Insight
Interactive AI in the Field? Exploring Multi-Prompt Technology

Tyler McKean
Head of Customer Success | 2025/08/25 | 15 min read

[What’s VFM?] Interactive AI in the Field? Exploring the Multi-Prompt Technology
This is the second part of Superb AI’s “What’s Vision Foundation Model (VFM)?” series, explaining the concept of VFM. In Part 1, we discussed the potential for AI models to be deployed directly in real-world environments without additional training—thanks to “zero-shot learning” and the concept of “open-world” systems.
See here to read our blog on Superb AI's ZERO
In this second post, we’ll dive into multi-prompt technology—a breakthrough that transforms how users interact with AI models. Multi-prompting goes beyond text input by incorporating visual elements, enabling users to communicate their intent more precisely and intuitively with AI.
From Static Models to Prompt-Based Interactive Models
Traditional computer vision models were static—designed to perform specific tasks such as image classification, object detection, or segmentation using predefined inputs and outputs. They could only predict outcomes based on predefined classes and required full retraining or fine-tuning when new tasks or unseen classes were introduced.
However, with the rise of large-scale pre-trained models, this paradigm is shifting toward prompt-based interaction. Just as we give instructions to people in various ways, we can now instruct AI using different forms of prompts—text, images, clicks, sketches, and more—offering greater flexibility and usability. This evolution significantly expands the versatility and scalability of AI systems.
Types of Prompts and How They Work
Multi-prompting is a technique that allows users to input more than just text—enabling AI to receive instructions in multiple forms. The main prompt types and their functionalities are as follows:
- Text Prompt: The most common type, where natural language is used to instruct the model. For example: “Find the red car” or “Highlight the scratches in this image.” The model connects textual descriptions to visual concepts using knowledge learned from large-scale image-text pairs.
- Class Prompt: A subtype of text prompt used mainly for classification tasks. Users specify class names directly, guiding the model to choose from predefined categories—for instance, “Classify this image as either ‘dog’ or ‘cat.’”
- Visual Prompt: When text alone is insufficient, users can provide visual examples to aid the model’s understanding.
- Reference Image: An image containing the desired object or pattern is given to the model, with the instruction like “Find objects similar to this one.” The model extracts visual features from the reference and identifies similar elements in the target image.
- Bounding Box Prompt: A rectangular box is drawn around a specific object in the image. THe model is instructed, for example, “Segment the object inside this box.” The model focuses on pixel-level details within the box to perform segmentation or recognition.
- Point Prompt: A dot (click) is placed on a part of the object, e.g., “Segment the object that contains this point.” The model infers the most appropriate object boundary around the point.
- Sketch/Mask Prompt: Users draw freehand shapes or masks over the image, e.g., “Separate the object corresponding to this sketch” or “Find areas matching this pattern.” This is especially useful for irregular shapes or subtle visual cues.
These multi-prompt methods allow AI to interpret user intent more accurately and intuitively, significantly improving its applicability in complex real-world environments.
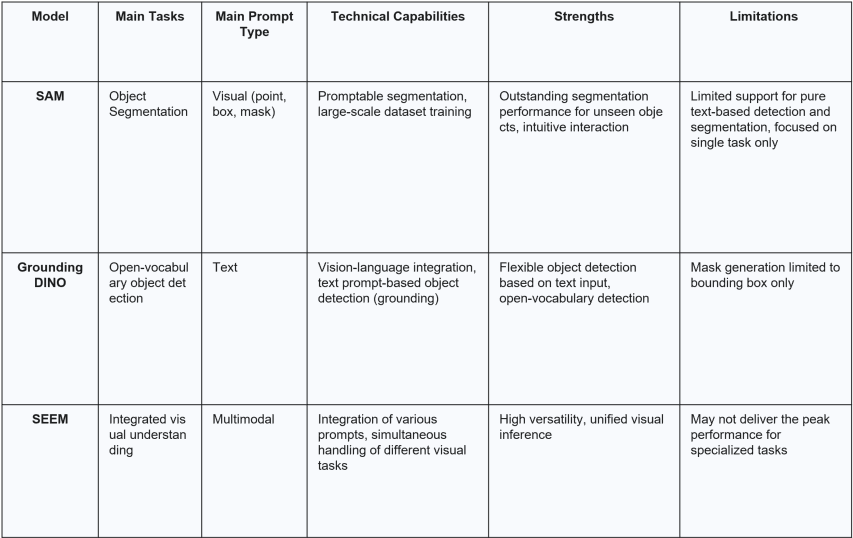
Technical Differences Between SAM, SEEM, and Grounding DINO
Several powerful vision models based on multi-prompt interaction have recently emerged. Here, we take a closer look at 3 representative technologies.
- SAM (Segment Anything Model)
- Concept: Developed by Meta AI, SAM is a “prompt-able image segmentation model” designed to segment any object within an image. It was trained on an extensive dataset of over 1.1 billion masks across 11 million images.
- How It Works: SAM specializes in object segmentation based on various types of visual prompts—such as text, points, boxes, or sketches/masks. It is powerful enough to generate precise object masks with just a few user clicks, as it focuses entirely on the segmentation task to maximize its performance as a foundation model.

- Technical Difference: SAM consists of an image encoder, a prompt encoder, and a lightweight mask decoder. The image encoder extracts visual features, while the prompt encoder converts different prompt information into vector space. The mask decoder then integrates both to generate an object mask. The key strength lies in its ability to adapt instantly to different objects and scenarios through “prompt engineering.”
- Strengths: SAM has exceptional generalization performance and can accurately segment even objects it has never seen before. It also offers a highly intuitive visual prompt interface.
- Limitations: SAM is limited in its ability to detect or classify objects using pure text prompts alone. Its functionality is primarily focused on segmentation tasks.
- Best Use Cases: SAM is well-suited for quickly separating specific objects in an image or generating high-quality masks. It is particularly effective for use cases such as image editing, medical image analysis, and data labeling for autonomous driving.
- Grounding DINO
- Concept: Grounding DINO is an open-vocabulary object detection model based on DINO (DETR with Improved DeNoising Anchor Boxes for Object Detection). As its name suggests, the model specializes in “grounding” specific objects in an image using text prompts—that is, identifying and locating them with high precision.
- How It Works: Grounding DINO takes a text prompt as the primary input to detect objects in an image. For example, given a prompt like “Find all cars and people,” the model locates and returns bounding boxes around the relevant objects. It leverages large-scale image-text datasets to build strong links between visual and linguistic concepts.
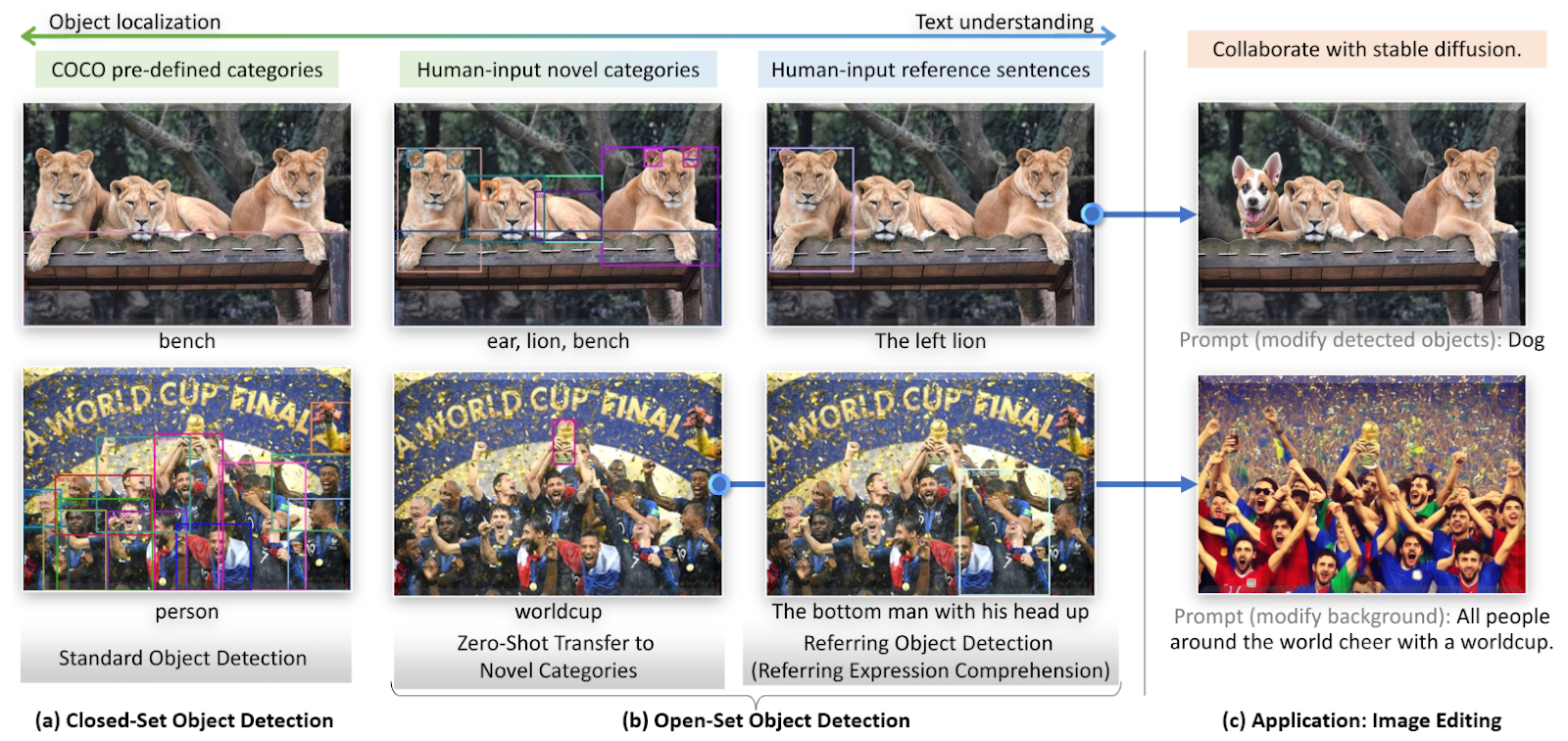
- Technical Difference: The model integrates a language model (Transformer) with a vision model (Swin Transformer) to learn visual features effectively from text prompts. It excels in using text queries to pinpoint and detect objects in images, demonstrating strong zero-shot detection performance.
- Strengths: Grounding DINO offers high flexibility by detecting a wide variety of objects based on text descriptions alone. It is particularly powerful in open-vocabulary object detection tasks.
- Limitations: Unlike SAM, Grounding DINO does not support precise mask generation by default. Its capabilities are primarily focused on bounding box-based object detection.
- Best Use Cases: Grounding DINO is well-suited for instantly detecting new products or classes, identifying specific scenarios in security monitoring, or locating items in inventory systems where flexible, text-driven object detection is needed.
- SEEM (Segment Everything Everywhere All at Once)
- Concept: SEEM can be considered a successor to SAM, with the goal of “segmenting everything, everywhere, all at once.” While SAM specializes in segmentation, SEEM aims to perform a wide range of visual understanding tasks—segmentation included—within a single unified model.
- How It Works: SEEM is designed to handle multiple types of prompts—text, point, box, sketch, reference image—and perform various tasks simultaneously, including segmentation, visual question answering (VQA), and image captioning. It represents an effort to process multimodal tasks like vision-language-segmentation tasks with a single model.
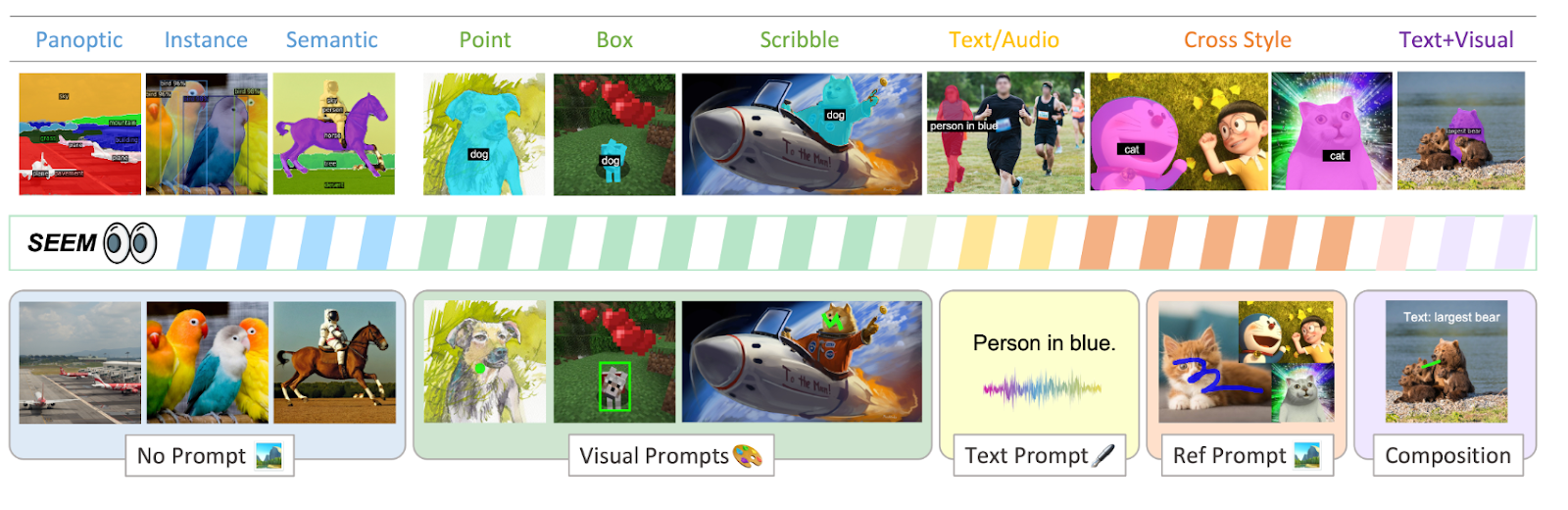
- Technical Difference: SEEM inherits SAM’s segmentation capabilities while extending to other vision tasks. With a multimodal prompt encoder and a universal mask decoder, it processes various input types, generates masks with consistency, and performs different visual inferences. In short, it shares and reuses visual knowledge by integrating otherwise siloed architectures for different vision tasks.
- Strengths: SEEM supports a wide variety of prompt types and can handle multiple visual tasks within a single model, making it highly versatile and general-purpose.
- Limitations: SEEM may not be as heavily optimized for pure segmentation as SAM, nor as specialized in text-based object detection as Grounding DINO.
- Best Use Cases: SEEM is ideal for applications that require flexible handling of diverse visual perception tasks—such as multimodal data analysis, complex visual question answering, robot vision requiring integrated visual inferencing, and smart factory automation systems.
VLM vs. VFM: The Evolution of Vision AI Models
Earlier, we introduced multi-prompt models that support both visual and textual inputs. At this point, you might be wondering how these models differ from traditional Vision-Language Models (VLMs). Let’s take a closer look at how VLMs compare to Vision Foundation Models (VFMs).
VLM: Connecting Vision and Language
VLMs are models that understand and process both images and text together. For instance, they can answer questions like “What do you see in this image?” with a text response or retrieve an image that matches a description like “Show me a red sports car.” The CLIP model we discussed in Part 1 is a prime example of a VLM. VLMs map visual and textual information into a shared representation space, enabling the model to learn associations between concepts across modalities.
Traditionally, VLMs have been developed with a focus on specific vision-language integration tasks such as Visual Question Answering (VQA), Image Captioning, and Text-Image Retrieval. That is, they were built to connect specific text and image pairs rather than perform a wide range of vision tasks like detection, segmentation, or tracking in an integrated way.
VFM: Unifying All Vision Tasks and Maximizing Synergy
So, how does a Vision Foundation Model (VFM) differ from a VLM?
Conventional vision models—and even some multimodal models—typically handle different tasks by combining several independent submodules. For example, they may use separate submodels for image classification, object detection, and segmentation. However, this approach has limited ability to generate synergy between tasks.
VFM overcomes this limitation by aiming to maximize synergy across diverse vision and multimodal tasks. It doesn’t just combine multiple capabilities into one model—it redefines the entire approach to visual understanding. Rather than being limited to specific vision-language tasks, a VFM is a general-purpose model designed to perform virtually all perception and generation tasks based on visual information.
A VFM achieves this level of integration through the following key features:
- Open-Ended Architecture: VFMs support technologies like open-vocabulary object detection, which allow them to handle new visual concepts and tasks beyond predefined categories. This enables the model to understand and process unknown objects or concepts that were not present in the training data.
- Unified Learning Across Diverse Granularity Levels: VFMs integrate learning across multiple levels of visual granularity—from object-level (region) to pixel-level detail—enabling the model to understand both broad contexts and fine-grained patterns. This allows VFMs to process everything from holistic scene understanding to precise pixel-level analysis, forming a foundation for consistent performance across classification, detection, and segmentation tasks.
- Advanced Prompt-Ability: Through multi-modal prompting and in-context prompting, VFMs allow users to interact with the model in various ways. This includes not only text prompts but also visual references, clicks, and drag gestures—offering flexible control over the model’s behavior and outcomes.
In short, a VFM serves as a general-purpose AI agent for all vision tasks, overcoming the fragmentation of earlier models and maximizing real-world applicability across industries. Once trained, it can generalize effectively and transfer knowledge across a wide range of domains and tasks.
In the next post, we’ll dive into the technical challenges Vision Foundation Models have faced and explore where the technology is headed. If you have any questions about implementing a VFM, feel free to leave your information in the contact form below. Our experts at Superb AI will be in touch shortly.
Related Posts

Insight
How to Restart an AI Project That Stalled for Lack of Data—with Just 10 Images

Hyun Kim
Co-Founder & CEO | 7 min read

Insight
Three Years of the Few-Shot Object Detection Challenge: Mapping the Global Vision AI Landscape
Hyun Kim
Co-Founder & CEO | 7 min read

Insight
⑪ Germany's Physical AI Moment: Siemens, BMW, and the Robot Unicorn Counteroffensive
Hyun Kim
Co-Founder & CEO | 15 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.