Insight
Why Security is Important When Considering a Labeling Platform, And What to Look For

Tyler McKean
Head of Customer Success | 2022/08/09 | 7 min read

In today’s world, cybersecurity is one of the most important aspects of everyday life. As people, we place our trust in small businesses with our phone numbers, social media applications with our email, and banking institutions with our finances. The second a company experiences a breach, and your data is released to the masses is the moment you, as a consumer, lose trust.
In machine learning and computer vision, this notion is relatively identical. Each piece of your computer vision data holds invaluable information pertinent to your project. And each project is made up of thousands of pieces of information, all of which are necessary to successfully implement a model.
Just as HIPAA is the universal code of privacy in the medical field, machine learning specialists must place confidentiality above all else to solidify and garner the trust of their customers and the general public. That said, data protection must start at the beginning stages, with its labels. So how does a team of machine learning experts and tech enthusiasts choose their data labeling software knowing they’ll be protected? While there’s no guarantee that a software program will be immune to data breaches, there are some things every team can look out for:
Industry Standards and Compliance
For companies handling extensive pieces of data for labeling, choosing an annotation software that is up-to-date and compliant with industry security standards should be top of mind. There are several certifications and audits that a company can receive to ensure their security practices are in line with customer needs. In doing so, the company not only gains the trust of their customers, but they also increase their earnings. Customers who value the safety of their data are much more likely to choose a program with the necessary security audits and/or certifications.
SOC 2 Type 2
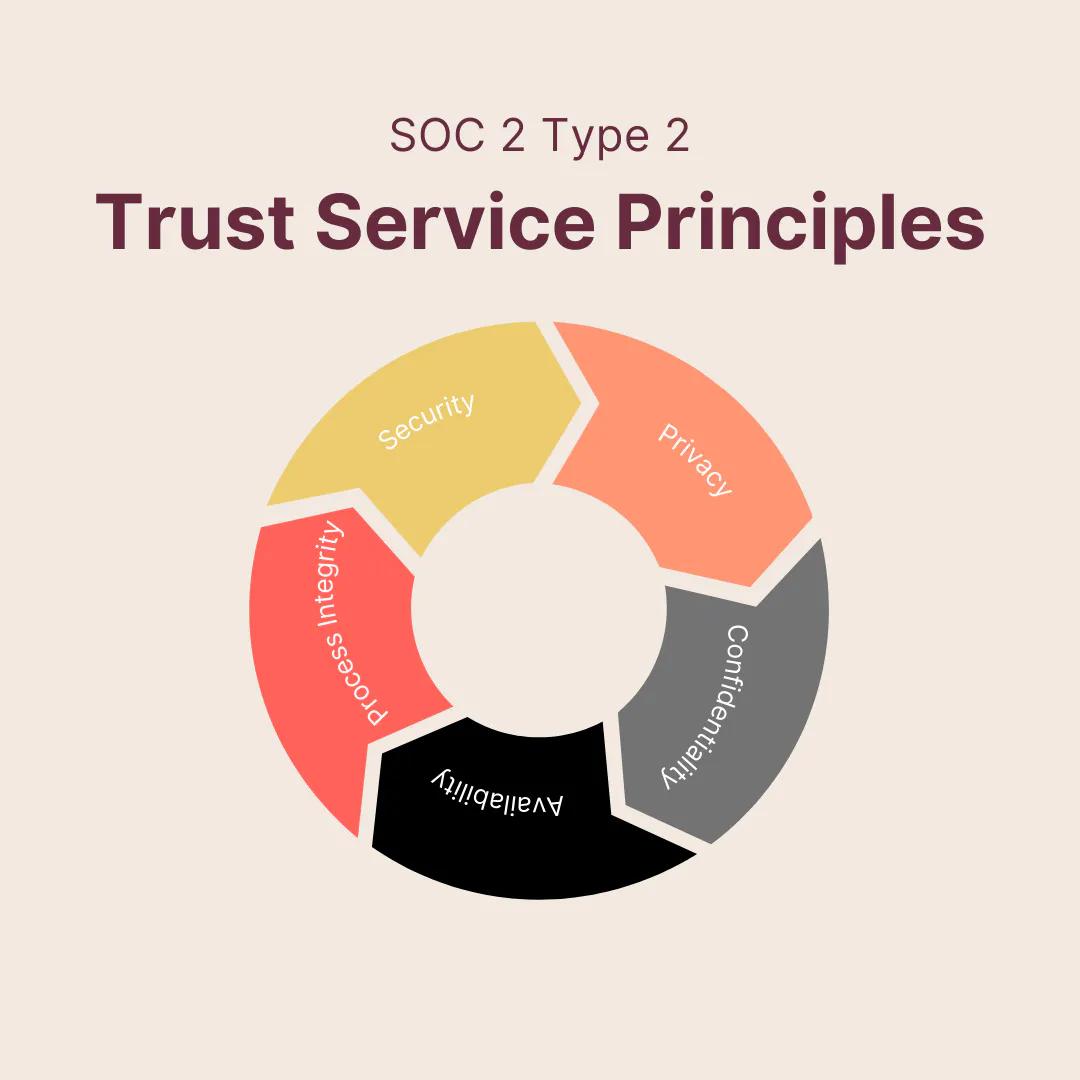
Data labeling software relies heavily on cloud integrations to host thousands of images, texts, and video files. Without it, the program would not be able to support many labeling initiatives and would crash by default. A Service Organization Control, or SOC, audit specializes in cloud-based software. Each assessment examines how a company fulfills the expectations of the five trust service principles, or TSPs. These principles include security, privacy, confidentiality, availability, and processing integrity. As part of the audit, the software organization provides an independent auditor with documentation and access to the controls. In turn, they receive a detailed assessment of how well their security stacks up against the outlined standards.
SOC 2 Type 2 is a highly trusted and well-regarded auditing process that sets the standards across the cybersecurity industry. A data labeling software compliant with SOC 2 Type 2 is one that takes their customers’ information seriously and goes through extensive testing to ensure the data remains secure.
ISO/IEC 27001

Outside of SOC 2, companies largely trust ISO/IEC 27001, an international standard for managing information security. Unlike SOC 2, the ISO offers an official certification to companies handling information security. In addition, ISO/IEC mandates that companies using its certification process implement an Informational Security Management System, which concentrates on risk management. The purpose is to outline the processes required to alleviate risk and address security-based concerns.
Essential Features
Having the certifications and audits to back up a company’s security claims is an obvious requirement in gaining the trust of potential clients, but it isn’t the end-all-be-all. Data labeling companies also need to build safety features into their software to prevent a breach before it can happen. Since hackers are highly sophisticated and attuned to the security measures taken by major corporations, it’s paramount to always be two steps ahead of them.
Login Procedures
It sounds obvious, but the steps a user must take to access a platform determine how easy it is for outside threats to do the same. Since the internet’s inception, password protection has been the standard blockade for privacy protection. But tech has advanced faster than the human race, and so too have our strategies for protecting ourselves and our information.
When it comes to data labeling software, pay attention to the required steps for making an account. Passwords are standard, but is there a character requirement? Are you mandated to change it every month or few months? Enforced password standards automatically help users protect their data rather than relying on them to do all the heavy lifting.
In addition, companies practicing two-factor or multi-factor authentication for each user add a layer of security right from the get-go. Requiring, or allowing users to opt-in to 2fa or MFA, introduces an additional device outside of their platform, which will notify them right away if another person is attempting to access their data.
Encryption and Key Management

Data protection is at the forefront of everyone’s mind in 2022, and if it isn’t, it should be. Because data for computer vision handles so much information pertaining to even the tiniest essential detail for computer vision, it must be encrypted. For those unfamiliar, encryption is a security measure that applies a specific code to a piece of information. Only those with access to an encryption key are able to decipher its meaning. The data looks garbled and indistinguishable to an outsider, but to those with direct access, it appears perfectly normal. Using a key management system such as AWS KMS helps protect, create, and manage cryptographic keys.
Encryption is now standard across platforms and industries, and it’s the reason why many choose one application over another. WhatsApp, the highly popular messaging application, for example, markets itself as an encrypted messaging platform within the app itself. It’s one of the reasons millions choose to use it because they know that their messages are private. For computer vision practitioners, the principle is very much the same. For an outside party to gain access means that every piece of metadata within an image is exposed.
Role-Based Access Controls
Depending on the scope of a project, practitioners often want to restrict how much control team members have over data access and manipulation. In the everyday world, we see limited controls all the time. Google Docs offers different access controls that an owner can assign, such as editing, viewing, or suggesting. This prevents any unwanted changes to the document and keeps things in check organizationally.
Access restriction and permissions are essential in establishing a team’s roles and responsibilities in data labeling and other programs. It also keeps certain information private, even within a team. This is known as having role-based access controls. Furthermore, RBAC prevents unauthorized team members from working on the wrong task or accidentally overstepping on an area of a project assigned to someone else. Establishing a hierarchy of access controls prevents all of the aforementioned from happening and helps keep data safe, and teams organized.
Cloud Storage and Read Only Access

Data labeling and management programs are only as useful as their ability to host information and provide a backup plan in the event of a crash. As an ML engineer or practitioner, finding a platform offering safe and reliable cloud integration is crucial for a number of reasons. For one, it speeds up disaster recovery in the event of a crash. Data hosted on-site only will be as protected as its software, meaning that any threat or disaster will directly affect your data.
Choosing to store it within the cloud keeps it safe from whatever is causing your labeling software to crash. In addition, cloud storage companies have dedicated security forces to ensure data protection and are therefore always on high alert to outside threats. Data stored in the cloud is typically encrypted while at rest and in transit, so anyone not privy to that information is unable to decipher it. What’s more, data theft typically occurs at the hands of employees, so hosting your information in an encrypted cloud storage facility prevents this from the get-go.
Hosting your data in the cloud also boosts overall quality control. As part of cloud infrastructure, documents are stored together and in the same format. This is important because it prohibits multiple versions and formats to be made of the same file or document, which can lead to confusion and incorrect data. Coinciding with the quality control of your data are measures put into place to further prevent unwanted changes.
Implementing read only access is an easy, yet essential measure that can be taken to protect your data. For those unfamiliar with the concept, a read only file allows only certain team members to make changes while others can view or read it. Having these controls is a lot like placing your data in a cloud server, where version history and controls are well documented.
Quality Assurance and Vulnerability Testing
A crucial component in cybersecurity and data protection is instilling and enforcing safety measures through quality assurance and vulnerability testing. Dedicating full-time specialists to detect threats and breaches before they become a problem is the marker of good security. Any company that fails to emphasize this practice fails to ensure the safety of its customers and user base.
Whether in-house or outsourcing, software companies must take vulnerability testing and quality assurance very seriously. When considering a data labeling company, be sure to ask about testing measures, frequency, and standards. Without a well-armed security team, your data is susceptible to compromise.
Data Ownership
While cloud integration and off site storage remains crucial in keeping data protected, it’s also worth emphasizing the importance of data ownership. In today’s tech landscape, data sales has become a mainstream money-making strategy, and data labeling for machine learning is not immune. With many software and organizations, agreeing to use their tools also grants them permission to recycle and reuse data for future projects.
For machine learning practitioners, this poses an array of concerns regarding privacy–and it should. Working with proprietary information, especially in the medical field, is a huge part of building out computer vision projects. Releasing that data to the general public is not only short-sighted, but it’s also dangerous.
Background Checks
Just as ensuring the company handling your data has all of the appropriate certifications and guidelines, it’s also important to know the faces behind the corporation. Since data theft is a huge concern in this day and age, knowing the people handling your data should be a requirement. Before signing up for a data labeling platform, ask the question: “Has everyone working for you passed a background check?”
If the answer is no, then look elsewhere. You can never be too careful with the people you entrust with your data, as those who are well-equipped in data theft must know the ins and outs of security protocols. Additionally, make sure that all employees have undergone data security training , and not just once but periodically. Standards and protocols change all the time. Those working in data labeling and security should always be ahead of the next threat, and frequent training and assessments can help with that.
Next Steps
Now that you understand the importance of security, its many components, and what to look for, choosing the correct data labeling service should be a lot easier. Be sure to comb through a company’s certifications, how often they undergo security assessments, and the measures they take on a daily basis before choosing them as a service provider. Your data is the most valuable asset you have in your machine learning project; make sure others view it as such.
Related Posts

Insight
How to Restart an AI Project That Stalled for Lack of Data—with Just 10 Images

Hyun Kim
Co-Founder & CEO | 7 min read

Insight
Three Years of the Few-Shot Object Detection Challenge: Mapping the Global Vision AI Landscape
Hyun Kim
Co-Founder & CEO | 7 min read

Insight
⑪ Germany's Physical AI Moment: Siemens, BMW, and the Robot Unicorn Counteroffensive
Hyun Kim
Co-Founder & CEO | 15 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.