技術
Superb AIの「ZERO」は、いかにしてCVPR 2026 Few-Shot Object Detection Challengeで総合1位を獲得したのか:優勝を支えたソリューションの技術解説

Superb AI Japan
2026/06/19 | 10 min read

要点
- Superb AIの優勝ソリューションは、ビジョン基盤モデル「ZERO」を中核とする5段階のパイプラインで構成されています。具体的には、データ・プロンプト探索、ファインチューニング、再分類、テストタイム拡張、マルチソース融合の5段階です。
- 設計思想は、技術レポートのタイトルにも示されている二つの軸に基づいています。Discover the Unknownは、少量データだけでは不足する情報を、プロンプト探索と擬似ラベリングによって拡張するアプローチです。Reconsider the Knownは、モデルが検出した結果を軽量なモジュールでもう一度検証するアプローチです。
- テキスト、視覚的なサンプル、周辺コンテキストを組み合わせたマルチモーダルプロンプトにより、カテゴリ名が曖昧になりやすい産業・医療ドメインの課題に対応しました。
- 平均mAPは53.9を記録し、2位の復旦大学・Lenovo産学連携チームを2.3ポイント、前年の最高記録を3.8ポイント、公式ベースラインであるGroundingDINOを20.6ポイント上回りました。
- 大きな差別化要因は、システムの「軽さ」です。一部の競合チームが結果の補正に超大規模モデルを使用したのに対し、Superb AIは軽量かつ拡張性の高い再分類モジュールを採用しました。このモジュールについては、現在特許出願を進めています。
Superb AIは、独自開発した産業特化型ビジョン基盤モデル「ZERO」を中核とするシステムで、CVPR 2026 Foundational Few-Shot Object Detection ChallengeのOverall Trackにおいて総合1位を獲得しました。
第1編の優勝発表では、今回の成果が持つ意味をご紹介しました。本記事では、優勝ソリューションが技術的にどのように機能したのかを、各段階に分けて解説します。技術レポート『Discover the Unknown and Reconsider the Known: Specializing Multimodal Promptable Detectors for Diverse Domains』(共同筆頭著者:Kyeongryeol Go、Hyundong Jin)や公開コードを読む前の「ガイド」としてもご活用いただけます。
課題:なぜ産業ドメインでは汎用的な物体検出が機能しにくいのか
Few-Shot Object Detectionの難しさは、単に「データが少ない」ことだけではありません。本質的な課題は、ドメインギャップにあります。
一般的なインターネット画像で学習したモデルは、X線画像、熱画像、航空画像など、学習時に触れていない産業データに適用すると、性能が急激に低下します。
実際に、主催者がGroundingDINOやQwen2.5-VLなどの代表的な汎用モデルを用いて構築したベースラインでは、多くのデータセットで精度が1%未満にとどまりました。今回のチャレンジで使用されたデータセット「Roboflow20-VL」が20の専門ドメインで構成されているのも、まさにこの限界を検証するためです。
さらに、もう一つの課題があります。
製造、医療、セキュリティなどのドメインで使用されるカテゴリ名は、専門的な略語であったり、意味が曖昧であったりする場合が少なくありません。そのため、テキストプロンプトに依存する従来のオープンセットモデルであるGLIPやGroundingDINOなどは、「何を検出すべきか」を安定して理解できないことがあります。
Superb AIのソリューションは、この二つの課題、すなわちドメインギャップとカテゴリ名の曖昧性に正面から取り組みました。
優勝ソリューションを支える二つの軸:「Discover the Unknown」と「Reconsider the Known」
技術レポートのタイトルには、今回のソリューションの設計思想がそのまま表れています。
Discover the Unknown:未知の情報を発見する
- 少数のサンプルだけでは不足する情報を、最適なプロンプトの探索と擬似ラベリングによって自ら拡張していくアプローチです。
Reconsider the Known:既知の結果を見直す
- モデルが一度検出した結果を、軽量なモジュールでもう一度検証し、精度を高めるアプローチです。
未知の現場をまず把握して学習し、自ら導き出した答えをもう一度検証する。
この二つの動作が、パイプライン全体を貫いています。
優勝パイプラインを構成する5つの段階
① データとプロンプトの探索(Discover)
最初の段階では、ファインチューニングを開始する前に、モデルへ与える「材料」を最適化します。ここでは、二つの取り組みが重要になります。
プロンプトのエイリアス探索(alias search)
データセットで提供される標準のクラス名は、略語であるなど、対象を理解するための情報が不足している場合があります。
そこで、対象の視覚的な特徴を表現するエイリアス候補を作成し、精度の向上が止まるまでドメインごとに候補を一つずつ追加しながら、貪欲法によって最適な組み合わせを探索します。
ZEROは、キャッシュ済みの1回の演算結果を利用して、任意のエイリアスの組み合わせをスコアリングできます。そのため、この探索を非常に低いコストで実行できます。
人が一つひとつプロンプトを調整するのではなく、どの表現が最も効果的かをモデル自身が見つける仕組みです。
視覚的なサンプルの選定
通常は、1カテゴリあたり提供される10枚のサンプルをすべて使用します。しかし、Superb AIは、すべてのサンプルをそのまま使用する方法を採用しませんでした。
すべてを使用すると、一部のサンプルがノイズや偏りとして作用する可能性があるためです。
代わりに、埋め込み表現に基づいて多様性を考慮し、最も効果的なサンプルだけを選択するサブサンプリングを適用しました。
これは、Superb Platformのデータキュレーションサービス「Curate」で、意味のあるデータを選別する際に使用されている方法論と同じ系統の技術です。研究と製品が共通の技術基盤から相乗効果を生み出している部分といえます。
② 擬似ラベリングによる学習データの拡張(Discover)
少量のサンプルを利用する際のもう一つの課題が、「疎なアノテーション」です。
画像内に存在する物体にラベルが付いていない場合、モデルはその物体を誤って「背景」として学習してしまいます。この問題を解決するため、AIが一次ラベルを生成・検証し、学習データを拡張する擬似ラベリング(pseudo-labeling)の段階を設けました。
具体的には、ZEROとSAM3が物体候補のバウンディングボックスを生成します。設定したしきい値を通過した領域を切り出し、Qwen3-VL-32Bが各領域をドメイン内のカテゴリのいずれかに分類します。いずれのカテゴリにも該当しない場合は、「unknown」として除外します。
こうして選別されたラベルを既存の正解ラベルと統合し、拡張学習データセットを構成します。
外部モデルは、このようにファインチューニング用のラベルを準備するデータ準備段階で補助的に使用されます。実際の物体検出を担うモデルはZEROです。この構成は、公開されている技術レポートにもすべて明記されています。
質の高いラベルを迅速かつ正確に確保するこのプロセスには、Superb AIがデータラベリング自動化事業を通じて蓄積してきたノウハウが反映されています。
③ ZEROのファインチューニング:2段階に分けた探索によるドメイン適応
拡張したデータを使用し、ZEROを各ドメインに合わせてファインチューニングします。
ただし、20ものドメインに対して、すべてのハイパーパラメータ空間を網羅的に探索することは現実的ではありません。一方で、すべてのドメインに同じ設定を適用することも最適とはいえません。
そこで、探索プロセスを二つの段階に分けました。
まず、学習率とテキスト拡張戦略を選定します。次に、バックボーン、検出ヘッド、言語アダプターのうち、どのモジュールを学習対象とするかを選択します。
この設計は、最適な学習率と拡張戦略が、学習対象とするモジュールの選択にかかわらず安定しているという経験的な観察に基づいています。
これにより、各ドメインに最適な設定を、現実的なコストで探索できます。
④ 軽量再分類モジュール:検出結果をもう一度見直す(Reconsider)
Few-Shotデータでファインチューニングした検出モデルは、「物体がどこにあるか」という位置特定(localization)には優れている一方、「その物体が正確に何であるか」という分類(classification)を誤ることがあります。このような誤りを、単一の信頼度しきい値だけで除外することは困難です。
Superb AIは、この課題に対応するため、二つの仕組みを追加しました。まず、カテゴリごとに異なる信頼度しきい値を設定し、個別に補正します。さらに、Few-Shotサンプルを用いて学習した軽量な二次分類器が、検出結果に付与されたクラスラベルをもう一度検証します。
分類器は、信頼度の高い検出結果にのみ適用されます。信頼度の低い検出結果では、分類器自体の判断も不安定になる可能性があるためです。
再分類の結果に応じて、既存のラベルを維持するか、別のラベルへ再割り当てします。十分な確信が得られない場合は、検出結果自体を除外します。
つまり、検出器が候補を漏れなく見つけ、分類器がその候補に付けられたクラスラベルを再検討するという役割分担です。
重要なポイントは、モジュールの「軽さ」です。一部の競合チームが、この補正段階に数百億パラメータ規模の超大規模モデルを使用したのに対し、Superb AIは軽量かつ拡張性の高い構造を選択しました。
これは、チャレンジのスコアだけを目的とした設計ではありません。実際の顧客環境へそのまま導入できる実用性を考慮した選択です。Superb AIは現在、このモジュールに関する特許出願を進めています。
⑤ テストタイム拡張とマルチソース融合:性能を最後まで引き出す
推論段階では、マルチスケール推論、水平反転、タイリングを組み合わせたテストタイム拡張(Test-Time Augmentation)を適用します。タイリングは、大きな画像内に存在する小さな物体や、密集した物体をより正確に検出するために使用されます。その後、複数の検出結果をクラス認識型NMSによって整理します。最後に、異なる設定、異なるバックボーンサイズ、異なるプロンプト方式であるテキストプロンプトと視覚プロンプトから得られた、複数の検出結果を融合します。
特徴的なのは、結果を融合する単位です。評価指標であるmAPがカテゴリごとのスコアを平均する構造であることを活用し、ドメイン単位ではなく、カテゴリ単位で最も高い性能を示すソースを選択するルーティングを適用しました。さらに、上位のソースはWeighted Boxes Fusionなどの手法を用いて統合しました。
チャレンジ規定で認められている最大3モデルの範囲内で、サイズの異なる3種類のZEROチェックポイントをアンサンブルし、予測を安定化させたことが最後の要素です。
すべてのチューニングは検証データのみを使用して実施し、テストデータは最終提出時にのみ使用することで、評価の厳密性も確保しました。
何が性能差を生み出したのか
公式ベースラインであるGroundingDINOの平均mAPは33.3、前年の最高記録は50.1でした。
Superb AIのソリューションは53.9を記録し、公式ベースラインを20.6ポイント、前年の最高記録を3.8ポイント、2位の復旦大学・Lenovo産学連携チームの51.6を2.3ポイント上回りました。この差は、一つの特別な手法だけによって生まれたものではありません。前述した五つの段階が連携して機能した結果です。
カテゴリ別の結果を見ると、その一貫性がより明確に表れています。
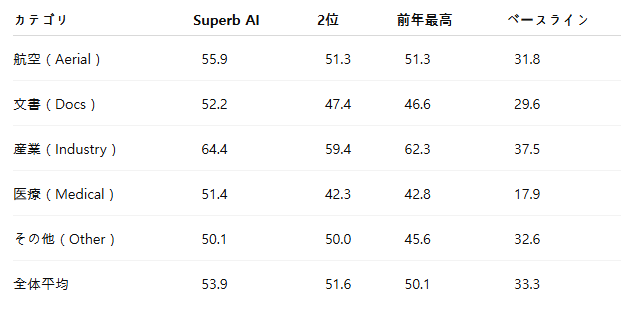
Superb AIは、7つのカテゴリのうち5カテゴリで1位を獲得しました。
特に産業カテゴリでは64.4を記録し、主催者の発表でもハイライトとして取り上げられるほど明確な優位性を示しました。最も難易度の高い医療カテゴリでは、2位を9ポイント以上上回りました。カテゴリ名が曖昧なドメインほどマルチモーダルプロンプトが有効であるという仮説が、難易度の高い医療ドメインにおいて数値で実証された結果といえます。
その基盤には、Superb AIの「データ中心AI」という考え方があります。
質の高いデータを迅速に確保し(②)、意味のあるデータを選定し(①)、最終的な結果を検証する(④)一連のプロセスは、いずれもSuperb AIが事業を通じて蓄積してきた能力と直接つながっています。
スコアの先へ:製品思想を反映したソリューション
公開コード「zero-fsod」にも、Superb AIの製品思想が反映されています。
検出器をHTTPサービスとして抽象化することで、モデルの重みとソースコードを保護しながら、パイプラインとAPI仕様を公開する構造を採用しています。これは、受賞要件である再現性と企業の知的財産保護を両立する方法であり、「製品としてのZERO」という位置付けとも一致しています。Superb AIのコ・ギョンリョル(Kyeongryeol Go)機械学習エンジニアは、次のように述べています。
「重要だったのは、巨大なモデルを使用することではなく、現場へ軽量かつ迅速に適応する方法を設計することでした。ZEROの効率性によって、限られた期間の中でも複数の仮説を素早く検証し、最適な組み合わせを見つけることができました。」
今回のソリューションの基盤となったZEROの最新バージョンは、AWS Marketplaceからすぐに利用できます。チャレンジで性能が実証された「少量データで各ドメインへ迅速に適応する」プロセスは、ドメイン別のモジュール機能としてSuperb Platformへ順次実装される予定です。
よくあるご質問(FAQ)
Q. ZEROは単独で物体検出を行うのですか?SAM3とQwen3-VLはどのような役割を担いますか?
実際の物体検出はZEROが行います。SAM3やQwen3-VLなどの外部モデルは、ファインチューニングに使用する学習用ラベルを準備する擬似ラベリングの段階で補助的に利用されます。この構成は、公開されている技術レポートにもすべて明記されています。
Q. マルチモーダルプロンプトが重要なのはなぜですか?
産業・医療ドメインでは、カテゴリ名が専門的または曖昧である場合が多く、テキストだけでは対象の視覚的な意味をモデルが十分に把握できないことがあります。ZEROは、テキスト、視覚的なサンプル、周辺コンテキストを組み合わせて活用することで、この曖昧性を解消します。実際に、医療カテゴリでは2位を9ポイント以上上回る結果を記録しました。
Q. 「軽量再分類モジュール」は何をするものですか?
モデルが検出した物体の位置は維持しながら、その物体のクラスラベルを軽量な分類器でもう一度検証し、精度を高める仕組みです。超大規模モデルではなく、軽量かつ拡張性の高い構造を採用することで、実際の現場への適用性を高めています。現在、このモジュールに関する特許出願を進めています。
Q. ベースラインと比較して、性能はどの程度向上しましたか?
主催者の公式ベースラインであるGroundingDINOの平均mAP 33.3に対し、Superb AIのソリューションは53.9を記録し、20.6ポイント向上しました。前年の最高記録である50.1と、2位の51.6も上回り、Overall Trackで総合1位を獲得しました。
Q. この技術を実際に利用できますか?
優勝ソリューションの基盤モデルであるZEROは、AWS Marketplaceからすぐに利用できます。また、優勝ソリューションの技術レポートとパイプラインコードも公開されています。




Superb AIについて
Superb AIは、エンタープライズ向けのAIトレーニングデータプラットフォームであり、ML(機械学習)チームが組織内でトレーニングデータをより効果的に管理・提供できるよう、データ管理の新しいアプローチを提案しています。2018年に発表されたSuperb AI Suiteは、自動化、コラボレーション、プラグアンドプレイモジュールのユニークな組み合わせを提供し、多くのチームが高品質なトレーニングデータセットを準備する時間を大幅に短縮する手助けをしています。この変革を体験したい方は、今すぐ無料でご登録ください。