Insight
The Best Data Annotation and Labeling Metrics to Track: How to Ensure Project Success

Abimbola Oshodi
Project Manager, Data Services | 2022/08/15 | 5 min read

When evaluating what makes a machine learning model effective, it all comes down to performance and quality metrics. These evaluating factors are essential for AI practitioners to determine whether the model will function as intended for its application and specific industry use. In essence, monitoring and assessing performance during development directly leads to a successful product.
A capable model is a model that is prepared to predict and organically respond to a variety of diverse scenarios once deployed in the field. This level of reliability and responsiveness would be impossible without quality training data. To attain higher quality data, there are a unique set of metrics dedicated to that earlier stage of any AI development pipeline.
The data management stage is a key and initial step that is often undervalued and overlooked in favor of model iterations during training and evaluation, long after data has been fed into a model. Data that is more often than not faulty and leads to significantly lengthening the ML modeling cycle and, ultimately, a subpar product. It wouldn’t be ambitious to say then that AI algorithms and applications are only as competent as the data that powers them.
It’s a well-known fact that data management can be tricky for any ML team to navigate. With an estimated 80 percent of model development time dedicated to handling and preparing data, it’s no surprise that it’s not the most popular aspect for practitioners to focus on.
However, the work that is put into the heart of the data processing workflow, annotation, or labeling, will translate to immense value through optimal performance and a final product that requires less troubleshooting and maintenance following deployment.
In this article, you’ll learn to identify the particular metrics to measure the proficiency of data labeling workflows, how to properly interpret them to maximize model efficiency, and last but not least, or any less important for that matter, tracking those metrics to continually adapt and optimize labeling processes to meet specific project and development needs.
The Labeling Metrics That Matter Most
There are certain initiatives typically associated with the standard data labeling process. After a varying amount of data has been collected, which requires annotation to organize and separate datasets according to what is relevant and usable information versus what is not; it becomes labeled data, which is then considered properly structured and prepared to help train and deploy models.
The initiatives themselves seem simple enough; gathering, organizing, and annotating data before it can be used, but following through on those initiatives is harder than it seems. Very likely because the average ML team handles data labeling efforts in a costly and inefficient manner. Unfortunately, many AI software developers limit themselves to a handful of conventional and carelessly implemented options.
Those methods are handling data processing needs either in-house, with dedicated data labeling teams or individuals assigned to labeling tasks, contractors that are often freelance and temporary, or through crowdsourcing; utilizing a third-party service provider to employ a larger team of designated workers to handle annotation tasks.
Regardless of which method practitioners decide on, it’s necessary to set and follow guidelines and abide by certain standards to avoid producing flawed and low-quality datasets. With that understanding in mind, the following criteria are recommended for ensuring data is processed to emphasize process efficiency: the quantity or size of the datasets, the frequency of label or annotation errors, minimizing noise, data filtration, time management, and the ability to filter down to the most accurate subsets of data.
In order to effectively measure and track the recommended criteria, a reputable data preparation platform will go a long way to simplifying data management, regardless of the individual requirements of a specific project, the size and number of datasets that need to be processed, or the skill level of the team that will be managing the data. Superb AI’s Platform provides just that, through a comprehensive and personalized environment for any ML and CV project dataflows.
The Impact of Measured Data
There’s a common assumption and view by the ML community that the more and bigger the dataset, the better. Real case model examples suggest otherwise. It’s about the suitability of the data for what it’s intended to train the model to do or how likely it is to help produce that predicted outcome or result. Plainly said, data that was made for its job or the particular project it’s meant for.
To attain such ideal data, there are, understandably, some obstacles labelers have to overcome. Depending on the use case and nature of the ML or CV project, different tools will be more fitting than others to tailor and prime datasets to be training-ready, such as bounding boxes, polygon segmentation, rotating boxes, polylines, key points and more.
Utilizing these tools interchangeably depending on the type of data and their purpose will enable labeling teams to more efficiently and confidently annotate, therefore producing higher and more accurate data for the ML/CV program’s needs and lead to the desired outcome of a successful model.
There are a lot of moving pieces in a well-oiled and productive data flow, like a steady assembly line, a cohesive series of units that come together and apart according to a labeling task’s specifics or directives. A blend of people and the machine tooling and features that collaborate to execute a new top-tier standard of how data is viewed and handled in the AI industry.
Having the capability to properly coordinate individual or several ML projects from a labeling platform’s bird’s eye view is invaluable to generating data that’s beyond the minimal requirement of being “good enough” for training algorithms, but the stable foundation that’s the difference between a model’s shaky and error-ridden deployment or an all-clear and turbulent-free takeoff.
Using a platform enables ML leads to break down labeling tasks into sizably manageable chunks and disburse assignments in a more efficient and cleanly coordinated way. Assignments that are then more easily monitored and refined. By doing so, practitioners can get an accurate picture of what is and isn’t working through the progressive process that is data labeling. Adapting the pipeline to the naturally dynamic needs of AI systems.

Using Analytics to Optimize Data Management
The best case result for any deployed AI application or system is to perform its function as programmed, as smoothly as possible. That isn’t necessarily enough, though, active models, like any technology, require consistent updating and retraining to maintain performance expectations.
Beyond that, as the reach and influence of AI as a technology extends to new industries and increasingly relied on by current adopters, more applications will take on critical roles that impact society in more tangible and visual ways, for instance, the use of AI in medical and healthcare systems; trusted to make decisions related to patient wellbeing and actual livelihood. Producing better quality data, that fuels the ML models of tomorrow, the ones that are capable of surpassing their predecessors.
What a model views and analyzes on a day-to-day basis can vary. That’s why it’s important to track and measure relevant metrics during the data preparation and training processes to understand where improvements can be made, identify data training needs or gaps, and ensure the model has a balanced and diverse pool of data to draw predictions and outcomes from, in order to be prepared to respond to any situation they face in a real-world setting.
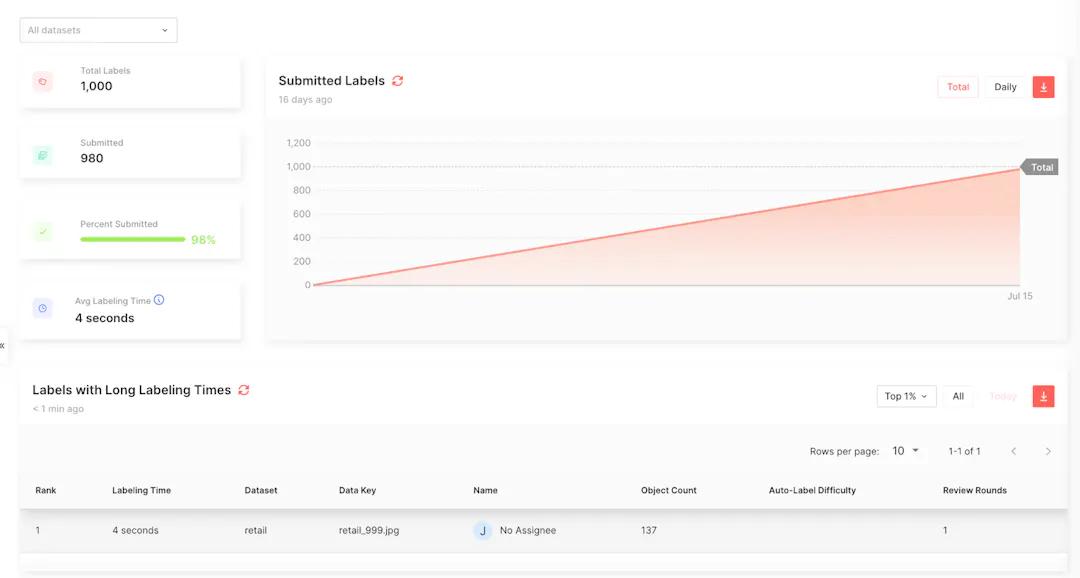
There should always be some level of human involvement when processing and testing data, specifically to provide insight on ground truth and taking corrective measures when necessary. Using Superb AI’s analytics dashboard will equip any ML team lead with the information they need to take these corrective actions.
Tracking metrics such as the number of total labels, a breakdown of the data types and categories, user reports on individual labeler performance, and the ability to delve in deeper into specific dataset groupings to the most valuable and pertinent data to a project.
Any successful data labeling team should have a clear understanding of what they’re trying to achieve and how they’re measuring that achievement. Through that knowledge, annotators are more likely to meet labeling quality expectations, receive feedback that applies to their assignments and is easier to follow through on, and overall, empower them to satisfy and possibly exceed data processing goals.
Related Posts

Insight
How to Restart an AI Project That Stalled for Lack of Data—with Just 10 Images

Hyun Kim
Co-Founder & CEO | 7 min read

Insight
Three Years of the Few-Shot Object Detection Challenge: Mapping the Global Vision AI Landscape
Hyun Kim
Co-Founder & CEO | 7 min read

Insight
⑪ Germany's Physical AI Moment: Siemens, BMW, and the Robot Unicorn Counteroffensive
Hyun Kim
Co-Founder & CEO | 15 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.