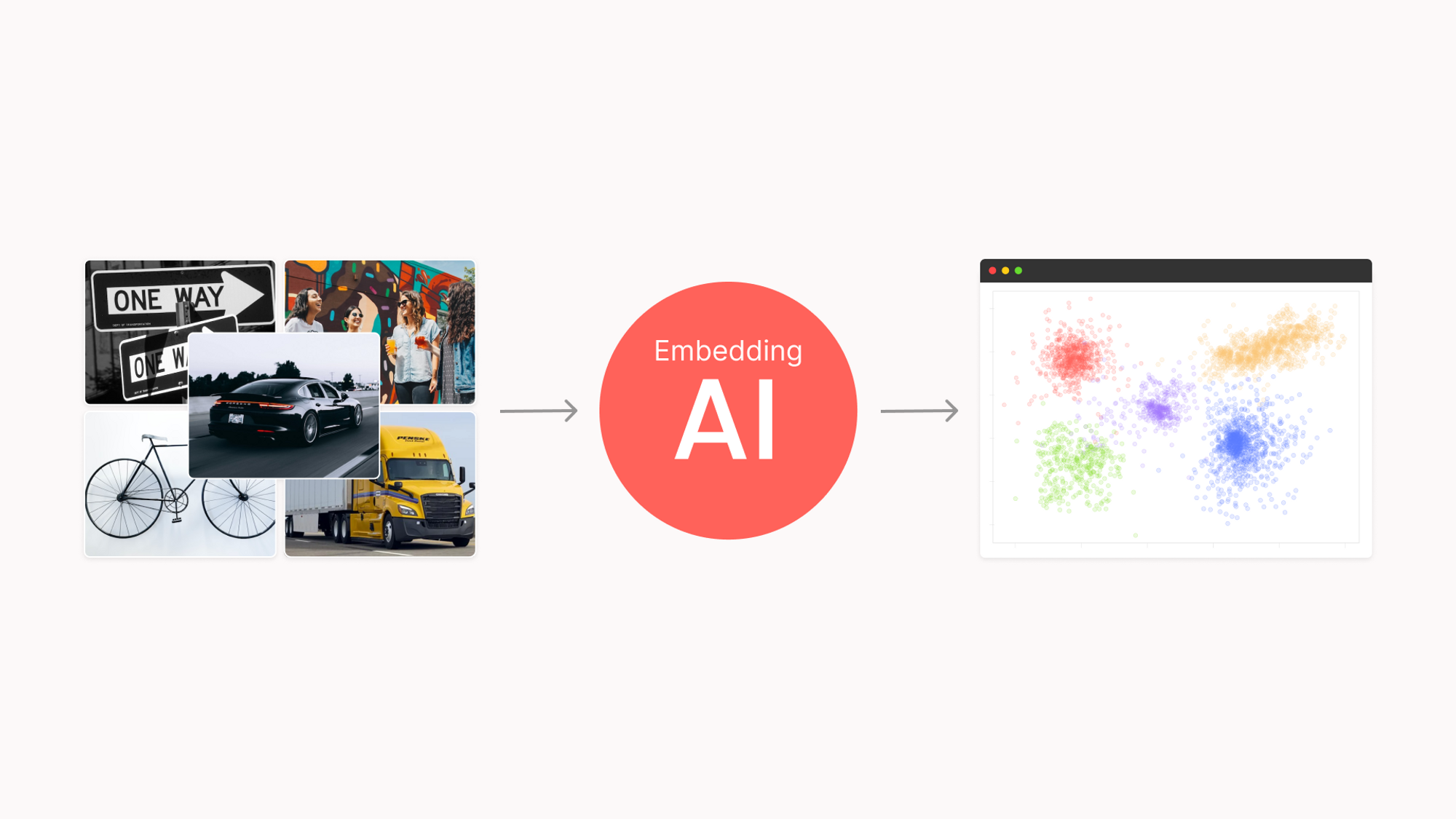
In the realm of computer vision, engineers and data scientists face a daunting challenge: understanding and organizing vast amounts of image data. As the demand for high-performing computer vision models continues to grow, the need to efficiently process large volumes of unstructured or raw data becomes increasingly critical.
The task of converting this raw data into a structured form that machines can comprehend and utilize poses a significant hurdle for both data scientists and computer vision engineers. This is where the concept of embeddings comes into play.
Embeddings serve as the backbone for effective data curation, offering a means for professionals to better understand their image data and streamline the process of feeding it to machine learning models. Despite their crucial role, generating embeddings for computer vision data curation remains a complex and arduous task.
In this article we’ll delve into the intricacies of this process, illuminating the various obstacles and factors that contribute to its difficulty. As we explore this pivotal aspect of computer vision, we aim to provide valuable insights into the challenges faced by the field and the innovative solutions being developed to overcome them.
Transforming Data into Vector Space
The crux of generating embeddings for computer vision data curation lies in converting unstructured data into a form that machine learning or computer vision models can readily understand.
This requires transforming the data into a vector space, where each data point is represented as a vector in high-dimensional space. However, this transformation is not without its challenges, as various methods exist, each with their own pros and cons.
Methods for Transforming Data
Handcrafted Features: One early approach to transforming data into vector space involves extracting handcrafted features, such as color histograms, texture descriptors, and shape descriptors. While these features can be effective in certain situations, they are often specific to the application and may not generalize well to other problems. Additionally, designing and extracting these features is labor-intensive and time-consuming.
Principal Component Analysis (PCA)
PCA is a widely-used linear dimensionality reduction technique that projects the data onto a lower-dimensional subspace while preserving the maximum amount of variance. Although PCA can reduce dimensionality, it makes the assumption that the data lies on a linear subspace, which may not always hold true for complex computer vision tasks.
Autoencoders
Autoencoders are unsupervised neural networks that learn to encode input data into a lower-dimensional representation and then decode it back to the original input. They can capture non-linear relationships in the data, making them more versatile than PCA. However, training autoencoders can be computationally expensive, and the quality of the learned embeddings is highly dependent on the architecture and hyperparameters used.
Convolutional Neural Networks (CNNs)
CNNs have shown remarkable success in computer vision tasks, and the activations in the intermediate layers can be used as embeddings. These embeddings often capture hierarchical and spatial information about the input data. Nevertheless, training deep CNNs can be resource-intensive, and the embeddings may be sensitive to small perturbations in the input data.
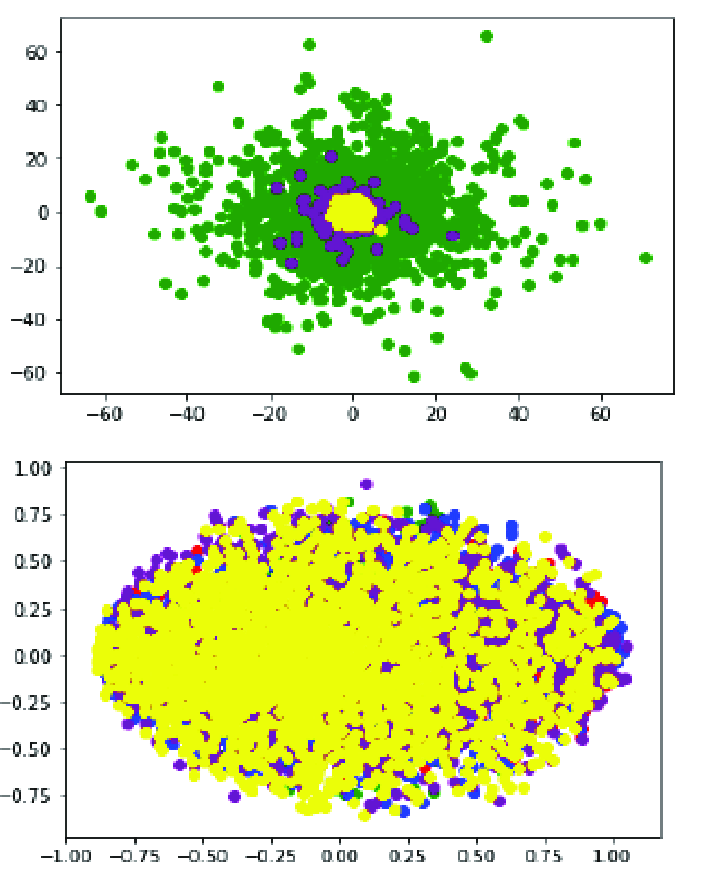
A representation (Principal Component Analysis) PCA for dimensional reduction.
Reducing Dimensionality While Retaining Essential Information
The goal of using embeddings in computer vision data curation is to reduce the dimensionality of the data while retaining the most important information. This enables models to process and learn from the data more efficiently.
To achieve this, an ideal embedding should preserve the relationships between data points and be robust to noise and small variations in the input data. Additionally, it should be computationally efficient to generate and use these embeddings, both during training and inference.
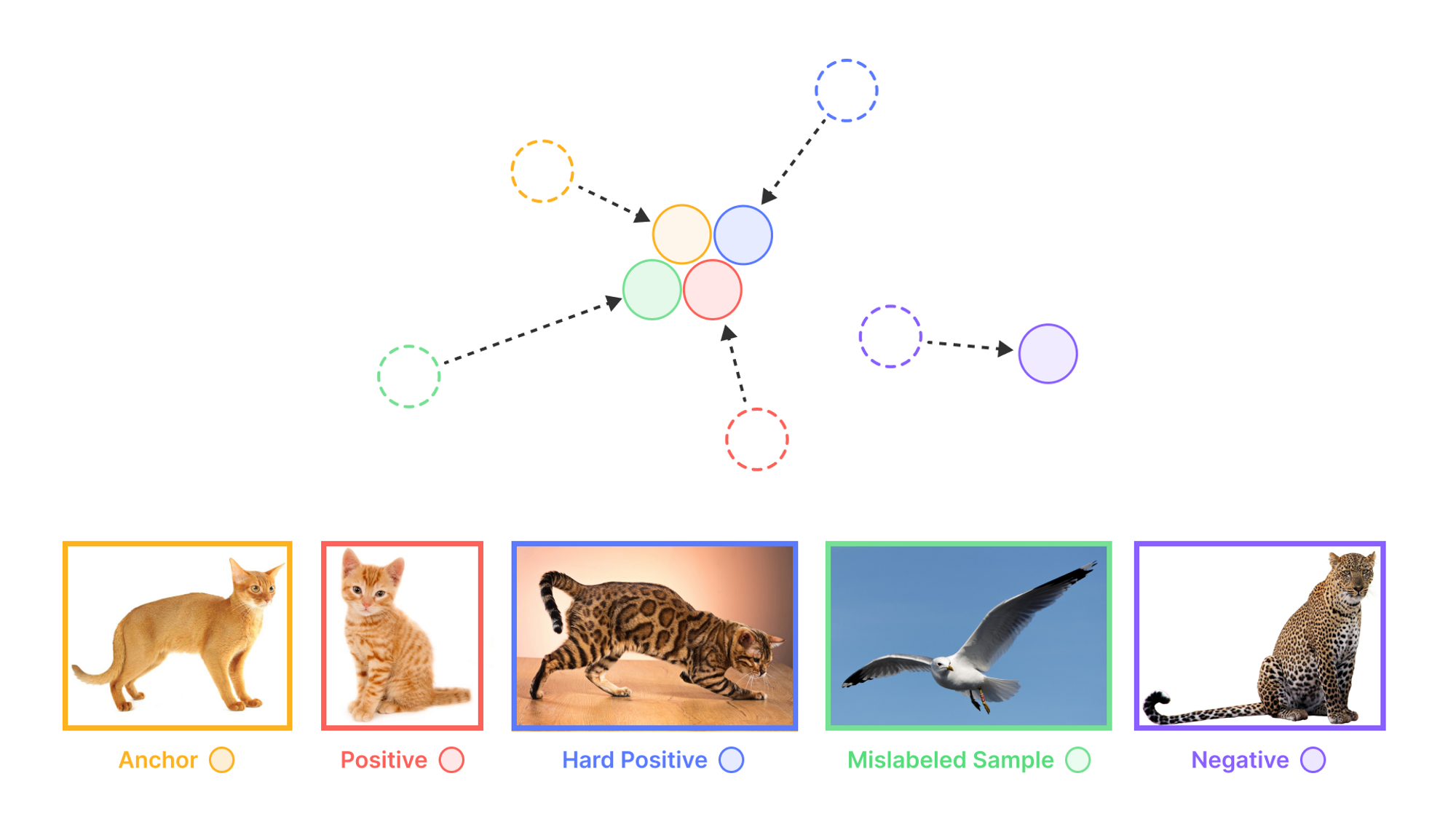
The Challenges of Transforming Data for Computer Vision Models
Transforming unstructured data into a form that machine learning or computer vision models can effectively process is a central challenge in generating embeddings for computer vision data curation.
This involves converting data into a vector space, where each data point is represented as a high-dimensional vector. Despite the variety of available methods, each with their own pros and cons, several common difficulties persist in this transformation process.
Variability in Image Data
Image data can exhibit a wide range of variations, including changes in scale, rotation, illumination, and occlusion. These factors can significantly impact the effectiveness of embeddings, as they need to be invariant or robust to such changes to ensure a model's performance. Designing methods that can consistently capture the most critical features while ignoring these variations remains a challenging task.
High-Dimensional Data
Image data is inherently high-dimensional, with each pixel contributing to the data's dimensionality. This can lead to the "curse of dimensionality," where traditional machine learning techniques struggle to perform well as the data's dimensionality increases. Generating embeddings that reduce dimensionality while preserving essential information can be difficult, as the technique must strike a balance between data compression and retaining meaningful features.
Noise and Outliers
Real-world image data is often noisy, containing artifacts, sensor noise, and other unwanted elements. Moreover, it can include outliers that deviate from the expected pattern. Transforming data into a vector space requires developing techniques that can handle noise and outliers effectively, ensuring that the generated embeddings remain useful and robust.
Labeling and Annotation
Challenges One key aspect of data curation is the labeling and annotation of images. In many cases, generating useful embeddings depends on the availability of high-quality labeled data. However, acquiring accurate annotations for large datasets can be labor-intensive, expensive, and time-consuming. Furthermore, ambiguities in the labeling process can introduce inconsistencies that negatively impact the generated embeddings' effectiveness.
Scalability and Computational Complexity
As the volume of image data continues to grow, scalability becomes an essential factor in generating embeddings. The transformation methods must be computationally efficient and scalable to handle massive datasets while maintaining acceptable processing times.
This can be challenging, as many of the existing methods have high computational complexity, which can be resource-intensive and limiting, especially for deep CNNs and autoencoders.
Simplifying the Use of Embeddings for Balanced Distribution
Despite the challenges associated with generating embeddings for computer vision data curation, researchers and practitioners have developed several methods to simplify the process and enhance their utility. These methods aim to improve data analysis and facilitate the creation of balanced distributions within training datasets, ultimately leading to better-performing models.
Pre-trained Embeddings
One way to simplify the use of embeddings is to leverage pre-trained embeddings that have already been trained on large-scale datasets. These embeddings can capture general features of the data and provide a good starting point for various computer vision tasks.
By utilizing pre-trained embeddings, practitioners can save time and resources that would otherwise be spent on training embeddings from scratch. Some popular pre-trained embeddings include those from models such as VGG, ResNet, and Inception.
Transfer Learning
Transfer learning is another method that helps simplify the use of embeddings. In transfer learning, a model pretrained on a source task is fine-tuned for a target task, leveraging the features and embeddings learned during the pre-training phase. This approach can be highly beneficial, especially when dealing with smaller or domain-specific datasets, as it allows practitioners to take advantage of the knowledge captured in the pre-trained embeddings and adapt it to their specific tasks.
Dimensionality Reduction Techniques
Dimensionality reduction techniques such as t-Distributed Stochastic Neighbor Embedding (t-SNE) and Uniform Manifold Approximation and Projection (UMAP) can be applied to embeddings to visualize high-dimensional data in a lower-dimensional space. These techniques make it easier to analyze and explore the structure of the data, allowing practitioners to identify patterns, clusters, and outliers that can inform their data curation process.
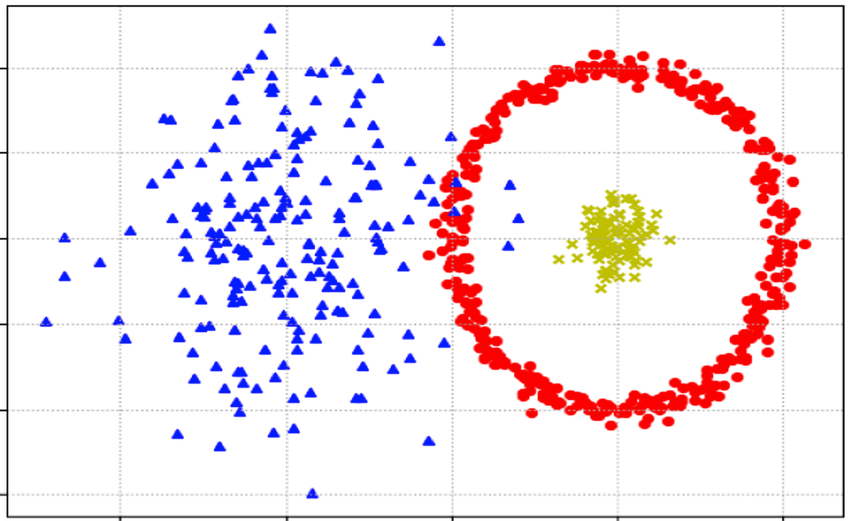
Active Learning
Active learning is a strategy that involves iteratively selecting the most informative data points from a pool of unlabeled data to be labeled and added to the training dataset. By using embeddings to represent the data, active learning algorithms can effectively identify and prioritize the most informative samples, ensuring a more balanced and diverse distribution in the training dataset. This approach can lead to improved model performance with fewer labeled samples, reducing the burden of manual labeling and annotation.
Data Augmentation
Data augmentation is another technique that can help create balanced training datasets. By applying transformations such as rotation, scaling, flipping, and color perturbations to the input data, practitioners can generate additional synthetic samples that share the same embeddings as the original data points. This process can help balance the distribution of the training data and increase the robustness of the model to variations in the input data.
A concept framework image depicting the factors of data quality
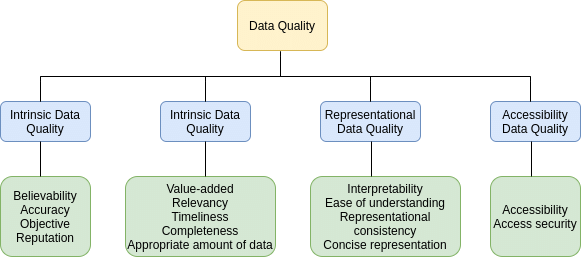
Introducing Superb: Analyzing Embeddings with Metadata and Queries
Superb Curate is a cutting-edge product designed to help machine learning and computer vision teams analyze training datasets, search the dataset based on metadata using queries, and visualize data distribution in 2D space. It streamlines the data curation process by selecting data that is common and representative, while also taking into consideration class balance and feature balance.
By choosing sparse and distinct data points that may be edge cases, Superb Curate enables teams to further train their models for higher performance and accuracy. Additionally, it can help identify mislabeled data in a dataset and suggest errors that need to be fixed and added to the training set.
This innovative solution saves labeling costs and time for machine learning and computer vision teams, making it an essential tool for any organization working with complex computer vision tasks.
Key Features of Superb Curate:
Analyze training datasets
Superb Curate simplifies the analysis of embeddings, allowing teams to better understand the underlying structure of their data and make informed decisions about data curation and model training.
Metadata and queries
By incorporating metadata and enabling users to search the dataset using queries, Superb Curate offers a more comprehensive understanding of the relationships between data points and their properties.
Visualize data distribution in 2D space
With the ability to project embeddings into a two-dimensional space, users can easily visualize the distribution of their training data, identify rare and valuable data points, and improve their model's performance.
Class balance and feature balance
Superb Curate ensures that curated datasets are balanced in terms of class representation and feature diversity, leading to more robust and accurate computer vision models. Identification of mislabeled data: By detecting mislabeled data points, Superb Curate helps teams fix errors in their datasets, ensuring that models are trained on accurate and high-quality data.
Save time and labeling costs
By streamlining the data curation process and reducing the need for manual intervention, Superb Curate saves both time and resources, allowing teams to focus on developing and refining their computer vision models.
A Simpler Way to Visualize Data
Generating embeddings for computer vision data curation is a complex and critical task that requires efficient solutions to overcome its challenges. By transforming data into a vector space and reducing its dimensionality while retaining essential information, embeddings serve as the foundation for the efficient analysis, organization, and curation of image data.
A variety of methods and innovative tools, such as Superb Curate, are being developed to assist in this process, with each offering unique advantages and drawbacks. As we have discussed, the effective utilization of embeddings, metadata, and queries can significantly improve the data curation process, while visualizing data distribution in 2D space can offer valuable insights to optimize model performance.
Moreover, the importance of a well-balanced validation set cannot be overstated. Ensuring that the validation set closely matches the model's real-world environment is vital for accurately testing and predicting model performance in specific environments.
By leveraging advanced solutions like Superb Curate and other cutting-edge approaches, engineers and data scientists can continue to refine their computer vision models and harness the true potential of this rapidly evolving field.
The Ground Truth is a community newsletter featuring computer vision news, research, learning resources, MLOps, best practices, events, podcasts, and much more. Read The Ground Truth now.