Insight
What Are Image Embeddings for Computer Vision Data Curation?

2023/05/03 | 4 min read
Humans have an innate aptitude to perceive small differences in the things that surround them, which machine learning (ML) and computer vision (CV) developers strive to replicate in their models. This ambition also brings about an obvious question: how do you teach a machine to discern the objects in its environment accurately? Like most related to achieving any degree of consistent performance in neural networks or ML models, the answer is in the data it was trained with.
Achieving optimal results from the average model can require a substantial amount of data; this can involve labeling hundreds or thousands of examples per class, depending on the intended algorithm; as any sophisticated model, designed with the goal of interpreting the complex relationships between input and output attributes - the more specific and comprehensive its training data needs to be.
Fortunately, there's a tailor-made solution for precisely this purpose, delivering the necessary volume and domain-specific variety of data a custom deep learning model depends on: embeddings, also known as vectors, which, fundamentally, are an array of numbers (in the form of a numerical representation) that enable things like visual clustering and semantic similarity searches to be performed.
Through the myriad uses of vector embeddings, developers can compare and contrast the most meaningful and computationally efficient aspects of their data, ensuring that time is well spent curating for high-performance accuracy and plenty of room to scale.
We Will Cover:
- A briefer on vector embeddings
- What it takes to build an embedding model
- How pre-trained embeddings models work
- The most common pre-trained embedding models
All About Vector Embeddings
When you consider the tall order of extracting value from a large amount of data, notably, the countless hours of tagging and labeling to get a model to work correctly, you start to appreciate all that embeddings have to offer:
By embedding input images into vector space and evaluating them from a visual similarity standpoint - ML teams can identify the data that a model has a good understanding of; versus where it's lacking - and focus training and validation efforts where it makes the most difference.
In a nutshell, vectors or embeddings act as an ideal data structure for processing machine learning algorithms. Since models can't make sense of data independently, it needs to be converted to a format they can intake. That go-to format is typically numbered values that signify a point in embedding space (for example, the value: 0, 0, 0), with some being closer in proximity and others being far apart.
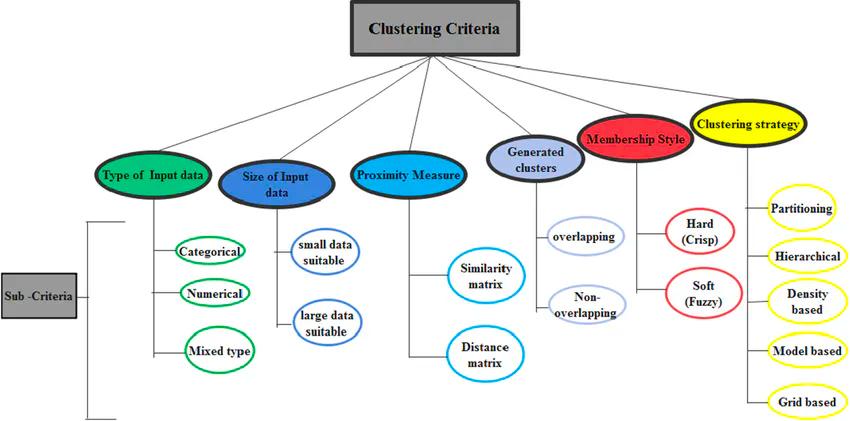
A decision tree diagram of major criteria and sub-criteria for classifying clustering algorithms.
These points may be clustered but are just as likely to be sparsely distributed. It's also worth mentioning that vector embedding, as a technique, allows for taking any form of data; word, image, audio, video, and creating a vector representation of them. However, that doesn't necessarily mean data is converted into vectors just like that.
ML practitioners will want to be sure that tasks can be performed on the transformed data without it losing its original meaning. The data should be compared based on relationships and meaningful similarities. As a common solution, many developers would use an embedding model to establish that deeper meaning and association.
Building an Embedding Model
Embedding models are made much like any other model, using a good amount of labeled data to train a neural network. Following the usual procedure, any ML team interested in utilizing embeddings is left to the job of personally building them. With a backlog of time-consuming manual curation work, this can take a toll on any organization.
Creating Embeddings From Scratch
If developers decide to build an embedding model in-house, they have the option of applying supervised learning; feeding the neural network a considerable amount of training data made up of input and output pairs, or the alternatives of self-supervised and unsupervised learning, with both not requiring labeled outputs.
Semantic Similarity
Any effective embedding model should be capable of capturing semantics through input data; with semantically similar data having closer embeddings, while the dissimilar uses distance embeddings. With a vector describing the contents of an image, for example, in the case of an image of a computer, the first coordinate might represent the color, the second might be the shape of the object and the last a defining characteristic like the logo or significant branding feature.
In other words, through semantic search (that focus on answering a question posed that's related to grouping or organizing images by similarity, such as what objects are contained in which images), machines are able to mimic the human ability to understand the differences of similarities between images, text, sound, or videos, with vector embeddings at their core as a data structure.
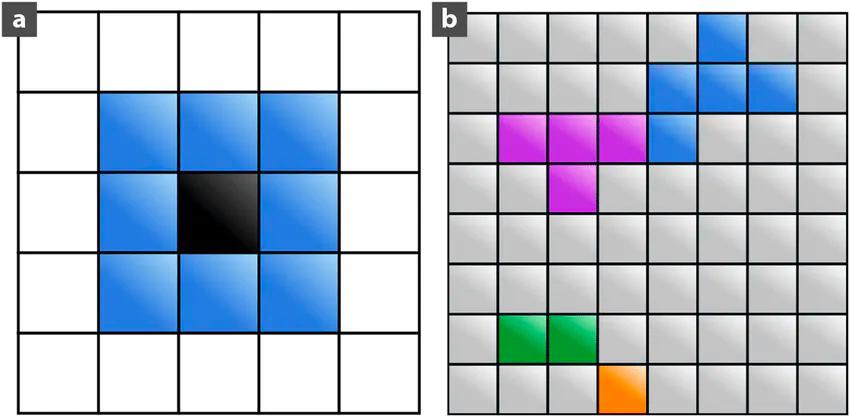
Figure 1. A schematic representation of clusters spatially neighboring.
Indexing Embeddings
When a traditional CV application is developed, data structures are represented as objects that are sourced or stored in a database or index. Conveniently, embeddings can be computed for each data object that is added or uploaded to that database or index, which practitioners can quickly search and use to locate the closest vectors for their chosen queries.
The objects stored in an index have properties (also described as columns) that should be relevant to the application being build. Gradually, the number of properties of these objects should grow - to the point where development teams should be more intentional about which properties are needed to complete target tasks.
Attaching Identifiers
With an effective embedding model, users can abstract the most valuable information within image data, reduce its size, and easily compare it. Beyond extracting features from data and comparing them, the image data vectors should be combined with other identifiers like color, object class, format, and many others depending on the image contents or subject matter.
See also: How To Best Manage Raw Data for Computer Vision
Refine your datasets with training and validation precision in mind. Book an exclusive demo with our team today to find out what auto-generated embeddings can offer your data curation workflow.
Matching Embeddings to Use Cases
The objective of developing an embedding model is to glean as much semantic insight from a dataset as possible, then transfer it to a use case like object recognition, classification, localization, etc. Achieving that feat takes the time and expense of pre-training a neural network to learn semantically-meaningful and dense vector representations of images. This preliminary process also depends on the domain-specific pre-training layers that may become necessary during the process.
Pre-Trained Embedding Models
On a fundamental level, pre-trained models are a network that was previously or once used on a large-scale dataset and typically for an image classification task. The pre-trained model can be used or adopted as is for an ML team's embedding needs or to employ transfer learning to customize the model to a specific task.
The main point behind the use of transfer learning for image classification is that, theoretically, if a model is trained on a large and general enough dataset - it should serve as generic and offer learned feature maps without practitioners needing to build and train their own large model (which requires an equally large dataset), from the ground up.
There are two distinct and popular methods for customizing a pre-trained model:
Feature Extraction: Utilizes representations that were learned by a previous network to extract meaningful features from new samples. A new classifier will need to be added, which will be trained from scratch using the pre-trained model to repurpose the feature maps previously learned for the dataset.
Through this method, an entire model does need to be retrained. The base CNN should already contain the generic features that are useful for classifying images. There is a caveat to this approach, however, development teams should take note that the final phase of classifying for the pre-trained model remains specific to its original classification task, along with the set of classes on which it was trained.
Fine-Tuning: With this method, ML practitioners will need to unfreeze a number of top layers of a model base and train both the newly-added classifier layers and the last few layers of the base model. This enables the "fine-tuning" of higher-order feature representations in a base model to gear them towards executing a specific task.
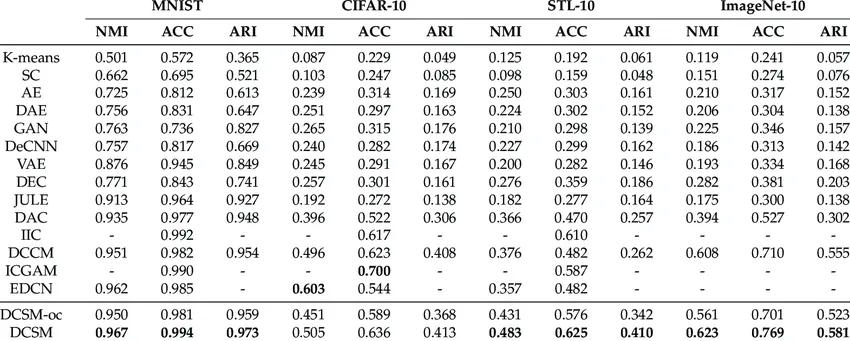
A table displaying the clustering performance of different methods on four different datasets.
From a high overview perspective, practitioners will follow the main steps of a machine learning workflow.
- Examine and thoroughly understand the data.
- Build an input pipeline using the data.
- Load the pre-trained model with its pre-trained weights.
- Stack classification layers on top of the pre-trained model.
- Train the pre-trained model.
- Evaluate the pre-trained model.
There are also the essential phases and scenarios ML teams should be prepared to undergo:
- Data preprocessing by downloading the dataset or loading it.
- Creating a test set using a pre-loaded dataset and determining the data batches available in a validation set before moving them to the test set.
- Configuring the dataset for performance.
- Implementing data augmentation if there isn't a suitable amount of data available.
- Feature extraction by freezing the convolution base and using it as a feature extractor.
- Compiling and training the pre-trained model, then applying fine-tuning measures in consideration of accuracy and loss discrepancies between the training and validation sets.
Superb Curate
Common Pre-Trained Embedding Models
Below are listed three standout choices for pre-existing CV models that are often used for image classifying tasks.
- VGG-16Earning its top-of-the-list status, this model is one of the most widely used for image classification tasks. Its position was cemented after beating out the once industry-standard, AlexNet. VGG-16 is composed of 13 convolutional layers, 5 pooling layers and 3 dense layers. It's sequential in function and utilizes a number of filters. At each stage, small 3x3 filters are used to reduce the parameters of hidden layers. Which makes it a significantly slower and larger model to train than others.
- Inceptionv3At 7 million parameters, Inception is smaller than a prevalent model such as VGG or AlexNet and boasts a lower error rate. It's also well regarded for its Inception module capabilities. Essentially, the module is capable of performing convolutions with different filter sizes on the input, Max pooling, and concatenating the result for the next module. Though it has 22 layers, the overall reduction in parameters through a 1x1 convolution operation makes it tough to beat as a contending model on this list.
- ResNet50The main development goal behind ResNet50 was to avoid poor accuracy. By aiming to tackle the issue of vanishing gradient, this pre-trained model bypasses or skips a layer after 2 convolutions. These skipped convolutions are referred to as "identity shortcut connections" and use residual blocks. The concept behind this feature is based on the proposal that fitting a residual mapping is easier than fitting actual mapping and applying it in all layers. For that reason, rather than stacking layers as VGG-16 and Inception do, ResNet50 simply changes the underlying mapping.
- EfficientNetOrchestrated and backed by Google developers, EfficientNet introduced a new scaling method known as compound scaling. This new method steered from the conventional approach of arbitrarily scaling dimensions and by adding multiple layers. Through a demonstrative effort through EfficientNet, it's claimed that by scaling dimensions by a fixed amount simultaneously, practitioners can achieve higher performance.
Embedding-based Curation
The undertaking of collecting enough raw data to train a model, not to mention curating that data to be suitable for semantic comparison is daunting for any ML team to take on. This challenge served as the basis for Superb AI's embedding-based auto-curation product, Superb Curate.
Using embeddings as a foundational technology, the product enables an AI model to compare the visual similarities between images in a database, like background, color, composition angle, etc, and effectively comprehend them.
With embeddings serving as a solid base to support AI-powered features, the following tasks can be adopted and simplified for any domain-specific ML or CV project:
- Curating an unstructured dataset with even distribution and achieving minimal redundancy.
- Developing a well-balanced dataset of labeled images that have an equal representation of classes and distribution of objects within each class.
- Grouping data within datasets according to similarity (or clustering) and curating the images that are identified as rare or those predicted by the AI model to have a higher likelihood of being edge cases.
- Targeted curation of common images or more likely to be repetitive or redundant.
The auto-curation tools provided to Superb AI platform users resolve the two most time-constraining performance issues that plague designing responsive model builds; the first, curating the most domain-relevant and performance-reliant segments of a dataset to lead the way in achieving effective training and validation, and secondly, providing an alternative solution to the two conventional options of achieving balanced datasets, using a pre-trained embedding model or going to the trouble of creating a custom one.
Related Posts

Insight
How to Restart an AI Project That Stalled for Lack of Data—with Just 10 Images

Hyun Kim
Co-Founder & CEO | 7 min read

Insight
Three Years of the Few-Shot Object Detection Challenge: Mapping the Global Vision AI Landscape
Hyun Kim
Co-Founder & CEO | 7 min read

Insight
⑪ Germany's Physical AI Moment: Siemens, BMW, and the Robot Unicorn Counteroffensive
Hyun Kim
Co-Founder & CEO | 15 min read

About Superb AI
Superb AI is an enterprise-level training data platform that is reinventing the way ML teams manage and deliver training data within organizations. Launched in 2018, the Superb AI Suite provides a unique blend of automation, collaboration and plug-and-play modularity, helping teams drastically reduce the time it takes to prepare high quality training datasets. If you want to experience the transformation, sign up for free today.