インサイト
画像分類タスクのためのより良いConvNetアーキテクチャを選択する方法とは?

Dasha Gurova
Community Manager | 2022/06/07 | 8 min read

はじめに
ディープラーニング技術をうまく応用するには、どのようなアルゴリズムが存在し、それらがどのように機能するかを説明する原理に関する十分な知識だけでは不十分です。機械学習の実践者は、特定のアプリケーションのためにアルゴリズムを選択する方法を知っておく必要があります。
どのような機械学習プロジェクトにも共通する公式はありません。機械学習システムを改善するための大きな要素は、ユースケースにうまく対応するソリューションを見つけるまで実験することです。しかし、コンピュータビジョンのタスクでは、圧倒的な数のツールやモデルアーキテクチャが利用可能です。この記事では、画像分類プロジェクトに適したアーキテクチャを選択するための戦略について説明します。
画像分類タスクの概要
画像分類は、画像全体を全体として理解しようとするタスクです。その目的は、画像を特定のラベルに割り当てることによって分類することです。画像分類は、オブジェクトの位置特定、検出、セグメンテーションなど、他のコンピュータビジョンタスクの基礎を形成するため、基本的な問題と考えることができます。
ImageNetチャレンジは、画像分類に関して、ほとんどのコンピュータビジョンアルゴリズムの(非公式な)ベンチマーク基準となっています。これは、1,000のオブジェクトクラスにわたって100万以上の画像からなる注釈付き写真の大規模データセット、別名ImageNetからのサブセットを使用する年次コンテストです。2012年、AlexNetと呼ばれる大規模な深層畳み込みニューラルネットワークがImageNet Challengeで優れた性能を示し、注目を集めるまで、画像に関する機械学習は歴史的に困難な課題でした。それ以来、畳み込みニューラルネットワーク(ConvNets)は非常に速く進化し、視覚的なタスクにおいて人間レベルの性能を超えるようになったのです。
そして2022年、Vision Transformer(ViT)モデルは、現在チャートの上位にランクインしています。トランスフォーマーアーキテクチャは、当初自然言語処理のために提案されたもので、各単語を予測する際に入力テキスト列の一部に注目させるという自己注目メカニズムを採用しています。Vision Transformerは、このアテンションの考え方を画像に適用したモデルで、入力された画像を分割したパッチが単語に相当すると考えています。トランスフォーマーのアーキテクチャを画像に適用するというコンセプトは非常に興味深く、ブレークスルーの源となる可能性を秘めています。このブログを書いている時点では、ViTモデルはデータセットによってうまくスケールするが、小規模なデータセットではまだ問題があります。まだ完全に理解しているわけではなく、ViTモデルを実用化し始めたばかりなのです。
一方、ConvNetsは10年以上前から実用化され、その後のデータの民主化、計算能力の向上、ツールやフレームワークの豊富さにより、非常に有効で一般的になってきました。そして、この記事の目的は、実務家が実世界のコンピュータビジョンの問題に対してモデルアーキテクチャを選択するのに役立つことであるため、ConvNetsを用いた教師あり画像分類に焦点を当てることにします。
ConvNetアーキテクチャの選択
実際のコンピュータビジョンのプロジェクトで採用できる画像分類のためのConvNetのアーキテクチャはたくさんあります。しかし、どのモデルアーキテクチャを使用するかを選択することは、必ずしも正確な科学ではありません。しかし、どんな機械学習プロジェクトでも、常に目標と期待を設定することから始めるべきです。
期待される性能の決定
特定のユースケースに対して期待される妥当なパフォーマンスのレベルは、どのように決定すればよいのでしょうか。機械学習エンジニアにとって、モデルの精度と推論速度の両方が重要です。
- 精度 - 最高の精度を持つモデルを使いたい、それはエンドユーザーにとってより良い経験を意味します。
- モデルの学習と推論のスピード - 私たちは、モデルができるだけ速く学習し、予測を生成することを望みます。なぜなら、実運用では、何千人ものユーザーにサービスを提供しなければならず、何か問題が発生したらすぐにモデルを再学習させる必要があるかもしれないからです。
一般的に、より高い精度を得るためには、より深い(より大きな)モデルを使用する必要があります。しかし、モデルが大きくなればなるほど、パラメータの数が多くなり、実行速度が遅くなります。コンピュータビジョンにおける一般的なSOTAアーキテクチャの精度/複雑さのトレードオフを可視化するには、非常に有用なチャートを特徴とする論文「Benchmark Analysis of Representative Deep Neural Network Architectures」(2018年発表)を参照するとよいでしょう。
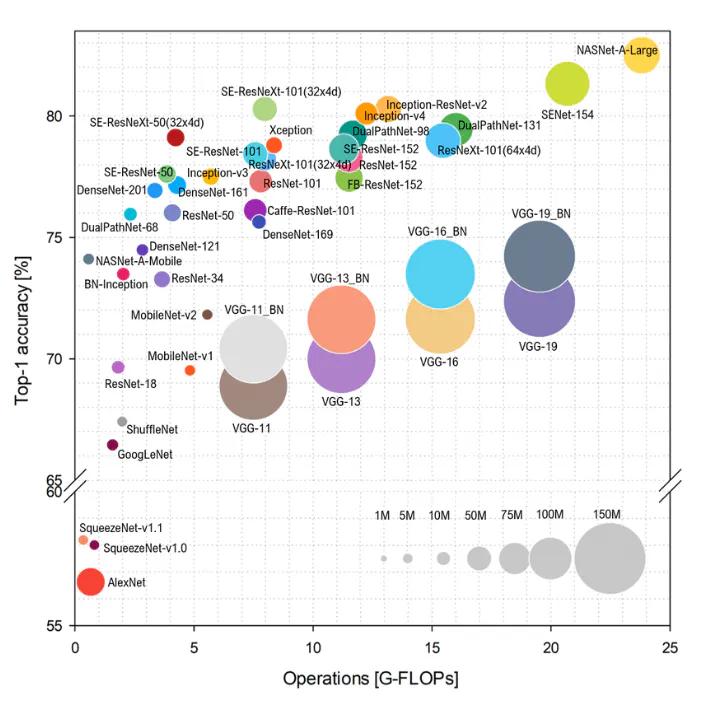
Benchmark Analysis of Representative Deep Neural Network Architectures
業界におけるほとんどのディープラーニングの展開では、アプリケーションが安全で、計算コストが低く、ユーザーにアピールするために必要な精度レベルを考慮する必要があります。例えば、プロジェクトの最終目標が、エッジデバイスにモデルを展開することだとわかっているとします。この場合、複雑さはより重要な問題であり、精度を少し犠牲にしなければならないかもしれません(ここではMobilNetアーキテクチャが良い選択となります)。
一方、学習コストと予測レイテンシーがプロジェクトの懸念事項ではなく、最高の精度を求める場合は、最大/最良のモデルを選択するか、あるいは複数のモデル・アーキテクチャのアンサンブルを検討することもできます。
現実的な希望性能が決まれば、アーキテクチャの検索はこの目標に導かれて行われます。次のセクションでは、最も一般的に使用されているSOTA ConvNetアーキテクチャのいくつかにズームインしてみましょう。
一般的なConvNetアーキテクチャ
このセクションでは、現在広く使われている様々なConvNetアーキテクチャについて、その進化、利点、欠点などを簡単に説明します。
VGGファミリー
AlexNetを改良するために、研究者は畳み込み層の深さや数を増やし始めました。より多くの層を追加することで、より良い分類精度を得ることができました。VGGアーキテクチャ(2014年提案)は、より深いネットワーク構造を持ち、精度が向上しましたが、AlexNetと比較してサイズが2倍になり、実行時間も増加しました。16の畳み込み層(後の反復では19)を持ち、精度を落とすことなく3x3畳み込みを独占的に使用します。
**なぜVGGアーキテクチャを選んだのか?**シンプルなアーキテクチャのため、理解や実装が比較的容易です。また、一般的な画像分類のシナリオで良好な性能を発揮します。また、VGGアーキテクチャはテクスチャやコンテンツといった画像の階層的な要素を学習することが分かっており、スタイル変換モデルの学習用としてよく利用されています。
Inception
Inceptionネットワークは2014年に世に出ました。このアーキテクチャの最大の特徴は、コンピューティングリソースの利用率を向上させながら、畳み込みニューラルネットワークを構築していることです。ネットワークに畳み込み層とプーリング層を並べるとき、設計者は複数の選択肢を持ち、最適な判断は自明ではありません。Inceptionモジュールは、どの層の並びが最も効果的であるかを事前に決定するのではなく、データとトレーニングに基づいてネットワークが選択できるいくつかの選択肢を提供します。
**なぜInceptionアーキテクチャを選ぶのか?**VGGよりも深いCNNであり、パラメータが少なく、精度が大幅に向上します。その結果、学習時間が短くなり、学習済みモデルのサイズも小さくなります。一方で、このアーキテクチャはゼロから実装するのはかなり複雑になります。
ResNet
2015年に登場したResNetまたはResidual Neural Networkは、モデルの深さを増すという傾向を続けています。層を増やしすぎることの欠点は、そうすることで消失勾配問題によりネットワークが学習データにオーバーフィットしやすくなることです。これを解決するために、ResNetは、ネットワークの前の層から後の層に情報を流すことができるスキップ接続を持つ新しい残差モジュールアーキテクチャを導入し、勾配が流れるための代替ショートカットパスを作り出しました。この基本的なブレークスルーにより、何百もの層を持つ非常に深いニューラルネットワークの学習が可能になった。ResNetの最も一般的なバージョンはResNet50で、50層ですが、より大きなバージョンは100層を超えることができます。
**なぜResNetアーキテクチャを選ぶのか?**ResNetは、特に分類タスクで非常に優れたパフォーマンスを発揮するため、広く使われています。さらに、グローバル平均プーリングを使用しているため、(VGGのような以前のアーキテクチャと比較して)学習が高速化されます。試行錯誤を繰り返したものを求めるのであれば、これは良い選択です。
Xception
Xceptionモデルは、2017年にFrancois Chollet(Kerasの生みの親)によって提案されました。このモデルは、Inceptionアーキテクチャを拡張し、深さ方向に分離可能な畳み込みとResNetスタイルのスキップ接続で置き換えたものです。
Xceptionアーキテクチャを選択する理由 Xceptionは、よりシンプルな設計でResNetとInceptionの両アーキテクチャの特徴を組み合わせて提供します。そのため、アーキテクチャの定義や変更が容易です。リニアスタックレイヤーにより、Inceptionよりも高速に学習することができ、ImageNetにおける精度の点でもInceptionをわずかに上回ります。
MobileNet
MobileNetアーキテクチャは、スマートフォンやタブレットなどのエッジデバイスに適したニューラルネットワークを探すために、Googleが開発したものです。MobileNetアーキテクチャは、深さ方向に分離可能な畳み込みと幅乗算器(ハイパーパラメーター)という2つの重要な革新的技術を導入しました。深さ方向の分離可能な畳み込みは、通常の畳み込み層をより少ないパラメータで置き換え、より計算効率が高くなります。幅倍率は、各畳み込み層に使用するパラメータ数を制御するパラメータです。これにより、サイズや速度対精度のトレードオフ曲線に沿って、複数のネットワークを作成することができます。
**なぜMobileNetアーキテクチャを選ぶのか?**このアーキテクチャでは、モデルの配列を作成することができるため、より高性能なデバイスは、より大きく、より正確なモデルを受け取ることができます。一方、性能の低いデバイスは、より小さく、精度の低いモデルを使用することができます。計算機資源の乏しいエッジデバイスに展開できるモデルが必要な場合、MobileNetは最適な方法です。
エフィシェントネット
同じチームによるMobileNetV2の後のイテレーションはEfficientNetと呼ばれています。逆残留ボトルネックが再び基本構成要素となっていますが、最適化の目標は、モバイル推論レイテンシーよりも予測精度の方に調整されています。畳み込みアーキテクチャには、より多くの層を使用する、各層でより多くのチャンネルを使用する、より高解像度の入力画像を使用する、という3つの主なスケーリング方法があります。EfficientNetの論文では、これらのスケーリング軸が独立していないことを指摘しており、このネットワークファミリーは、1つのスケーリング軸だけでなく、3つのスケーリング軸に沿ってスケーリングされています。
EfficientNetのアーキテクチャを選ぶ理由 このアーキテクチャは、あらゆるウェイト数に対して最適なパフォーマンスレベルを提供するため、多くの応用MLチームの主力製品となっています。もし、サイズやスピードの制約がなく(自動スケーリングが可能なクラウドシステムでの推論)、最も良い/最も好きなモデルを求めるのであれば、EfficientNetを検討してください。
ニューラル・アーキテクチャの探索
過去10年間の大半は、研究者が手作業で作成した新しいネットワークアーキテクチャによって、最先端の結果が達成されました。人間の直感と実験に依存する多くのタスクと同様に、やがて誰かが「機械がもっとうまくできないか」と問いかけました。ニューラル・アーキテクチャ・サーチ(NAS)は、ニューラル・ネットワークの設計プロセスを自動化します。目標(モデルの精度など)と制約(ネットワークのサイズや推論レイテンシなど)が与えられると、これらのメソッドは層の構成可能なブロックを並べ替えて、新しいアーキテクチャを形成する。NASは、人間が設計した同種のアーキテクチャを凌駕する新しいアーキテクチャを発見しましたが、このプロセスには非常に高い計算量が必要とされます。
**なぜNASアーキテクチャを選ぶのか?**計算コストがかかるだけでなく、NASの技術によって発見されたネットワーク・アーキテクチャは、通常、人間が設計したものと似ていません。なぜうまく機能するのかが分からないので、あるアイデアを他のアーキテクチャに移すことができません。それでも、NASは高い精度を達成し、場合によってはそれで十分なこともあるのです。
Tips to Get Started
Start simple
画像分類プロジェクトに採用できるいくつかのConvNetアーキテクチャについてお話しました。しかし、このような単純な作業から始めるのは難しいです。しかし、実務家から最も多く聞かれるアドバイスがあるとすれば、それは常に最も単純で適切なモデル、つまりベースラインモデルから始めるということです。
なぜベースラインモデルが必要なのでしょうか?
シナリオに関係なく、モデルを適切に評価するためには、ベンチマークが必要です。シンプルなベースラインモデルはベンチマークの役割を果たし、実験する他のモデルアーキテクチャをより有益に評価することが可能になります。
また、ベースラインモデルは、問題があるタスクに対してデータが不十分かどうか示すのに役立ちます。例えば、分類モデルが特定のクラスを予測できない場合、この欠点に対処するために努力する必要があります。複雑なモデルを構築した後で、欠陥のあるデータで学習させられたことを知ることになるとは、想像もつかないことでしょう。ベースラインモデルを確立したら、ハイパーパラメータを調整し、データを操作し、シンプルなモデルから得られた知見に基づいて他のアーキテクチャを試すことによって、徐々にパフォーマンスを向上させることができます。
よく理解できるモデルを選択する
先週どこかのカンファレンスで発表されたばかりのアルゴリズムにこだわるのではなく、自分がよく理解できるモデルを選びましょう。特に、このモデルを実運用に展開することが目標であれば、なおさらです。理解できるモデル・アーキテクチャは、デバッグ、微調整、改善点の特定、そして反復が容易になります。実用的な画像分類のアプリケーションでは、良いデータで妥当なConvNetアーキテクチャはしばしばうまくいき、実際、あまり良くないデータで優れたアルゴリズムよりも性能が良くなることがあります。まず、ImageNetで良好な結果を出している単純なConvNetアーキテクチャ(例えば、層数の少ないVGG)を選び、それを自分のデータで試してみることから始めるとよいでしょう。
すぐに実装できるモデルを選ぶ
最初のモデルが最後のモデルにはならない可能性が高いです。良いオープンソースの実装を選び、それを使ってすぐに始めましょう。あるいは、選択したアーキテクチャをデータで迅速に学習させるために、転移学習を採用するのがよりよい方法です。転移学習は、最も人気のあるアーキテクチャの事前学習された重みを活用することができる、貴重な技術です。KerasやPytorchのような高レベルの深層学習フレームワークによって、転送学習の利用が驚くほど簡単になり、データ上で最先端のアーキテクチャを実行または訓練するのに、数行のコードしか必要ないことがよくあります。転移学習はそれ自体が一つのトピックですが、この記事の範囲外です。詳しくはこちらで解説しています。
独自のベンチマークを作成する
もちろん、あなたのプロジェクトにとって望ましい性能を達成できるモデル・アーキテクチャが複数あるかもしれません。最も単純で適切なモデルでベースラインを確立した後、いくつかのアーキテクチャで実験し、プロジェクトの性能目標を満たす最適なものを選ぶことで、さらにオプションを検討することができます。オープンソースのツールや転移学習を使って、他の候補のアーキテクチャをすばやく実装して訓練し、ベースラインモデルを上回る性能または複雑さの改善をもたらすかどうかを確認します。
まとめ
コンピュータビジョンのプロジェクトに適した、最も有名で一般的に使用されている畳み込みニューラルネットワークアーキテクチャについて説明しました。また、プロジェクトの目標やリソースを考慮し、最適なアーキテクチャを選択する方法について検討しました。コンピュータビジョンは継続的に成長している領域であり、常に新しいモデルが登場し、境界をさらに押し広げることを期待しています。しかし、ほとんどの実世界のアプリケーションでは、大規模で複雑なモデルは避け、プロジェクトにとって計算上手頃で、適切な精度を提供するモデルを選択したいと思うでしょう。
あなたの画像分類タスクにどのConvNetアーキテクチャを選択するかに関わらず、Superb AIは常にここにいて、ツールとサポートの両側から支援する準備ができています。画像やビデオを素早く簡単に分類するために私たちのラベリングスイートを使用したり、あなたのためにカスタムオートラベルを作成したり、最初から最後まであなたのためにこれらのタスクを専門的に処理することができる私たちのマネージドサービスを使用したりすることができます。どこから始めればいいのかわからないですか?私たちのチームにご連絡いただければ、正しい方向にガイドさせてただきます。





Superb AIについて
Superb AIは、エンタープライズ向けのAIトレーニングデータプラットフォームであり、ML(機械学習)チームが組織内でトレーニングデータをより効果的に管理・提供できるよう、データ管理の新しいアプローチを提案しています。2018年に発表されたSuperb AI Suiteは、自動化、コラボレーション、プラグアンドプレイモジュールのユニークな組み合わせを提供し、多くのチームが高品質なトレーニングデータセットを準備する時間を大幅に短縮する手助けをしています。この変革を体験したい方は、今すぐ無料でご登録ください。