world scenarios. embeddings greatly improve the efficiency and usability of machine learning models by making massive amounts of training data manageable.
By enabling the identification of the most important labels, embeddings contribute significantly to the performance of computer vision and machine learning models in real-world applications, ensuring that these models achieve their full potential.
Improving Data Workflows Through Automation
The next generation of AI-based annotation tools have arrived, and Superb AI’s Auto-Edit is here to revolutionize the way labeling teams handle the most complex and irregular object forms. In combination with uncertainty estimation and active learning methodologies, any ML organization can significantly increase image and video annotation throughput and quality, resulting in faster AI project deployment and improved performance.
Transforming the Meaning of Manual Labeling
Auto-Edit is a game-changing AI-assisted tool that automates polygon segmentation, one of the most laborious, time-consuming, and precision-oriented tasks in data labeling. By integrating Auto-Edit into your annotation process, you can:
- Annotate and edit complex polygons 10-20x faster.
- Increase labeling speed and throughput with fewer clicks and less fatigue.
- More consistently and precisely annotate complex or irregular objects.
- Make real-time corrections with a single click to reduce human error and QA time.
Auto-Edit empower your team to work smarter, annotate faster, and deliver value from AI investments more rapidly.
Enhanced Automation with Uncertainty Estimation and Active Learning
Superb AI’s core active learning technology, Uncertainty Estimation, allows your ML team to focus on refining the model where it matters most. By assessing the model’s uncertainty levels and employing entropy-based querying, Uncertainty Estimation selects instances within the training set that require further attention.
This hybrid method of Monte Carlo and uncertainty distribution modeling methods ensures that your auto-label AI accurately annotates data, ultimately streamlining the labeling process and delivering trustworthy results.
Active learning models, on the other hand, only require a small amount of trained data to operate. ML teams label a small sample of data, and the model identifies uncertainties when labeling raw data. Humans intervene to correct errors and retain the model, resulting in dramatically improved performance over time.
The combination of Auto-Edit, Uncertainty Estimation, and Active Learning tools significantly reduces labor-intensive tasks and workforce requirements, while maximizing project velocity and scaling
Related Posts

Insight
How to Restart an AI Project That Stalled for Lack of Data—with Just 10 Images

Hyun Kim
Co-Founder & CEO | 7 min read

Insight
Three Years of the Few-Shot Object Detection Challenge: Mapping the Global Vision AI Landscape
Hyun Kim
Co-Founder & CEO | 7 min read

Insight
⑪ Germany's Physical AI Moment: Siemens, BMW, and the Robot Unicorn Counteroffensive
Hyun Kim
Co-Founder & CEO | 15 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.